**多云选择下的数据融合困境**
为了支持全球战略,现代企业往往采用多个云产品服务商,以规避依赖单一服务提供商可能带来的业务风险,并增强企业的议价能力和灵活性。因此,它们的业务日志通常存储在多个云提供商的文件系统中。为实现对业务数据的统一观测,企业需要整合多云环境中的数据。这一整合过程会带来一些挑战:
- 新文件不能及时发现
云文件系统提供商通常仅提供 Bucket 遍历接口,却缺乏按时间顺序遍历新增文件的功能。因此,当单个 Bucket 中的文件数量超过亿级时,如何高效识别新增文件而不显著延长后续流程时间,是多云文件数据整合开发人员面临的首要挑战。
- 需要弹性扩缩容
企业业务量往往会呈周期性波动,相应地,日志产生量也随之变化。在业务高峰和低谷期,日志文件规模可能存在显著差异。若无法实现资源的弹性扩缩容,将不可避免地导致以下问题:
- 在业务低谷期,造成资源浪费;
- 在业务高峰期,增加日志可见性延迟。
- 数据解析复杂:
在多云环境中,不同业务或同一业务跨云部署时,日志字段和存储格式往往存在差异,需要进行统一转换和适配。
阿里云日志服务(SLS)是一个云原生观测与分析平台,为日志(Log)、指标(Metric)和追踪(Trace)等多种数据类型提供大规模、低成本、实时的一站式服务。SLS推出的对象导入功能通过创新的文件发现方法和优化的整体架构,实现了高性能、易用的多云文件数据导入能力,有效简化了跨云数据融合流程。
**为什么是SLS对象导入?**
对象导入架构概览
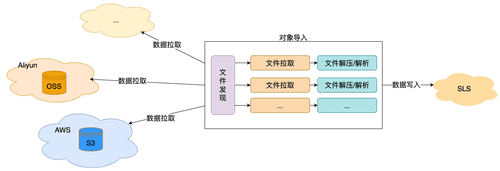
为应对多云数据导入的挑战,阿里云日志服务(SLS)团队经过深入调研和精心设计,采用了新的两阶段并行处理架构。这一架构将文件发现和数据拉取分离,实现了以下优势:
- 文件发现:采用多元化的智能文件发现策略,在确保数据完整性的同时,高效识别和捕获文件变动。
- 数据拉取:独立于文件发现过程,专注于高速数据传输。
- 并行执行:两个阶段同时进行,互不干扰,最大化性能表现。
这种设计不仅克服了传统方法中文件发现可能成为性能瓶颈的问题,还显著提升了整体数据导入效率,为用户提供了更快速、可靠的多云数据整合解决方案。
如何在亿级文件中快速发现新增文件?
为实现新文件的高效、及时发现,我们开发并实施了多元化的智能文件检测策略。这套综合方案包括以下部分:
- 定期遍历整个存储桶(bucket),作为可靠的基础保障机制,确保100%的文件覆盖率,杜绝遗漏
- 增量bucekt文件遍历,确保按照字典序增序新增文件的场景下,新文件能够在一分钟内被发现
- 使用OSS元数据索引能力进行辅助,确保OSS文件导入场景下,新文件能够在一分钟内被发现
- 使用AWS SQS能力进行辅助,确保S3文件导入场景下,新文件能够在一分钟内被发现
这些文件发现方法共同构成了一个强大的生态系统,能够在各种云存储场景下快速、准确地识别新文件。一旦新文件被检测到,系统随即启动解析流程,进一步处理数据。
支持哪些格式的文件解析/解压?
- 支持解析的文件格式有:
单行文本日志、跨行文本日志、单行JSON、CSV,ORC、Parquet等,
- 支持的解压格式有:
zip、gzip、zstd、lz4、snappy、bzip2、defiate等。
如果业务突增怎么办呢?会不会带来延迟?
