**使用SPL高效实现Flink SLS Connector下推**
背景
日志服务SLS是云原生观测与分析平台,为Log、Metric、Trace等数据提供大规模、低成本、实时的平台化服务,基于日志服务的便捷的数据接入能力,可以将系统日志、业务日志等接入SLS进行存储、分析;阿里云Flink是阿里云基于Apache Flink构建的大数据分析平台,在实时数据分析、风控检测等场景应用广泛。阿里云Flink原生支持阿里云日志服务SLS的Connector,可以在阿里云Flink平台将SLS作为源表或者结果表使用。
在阿里云Flink配置SLS作为源表时,默认会消费SLS的Logstore数据进行动态表的构建,在消费的过程中,可以指定起始时间点,消费的数据也是指定时间点以后的全量数据;在特定场景中,往往只需要对某类特征的日志或者日志的某些字段进行分析处理,此类需求可以通过Flink SQL的WHERE和SELECT完成,这样做有两个问题:1. Connector 从源头拉取了过多不必要的数据行或者数据列造成了网络的开销,2. 这些不必要的数据需要在Flink中进行过滤投影计算,这些清洗工作并不是数据分析的关注的重点,造成了计算的浪费;对于这种场景,有没有更好的办法呢?
答案是肯定的,SLS 推出了SPL语言,可以高效的对日志数据的清洗,加工。这种能力也集成在了日志消费场景,包括阿里云Flink中SLS Connector,通过配置SLS SPL即可实现对数据的清洗规则,在减少网络传输的数据量的同时,也可以减少Flink端计算消耗。
接下来对SPL及SPL在阿里云Flink SLS Connector中应用进行介绍及举例。
**SLS SPL介绍**
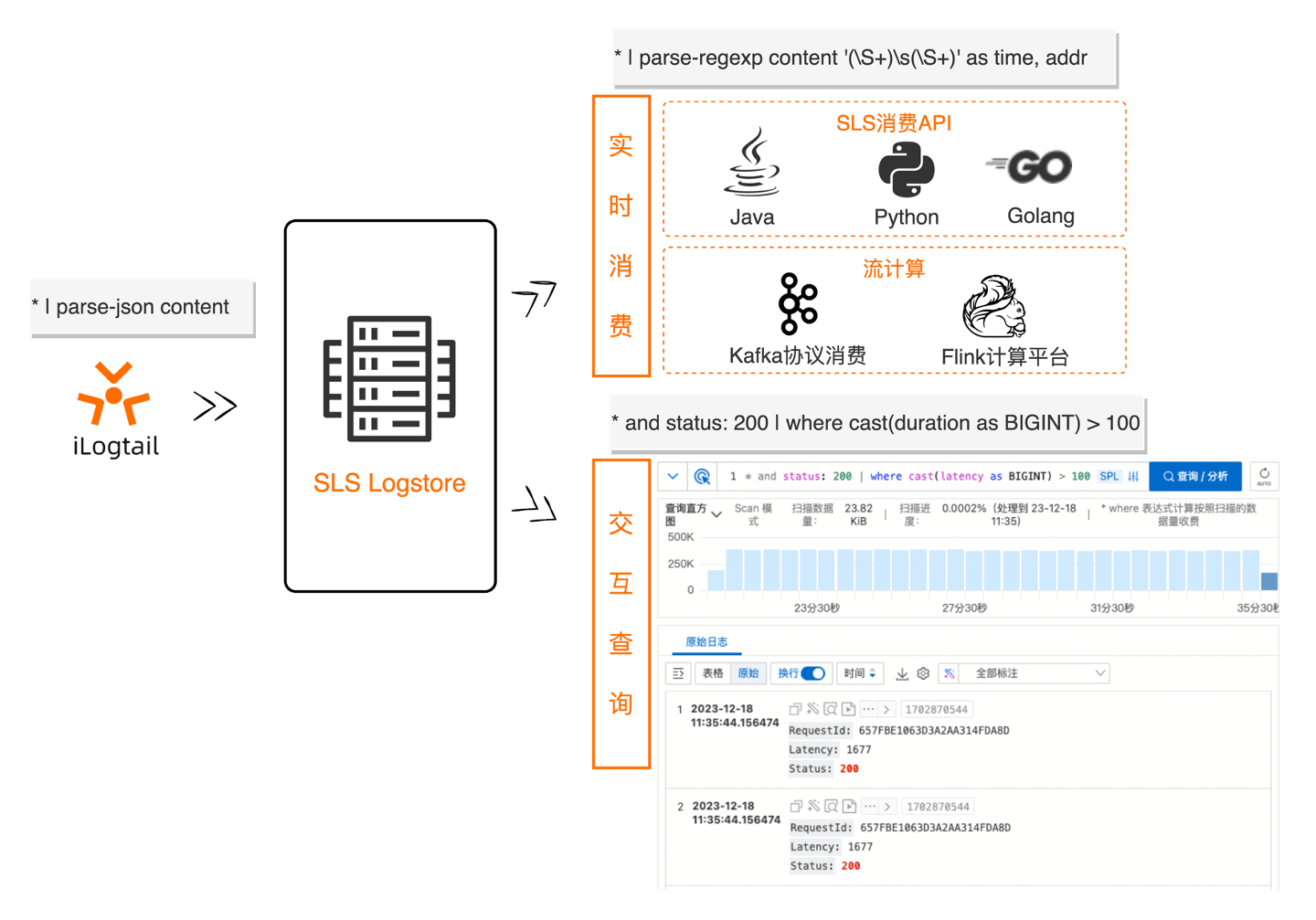
SLS SPL是日志服务推出的一款针对弱结构化的高性能日志处理语言,可以同时在Logtail端、查询扫描、流式消费场景使用,具有交互式、探索式、使用简洁等特点;
SPL基本语法如下:
| -option=