ARMS 切换到按量计费后,少部分用户反馈数据上报量偏大。也有用户尝试自行调整应用配置,但效果并不明显。本文将由浅入深,带你快速定位“数据量大”的主要来源,并给出一套更高效、可落地的降量方法。
一、先定位:到底是谁在“吃”掉用量?
在 ARMS 控制台的概览页进入用量统计,可以快速查看当前账号在不同 region 的数据上报情况。
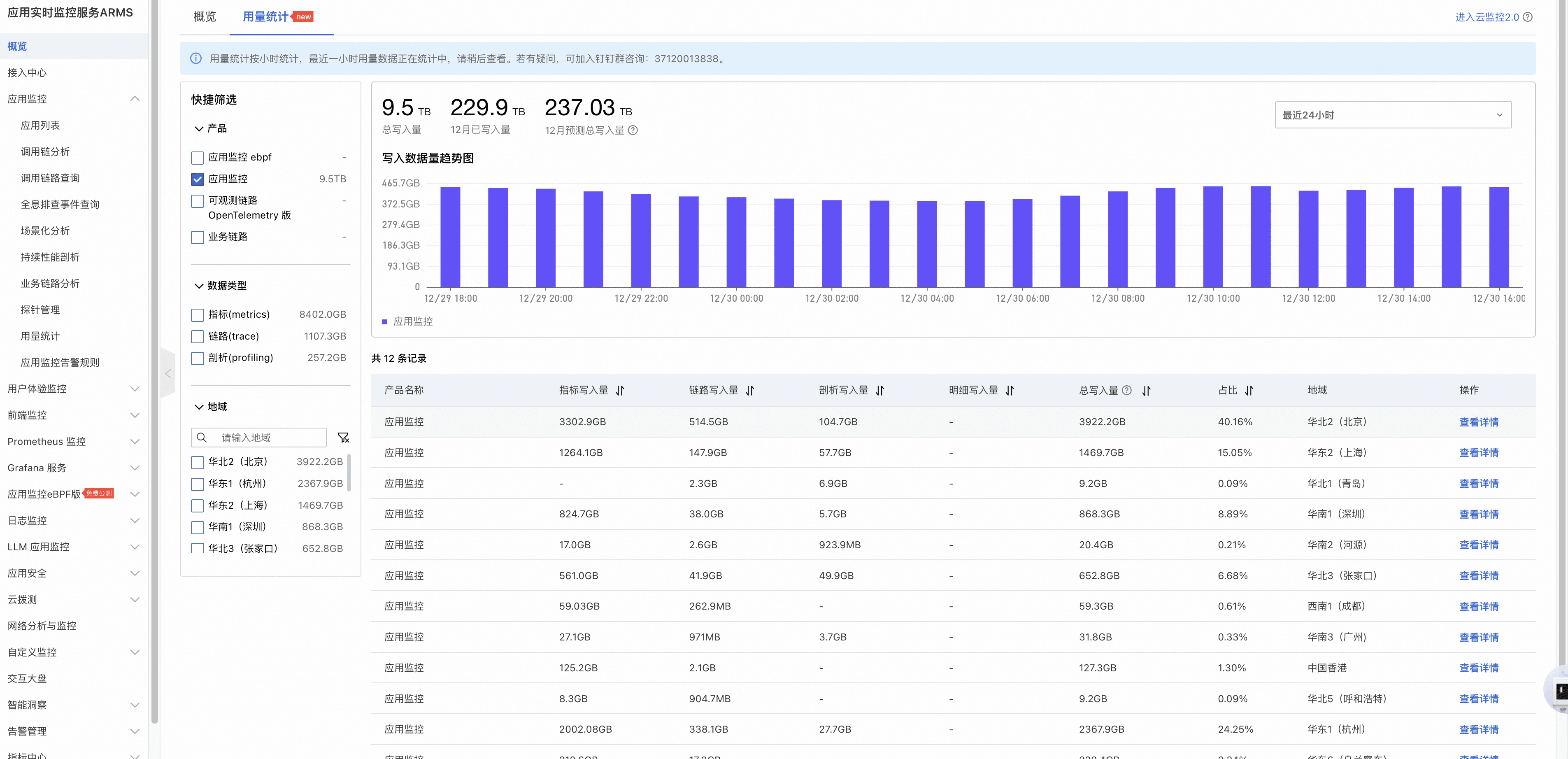
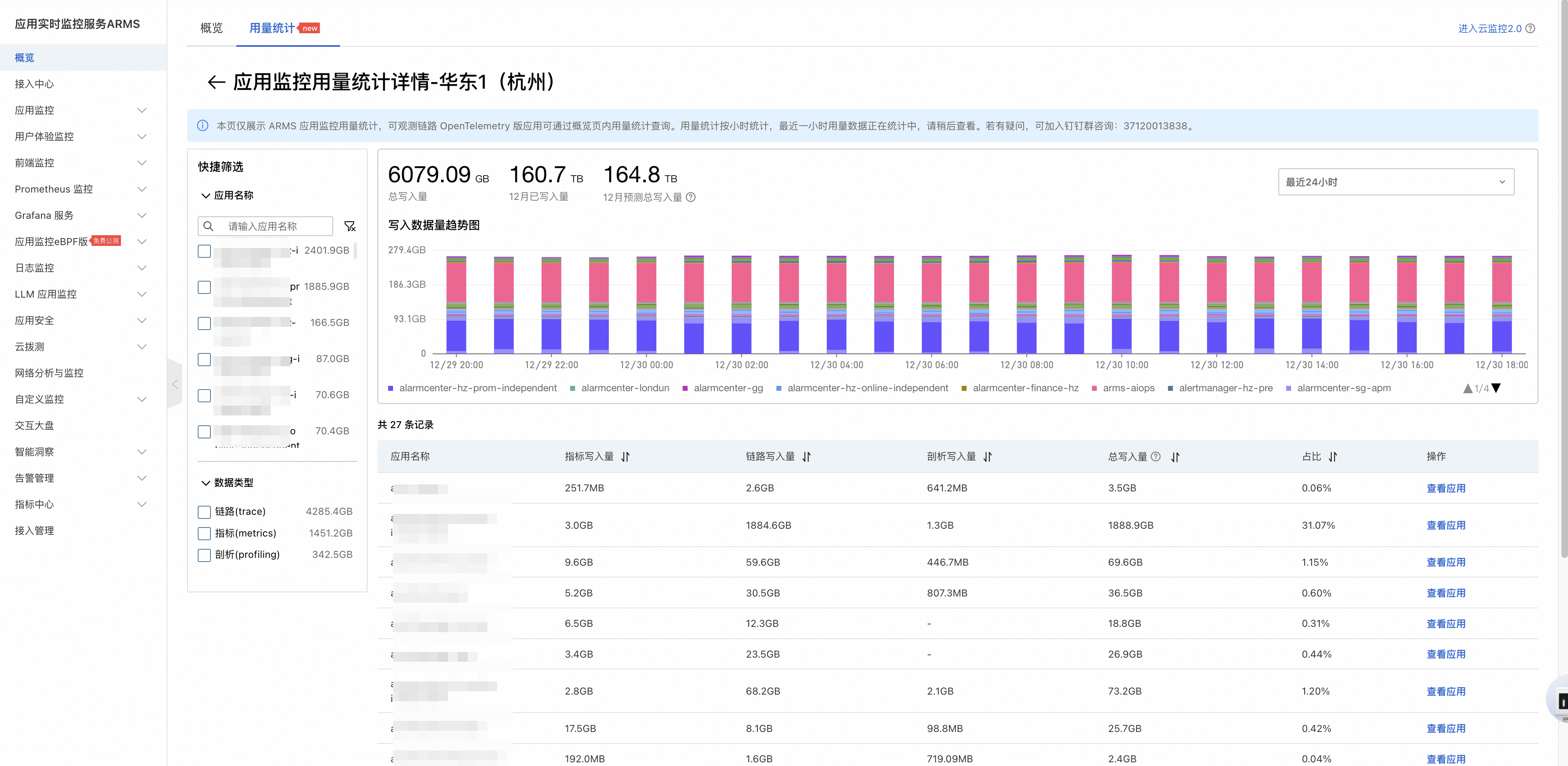