面对业务量的突然增长,您无需担心数据导入的延迟问题。阿里云日志服务(SLS)的对象导入功能采用了弹性扩缩技术,确保在各种负载情况下都能保持高效性能。
在发现新文件之后,会自动按照文件数量设置并发数,可快速扩展单任务使用的存储或计算资源,特别适合文件数量大但单个文件较小的场景。
支持哪些云厂商?
当前支持导入阿里云OSS以及AWS S3文件数据,后续将覆盖更多的云厂商。
基于SLS对象导入功能,用户无需开发适配,就能将多云的多种常见格式的文件导入到SLS中来,并且在bucket文件数小于百万,或者新增文件名按照字典序增序时,无需任何操作,就可以在三分钟内在SLS 的logstore中看到新增文件数据(排除公网网络质量较差情况)。接下来先具体实操感受一下吧。
**SLS对象导入实战**
**对象存储(OSS)数据集成**
接下来将以把OSS bucket中2025年4月创建的文件导入到sls的logstore中为例。
**数据准备**
待导入数据文件已经存储在OSS任意bucket中。
**创建OSS数据导入任务**
首先进行权限准备,参考导入OSS数据前提条件部分给使用的账号进行授权。
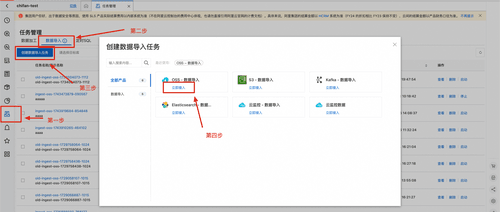
之后进入要导入数据的project中,通过任务管理开始创建OSS数据导入任务,按照下面提示依次点击:
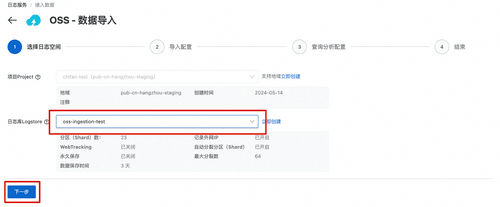
在任务创建界面选择目标logstore,这里选择oss-ingestion-test,之后点击下一步
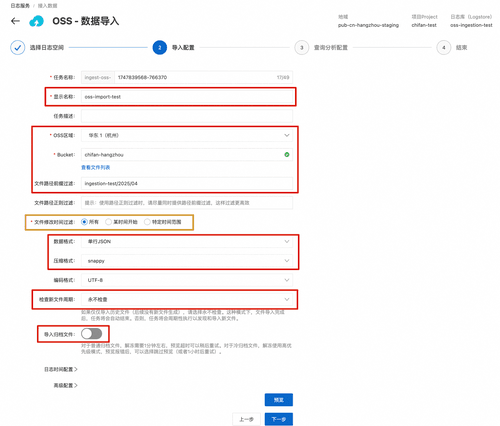
接下来进行具体的设置,按照下图中提示依次进行填写或选择。这里我们设置显示名称为:oss-import-test,该名称将显示在任务概览界面上。然后选择源数据bucket所在区域,这里我们选择杭州。之后下拉选择源bucket。由于我们只需要导入2025年4月的数据,所以我们可以给文件路径前缀写入具体的文件路径--ingestion-test/2025/04。这里就不需要额外地设置文件修改时间范围,直接导入所有就行。数据格式的设置需要根据具体文件数据来进行,如我们的数据是单行json,使用了snappy压缩。因为只需要一次性导入历史文件,这里检查周期选择永不检查即可,由于不涉及归档文件,这里没有打开该按钮。到这一步,我们就设置好了一个OSS数据导入任务,点击预览,即可看见该设置下数据导入的结果样例,如果符合需求,点击下一步即可创建任务,否则应该进行微调。
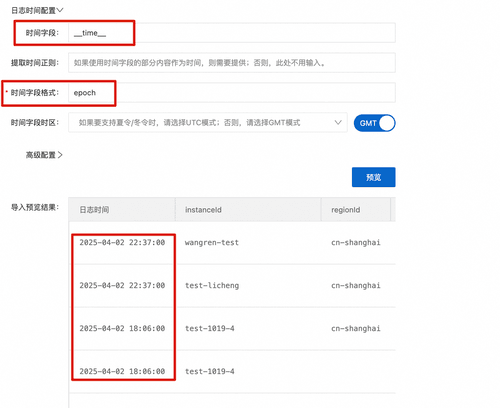
