**DeepWiki × LoongCollector:AI 重塑开源代码理解**
一、开源世界的痛点
当你第一次打开开源项目的源码,是不是经常遇到这样的场景:
- 面对庞大如山的代码,却苦于注释稀少、文档缺失?
- 在复杂的业务逻辑与陌生的库调用中挣扎,试图快速上手却如同无头苍蝇?
- 模块间错综复杂的依赖关系让人眼花缭乱,核心逻辑常被多重抽象层所遮蔽?
- 试图从头到尾研读源码?这不仅耗时费力,更可能在细节迷宫中迷失,难以把握系统脉络?
作为国产可观测领域的标杆采集器,LoongCollector(原iLogtail)凭借其卓越的性能表现与稳定性保障,已成为企业构建统一数据采集层的首选方案之一。然而,当开发者试图深入探索其高性能架构与稳定性机制时,往往会被复杂的框架设计与业务逻辑所困扰。根据 2024 年 LoongCollector 社区调研数据显示:尽管 66.67% 的开发者表达了参与社区开发的意愿,但"缺乏开发指引"(75%)与"方向不明"(33.33%)已成为制约社区贡献的核心障碍。
而在 AI 时代,代码解读正迎来范式革新。DeepWiki 作为 GitHub 公共代码仓库的智能文档生成神器,正在重新定义开发者与代码库的交互方式。这款由知名 AI 公司 Cognition AI(即研发出 AI 程序员 Devin 的团队)推出的工具,通过深度语义分析与交互式文档生成技术,为复杂代码库构建起智能导航系统。它不仅能自动解析项目结构、可视化模块依赖关系,还能将晦涩的业务逻辑转化为可交互的知识图谱,甚至能针对特定代码片段生成精准的注释文档。
**二、DeepWiki 为 LoongCollector 绘制全景技术地图**
DeepWiki 作为开源项目免费使用,无需注册。只需要将 LoongCollector 的 GitHub 链接(https://github.com/alibaba/LoongCollector)替换为 deepwiki.com 前缀即可访问。
**DeepWiki 技术原理探究**
DeepWiki 通过代码逻辑抽象、知识图谱构建与 AI 语义解析的结合,生成可交互的 Wiki 式文档。
- 层级化系统分解 :将代码库拆解为高阶系统结构(如模块、组件),建立清晰的逻辑框架。
- 结构化文档生成 :通过分析代码逻辑、依赖关系及配置文件,自动生成包含项目目标、核心模块、架构图的Wiki页面。
- 提交历史关联分析 :利用代码提交记录追溯功能演进与上下文关联,增强文档动态性与准确性。
- AI 驱动交互 :基于大型语言模型实现自然语言查询、代码逻辑解释及复杂算法简化,支持用户高效检索与理解。
**结构化文档破解代码迷局**
如果说传统的代码文档是“静态的说明书”,DeepWiki 的结构化文档则是一张“动态技术地图”。它通过 AI 语义分析,将 LoongCollector 的复杂架构转化为可交互的知识资产。
**项目全景概览**
DeepWiki 通过 AI 自动解析 LoongCollector 的系统架构,并以模块化架构图的形式呈现,帮助开发者掌握全局脉络。


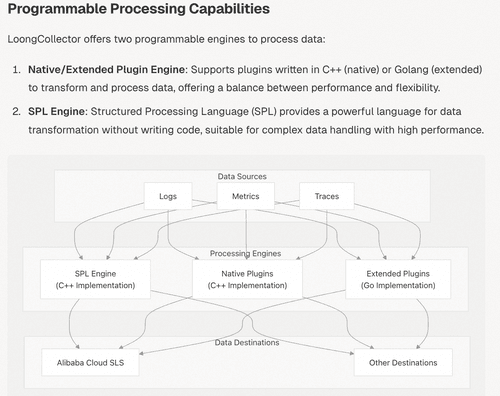
**核心模块深度解析**
以“可编程处理能力”为例,DeepWiki 清晰给出 LoongCollector 三大数据处理引擎以及数据链路关系。
**交互式流程图一目了然**
对于一些强流程、重交互的模块,DeepWiki 通过流程图的形式将复杂逻辑转化为可视化的分步图示,帮助开发者理清上下游关系以及交互流程。