对于数据上报量较高的 region,点击该行右侧的查看详情,即可看到该 region 内各应用的上报分布。如下图所示,每一行会分别展示某个应用的指标、调用链以及持续剖析数据写入量。到这里,你基本就能锁定“主要元凶”,接下来就是针对性降量。
二、降低指标数据上报量:先找最大头,再逐个处理
ARMS 在某个 region 的指标数据会落在 SLS 的 MetricStore 中。我们可以通过查询语句,快速判断某个应用上报的指标里,究竟哪一类指标占比最高,从而“先砍大头”。
2.1 找到对应的 MetricStore
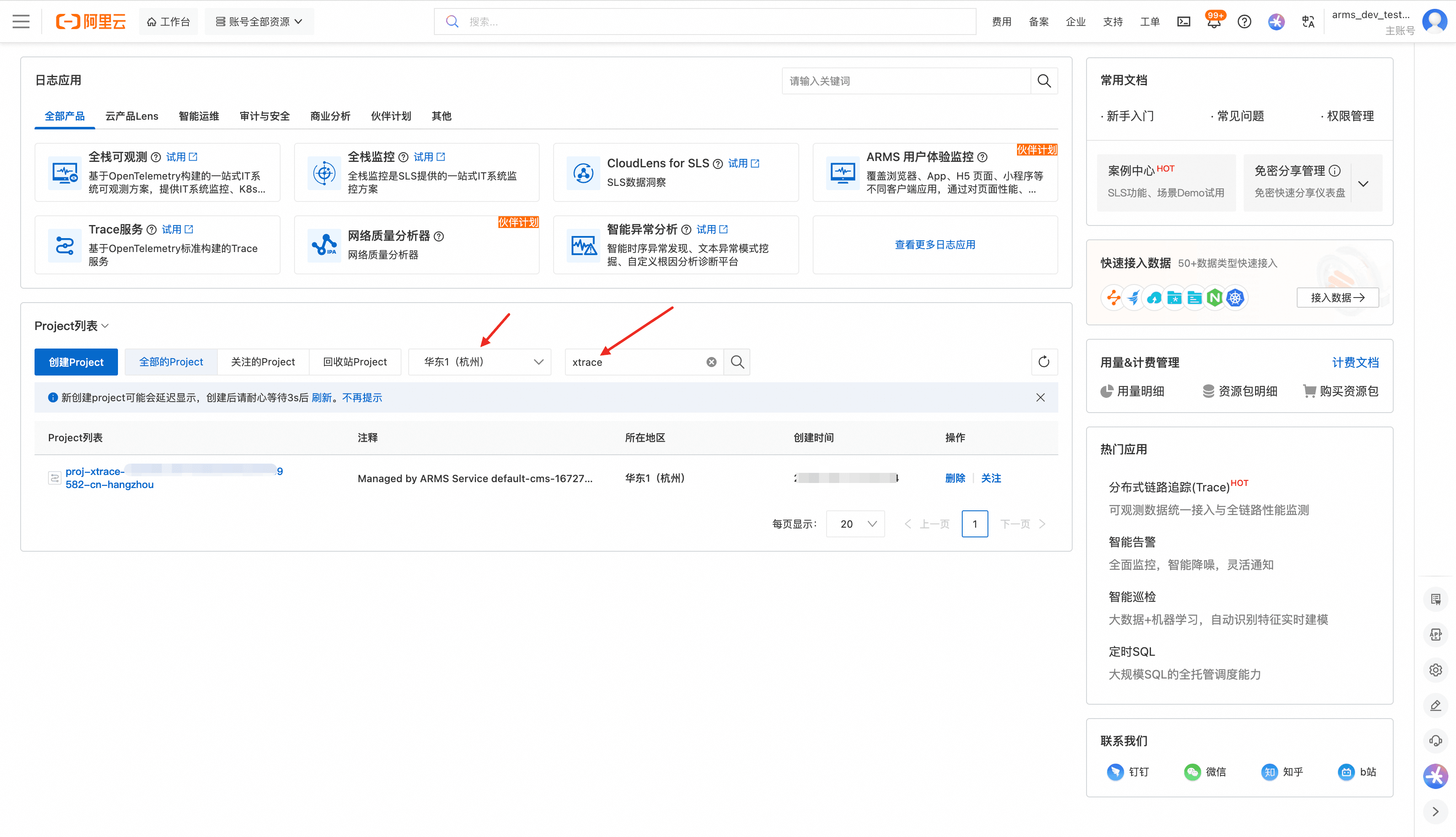