在上述场景下,当日志导入到sls时,日志的时间戳会记录为数据进入sls的时间点,有时这是不符合用户预期的,这就需要针对日志时间进行一些配置。如下图所示,我们数据中会有一个名为__time__的字段记录时间戳,样例为:1743604620,然后将时间字段格式设置为epoch,如果不知道应该怎么设置,可以参考时间格式。之后点击预览查看数据导入样例,如下图所示。最后点击下一步即可创建出OSS数据导入任务。
**查看任务状态及导入数据**
通过任务管理,按下图步骤检索到刚创建出来的任务,然后点击任务名称,即可进入任务概览界面,查看任务详细执行信息。
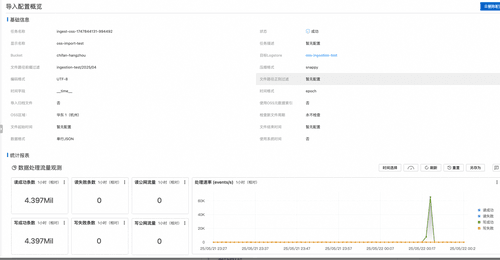
在任务概览界面可以看到任务的详细配置,以及运行状况。
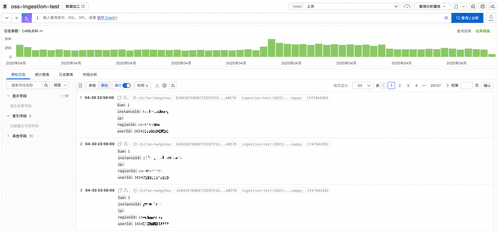
从任务概览界面点击目标logstore或者从左侧边栏点击logstore,进入logstore查看导入数据。最终导入结果如下图所示
**S3数据集成**
**数据准备**
待导入数据文件已经存储在S3任意bucket中。
**创建S3数据导入任务**
首先进行权限准备,参考导入Amazon S3文件前提条件给待使用的AK进行授权。
之后进入任务管理,按照下面提示依次点击,开始创建Amazon S3数据导入任务:
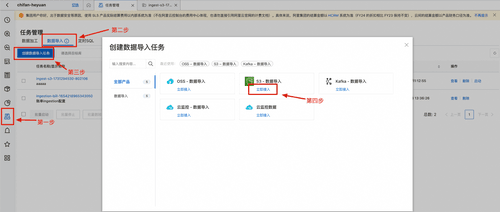
在任务创建界面选择目标logstore,这里选择s3-ingestion-test,之后点击下一步
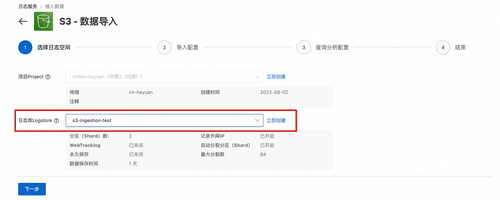
接下来进行具体的设置,按照下图中提示依次进行填写或选择。这里我们设置显示名称为:s3-import-test,该名称将显示在任务概览界面上。然后选择源数据bucket所在区域,这里我们选择ap-northeast-1。之后键入源bucket。之后需要依次渐入具有权限的AWS AccessKey ID以及AWS Secret AccessKey,用于拉文件数据使用。接下来,可以选择启用SQS或者不启用SQS,区别是使用sqs时,会从sqs中获取新增文件元信息,否则遍历s3 bucket来获取新增文件元信息,一般当bucket中文件数量超过100w,建议启用SQS,否则数据延迟将逐渐增加。在示例中,我们使用了SQS。接下来同样可以指定想要获取数据的文件路径前缀,以及设置文件路径正则来进行文件过滤。然后也可以通过设置文件修改时间过滤来指定要导入的文件时间范围。通过设置数据格式/压缩格式/编码格式来指导如何解析数据。
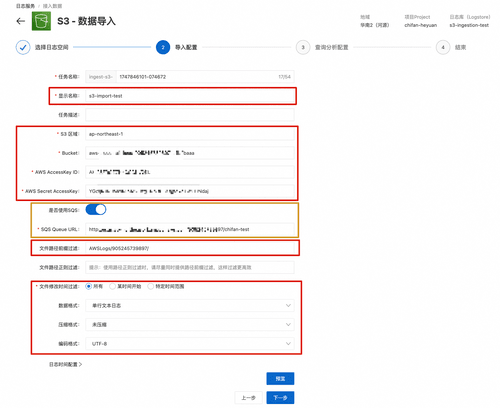
在上述配置都完成之后,点击预览来查看数据是否符合预期,如果不符合,则针对上面的配置进行修改,否则直接点击下一步即可创建出一个S3文件数据导入任务。
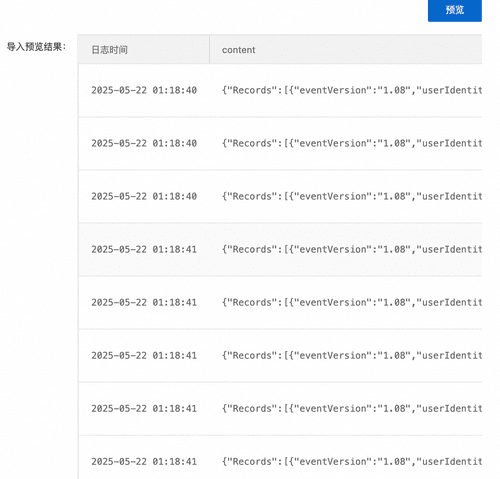
**查看任务状态及导入数据**
通过任务管理,按下图步骤检索到刚创建出来的任务,然后点击任务名称,即可进入任务概览界面,查看任务详细执行信息。