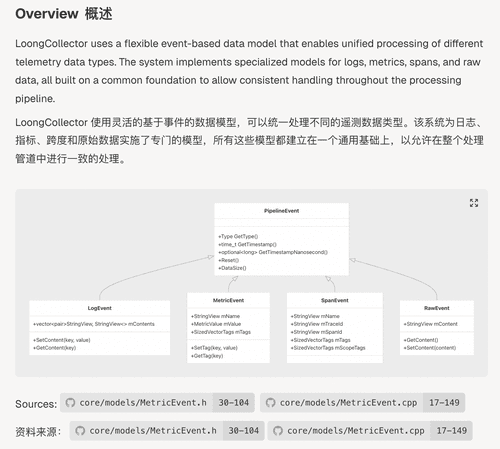
**关键数据结构清晰洞察**
掌握核心数据架构是学习开源软件源码的关键,但是初学者往往抓不住重点,无从下手。通过 DeepWiki 开发者可以轻松获取 LoongCollector 核心数据模型的类型与关系,有了基础数据模型的理解,学习更高层次的源码将事倍功半。
**AI 对话助手**
在浏览过程中,有任何不明白的地方,随时可以点击右下角的对话框,用中文向 AI 提问。

易混淆概念快问快答
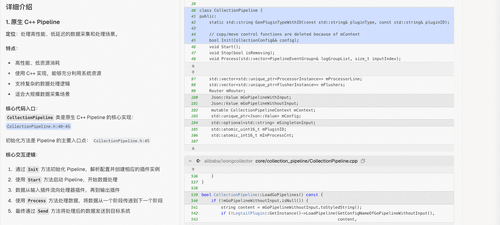
LoongCollector 内置多种 Pipeline,给初学者造成了混淆。开发者可以向 DeepWiki 提问寻求解答。
问:“LoongCollector 有几种数据 Pipeline,请按照总分关系介绍:各自的定位与特点是什么,并给出核心代码入口以及核心交互逻辑。”
DeepWiki 回答:

**核心数据结构深入探究**
LoongCollector 提供了 Go 语言插件的可扩展性,通过向 DeepWiki 提问,开发者可以了解更深层次的 C++/Go 交互原理。
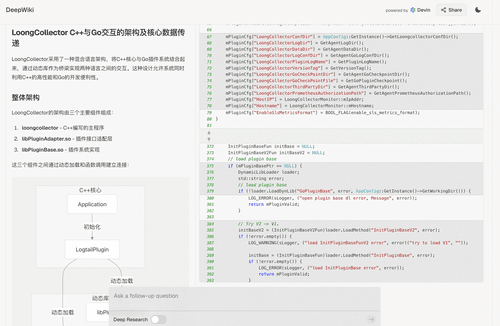
技术关键词精准捕获
LoongCollector 以高性能、低延迟著称,当你向 DeepWiki 询问探究技术原理的时候,DeepWiki 可以结合代码给出准确的解答。
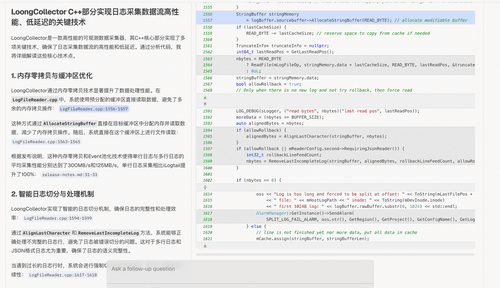
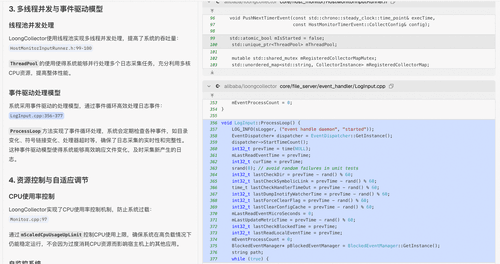
**三、开发场景实战演练**
前面章节展示了 DeepWiki 如何通过“结构化文档+智能问答”构建 LoongCollector 的知识体系,那么接下来将围绕开发者关心的一些技术问题进行实景演练。
**场景1:问题排查轻松搞定**
在 LoongCollector 社区 Discussions 的 Help 板块中,“数据发送延迟导致采集反压”已成为高频技术问题。
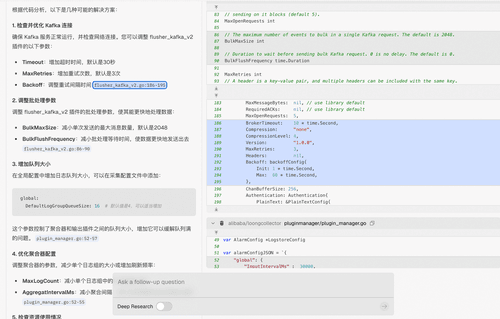
我们以 flusher_kafka_v2 插件为例,当开发者将日志采集至 Kafka 时,若遇到“AlarmType:AGGREGATOR_ADD_ALARMerror:loggroup queue is full” 报错,常引发性能瓶颈与数据丢失风险。针对此类场景,DeepWiki 通过多维度分析,从 队列配置、网络传输、资源竞争等角度系统性揭示反压成因,并提供可操作的解决方案。
问:“LoongCollector 使用 flusher_kafka_v2 插件采集日志到kafka,但是报错 AlarmType:AGGREGATOR_ADD_ALARMerror:loggroup queue is full。产生报错的原因是什么,应该如何解决?”
DeepWiki 首先针对问题原因给出解析:

之后,DeepWiki 给出的问题解决思路:
**场景2:源码学习路径制定**
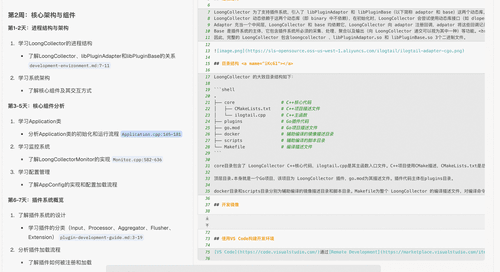
针对开源项目“入门难”的痛点,DeepWiki 通过“技能评估+模块分级+动态适配”三步法,为开发者构建由浅入深的学习路径。
问:个人技能:在学校学过C++课程,但是没有实际的开发经验。 我想学习 LoongCollector 源码,了解 LoongCollector 技术原理,但是不知道如何入手。请结合源代码,帮我制定一个为期 1 个月的 LoongCollector 源码学习计划。
DeepWiki 回答:
**场景3:寻求开发指导**
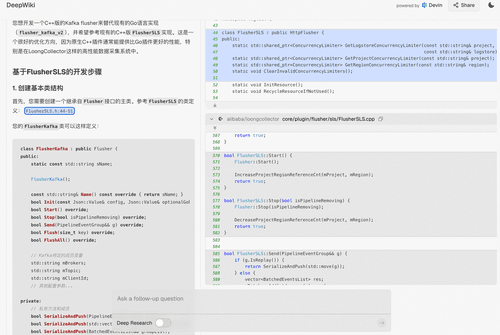
当你在 LoongCollector 项目中面对复杂架构、或模块依赖感到困惑时,DeepWiki 将成为最智能的开发伙伴。无论是设计新插件、优化核心逻辑,AI 助手都能通过交互式文档、动态代码分析与社区最佳实践推荐,为你构建清晰的开发路径。
问:现有的flusher_kafka_v2是Go语言实现,不是最优。我想开发一个C++版的Kafka flusher,请参考C++版的FlusherSLS,给出开发指导。
DeepWiki 回答:
**四、未来展望:**AI 重构开源协作范式
DeepWiki 通过“全景文档 + 智能问答 + 场景化演练”三位一体的解决方案,将 LoongCollector 的复杂性转化为可触摸的知识资产。开发者无需再“大海捞针”,而是借助 AI 助手精准定位技术路径,快速实现从学习到贡献的跃迁。
AI 给 LoongCollector 带来的不仅是代码解读的革命,更是开源协作范式的重新定义。