进入 SLS 控制台,选择对应 region,并搜索包含 xtrace 关键字的 project,如下图所示:
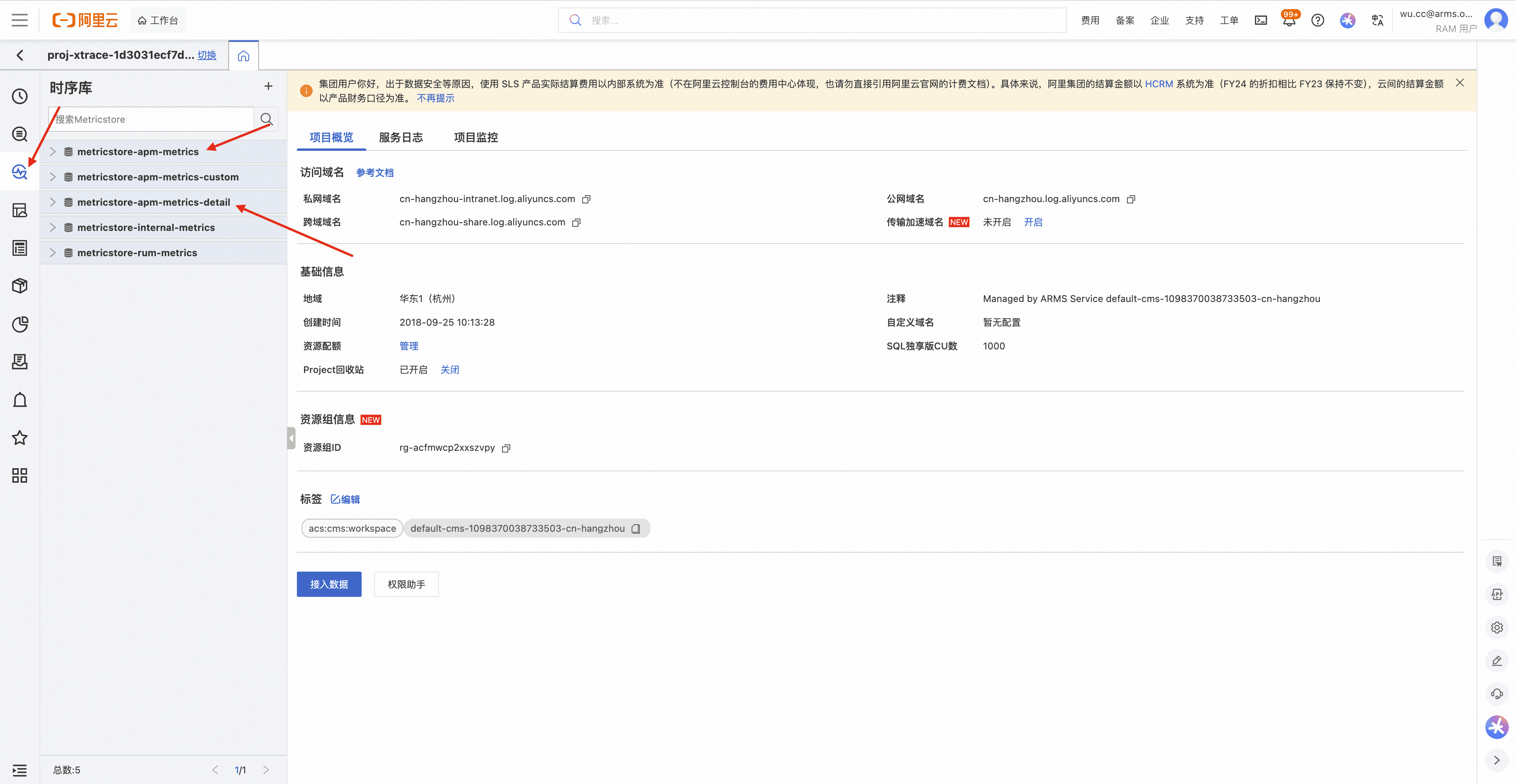
进入该 project 后,点击左侧 metricstore,重点关注以下三个 metricstore:
- metricstore-apm-metrics:存储探针上报的系统指标、Runtime 指标以及预聚合后的 RED 指标
- metricstore-apm-metrics-detail:存储探针原始上报的 RED 数据