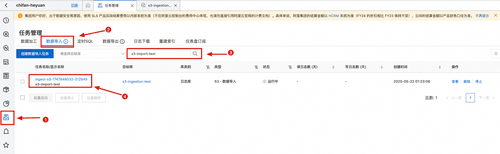
在任务概览界面可以看到任务的详细配置,以及运行状况。
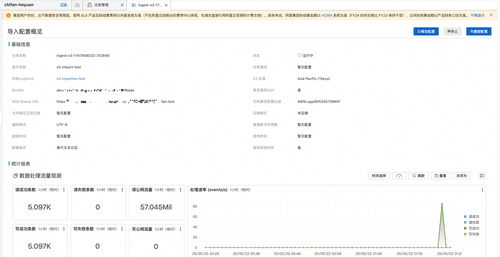
从任务概览界面点击目标logstore或者从左侧边栏点击logstore,进入logstore查看导入数据。最终导入结果如下图所示
**多云数据融合案例简析**
**跨云账单审计**
作为云产品使用厂商,除了业务自身之外,最关心的莫过于费用问题,而这些数据会同时散落在多个云厂商,使得用户难以统计。现在,用户可以先将账单数据导出到云厂商的文件系统中,然后再通过sls对象导入功能将这些账单数据导入到 SLS以进行进一步分析。
首先,需要把阿里云的账单日志投递到OSS,然后再通过对象导入功能从OSS将这些日志导入到SLS。其中,投递阿里云账单日志到OSS可以参考账单订阅,投递AWS账单日志到S3可以参考创建账单输出报告。接下来将简要分析用户在阿里云和亚马逊云上的账单信息作为示例来抛砖引玉。
- 在账单日志导入到sls之后,由于不同厂商字段存在差异,需要通过数据加工进行标准化,并为每条日志加上来源厂商。
* | project-rename product = line_item_product_code
| extend originProduct='aws'
| extend cost = pricing_public_on_demand_cost
| project product, cost, originProduct
* | project-rename product=ProductCode
| extend cost=PretaxGrossAmount
| extend originProduct='aliyun'
| project product, cost, originProduct
加工结果示例:

- 查看不同云厂商所有产品每天所需的费用。
SQL示例:
* | SELECT SUM(cost) AS cost, date_trunc('day', dt) AS dt, originProduct FROM (SELECT
SUM(CASE WHEN originProduct = 'aws' THEN cost * 7.19 ELSE cost END) AS cost,
date_parse(date, '%Y-%m-%d %H:%i:%S') AS dt,
originProduct
FROM log
WHERE
cost > 0
GROUP BY
dt,
originProduct )
GROUP BY dt, originProduct
查询结果示例:
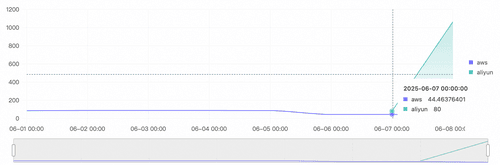
根据账单信息,我们可以看到业务增长情况,及时发现资源的不合理使用,判断是否需要裁撤,降低预期外的成本消耗。
- 查看单个产品费用增长趋势
* | SELECT SUM(cost) AS cost, date_trunc('day', dt) AS dt, product FROM (SELECT
SUM(CASE WHEN product = 'aws' THEN cost * 7.19 ELSE cost END) AS cost,
date_parse(date, '%Y-%m-%d %H:%i:%S') AS dt,
product FROM log
WHERE
cost > 0
GROUP BY
dt,
product )
GROUP BY dt, product LIMIT 10000000
查询结果示例:
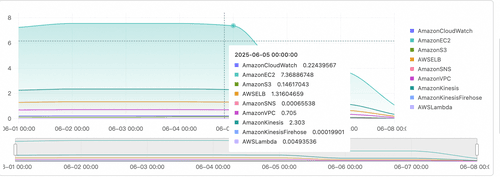
**跨云操作审计**
除了账单数据,对于资源的操作也是敏感行为,我们也可以通过sls对象导入功能来将不同云厂商的操作日志进行汇聚以进一步进行分析。接下来将以同时分析用户对于阿里云和亚马逊云上资源的操作作为示例来抛砖引玉。
首先,需要把阿里云操作审计日志投递到OSS,然后再通过对象导入功能从OSS将这些日志导入到SLS。其中,投递操作日志到OSS可以参考阿里云操作审计服务提供的将事件持续投递到指定服务。导入OSS文件数据参考上述实战内容即可。然后是把AWS操作审计日志投递到S3,再通过对象导入功能从S3将这些日志导入到SLS。其中,投递操作日志到S3可以参考 AWS CloudTrail提供的为AWS账户创建跟踪。接下来,分别将OSS中的日志和S3的日志按照上面实战步骤导入到SLS中来。最后,我们就能愉快地在SLS中对在两个云厂商资源的操作进行分析。
为了让数据更加简洁,首先将两个云厂商操作日志进行统一,对于AWS日志,因为CloudTrail会将多个日志放到同一个字段中,因此这里对日志进行了拆分,并标记成来自aws。
* | expand-values -path='$.Records' content as item
| parse-json item
| project-away item
| extend originProduct='aws'
加工示例如下:

同样,来自阿里云的操作日志也一视同仁,进行类似处理,加工语句如下:
* | parse-json event
| project-away event
| extend originProduct='aliyun'
接下来,针对这些操作日志进行一些查询分析。
- 查看所有产品每个小时的使用频次,查询语句如下:
* | SELECT COUNT(*) AS num, date_trunc('hour', __time__) AS dt, product GROUP BY dt, product LIMIT 100000000
在这里可以看到对于CMS的操作次数远大于其他产品。
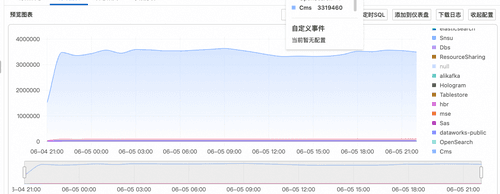
- 接下来进一步去看对于该产品的操作
* and product: Cms | SELECT COUNT(*) AS num, date_trunc('hour', __time__) AS dt, eventName GROUP BY dt, eventName LIMIT 100000000
可以看到,BatchExport的操作是最多的,进一步可以通过详细日志来看是哪个用户或者哪个任务一直在进行调用,并判断是否应该禁止。
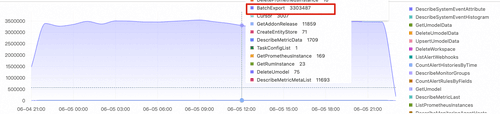
更进一步,接下来监控对云资源的敏感操作,并进行告警,以及时对我们进行提示。
- 设置查询语句监控资源删除事件
*| SELECT originProduct, eventName, eventId, userAgent WHERE eventName LIKE '%Delete%'
- 针对该事件设置告警
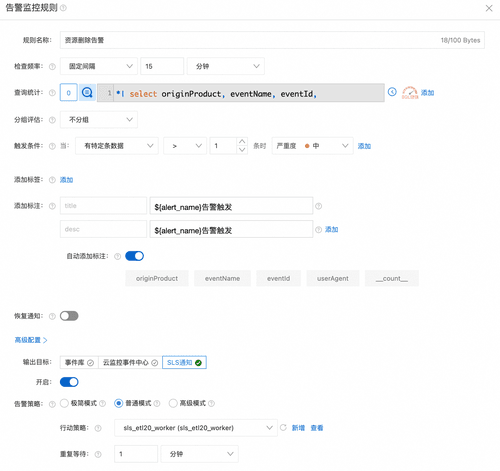
经过如此操作,无论资源在阿里云还是亚马逊云,只要它被删除了,就能给我们进行告警提示,以便能够及时感知并处理。
**更好地使用SLS对象导入**
- 公网费用太高?
- 使用zstd压缩
SLS对象导入功能免费,但使用公网时,会涉及流量费用,这时推荐先使用zstd压缩方式对文件进行压缩,之后再进行导入。 一般zstd压缩率为2x-5x,这里取中间值--3.5x,并以OSS公网费用为0.5元/GB为例,原始文件总共为100GB,走公网的情况下,原费用为50元,而压缩后,仅需要14.29元。
- 按字典序增序规则创建新文件
当bucket中文件超过百万时,为了不影响导入实时性,同时也不想启用三方服务,可以按照字典序增序规则创建新文件,在这一场景下, 能够确保文件在两分钟内被发现。
- 性能不佳?
- 使用小文件替换大文件
SLS最多为每个文件分配一个并发来进行数据拉取,针对相同数据量的文件,单个文件越小,可分配的并发数越大,从而使得整体文件导入速率越高。
- 按照业务将日志分目录存储
为了进一步提高文件导入的实时性,可以按照文件目录前缀来创建多个导入任务并发进行数据拉取。
- 其他注意事项
- 新增文件而不是追加
SLS对象导入功能会检测是否有文件新增或修改,然后导入这些文件,如果一直向同一个文件进行追加,会带来数据重复风险。
**结语**
SLS 对象导入功能旨在提供将多云数据统一导入到 SLS 的能力。通过多种新增文件识别技术加速数据导入,力求确保用户能够在三分钟内看到新文件数据。虽然当前支持范围仅限于 OSS 和 S3,不过我们正在不断进行功能升级,未来将支持更多更加复杂的场景中的数据导入,敬请期待。