- metricstore-apm-metrics-custom:存储探针上报的自定义指标,比如通过 OpenTelemetry SDK 自定义上报的指标
当指标上报量偏高时,通常会体现在以上三个 metricstore 的写入量明显增大。
2.2 用查询语句找出“最费量”的指标类型
进入单个 metricstore,点击自定义查询:
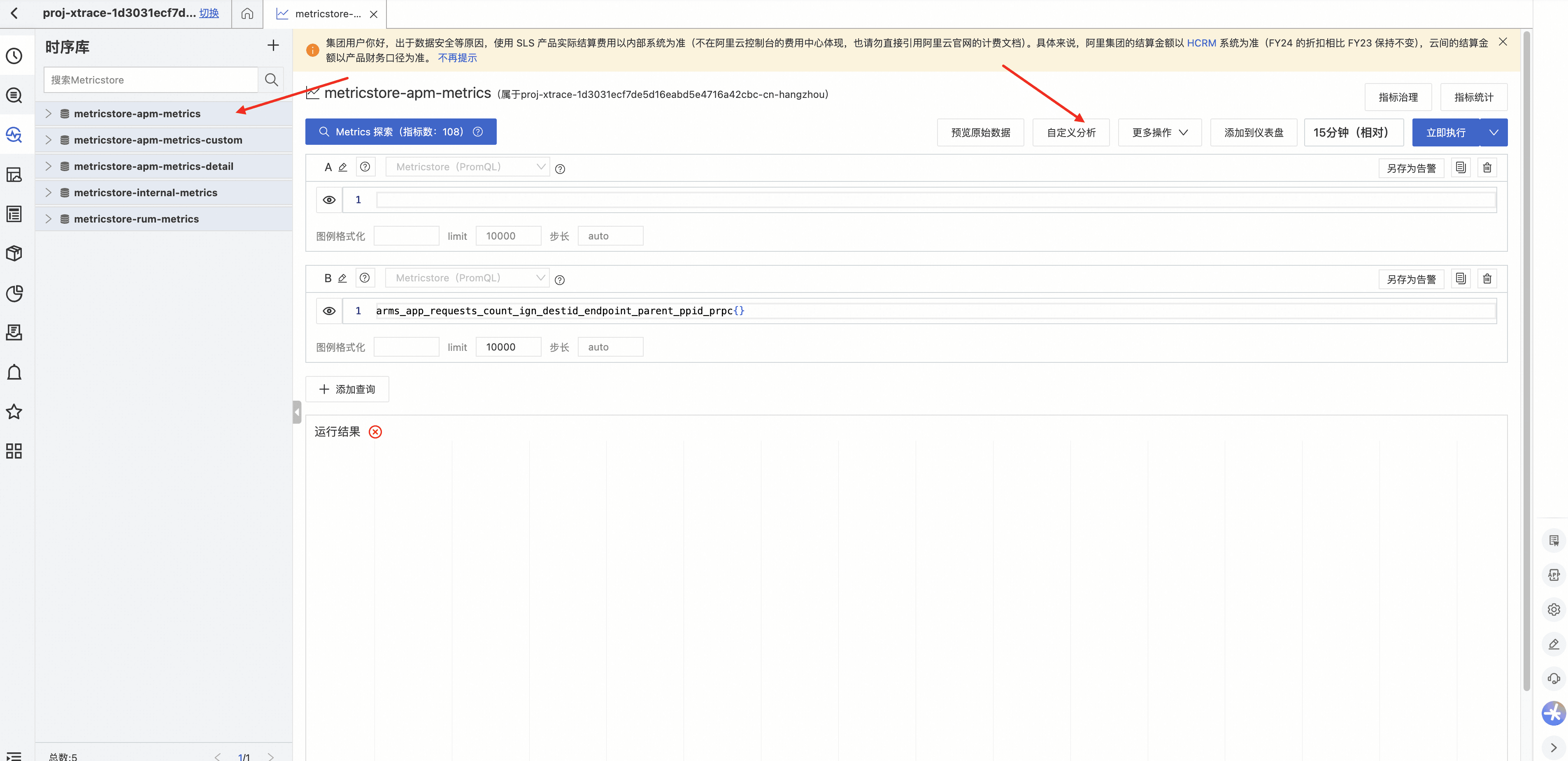
在自定义分析页面,使用下述语句即可统计右上角时间范围内,指定应用不同指标类型的上报量。
需要注意:${metricstoreName} 和 ${serviceName} 需要替换为当前查询的 metricstore 名称,以及数据上报量较高的应用名称。
(*)| SELECT round(sum(length(**name**) + length(**labels**) + 16), 3) as num, **name** as name from "${metricstoreName}.prom" where **name** != '' and element_at(**labels**, 'service') = '${serviceName}' group by name order by num desc
结果如下图所示,会展示不同类型指标的数据量占比:
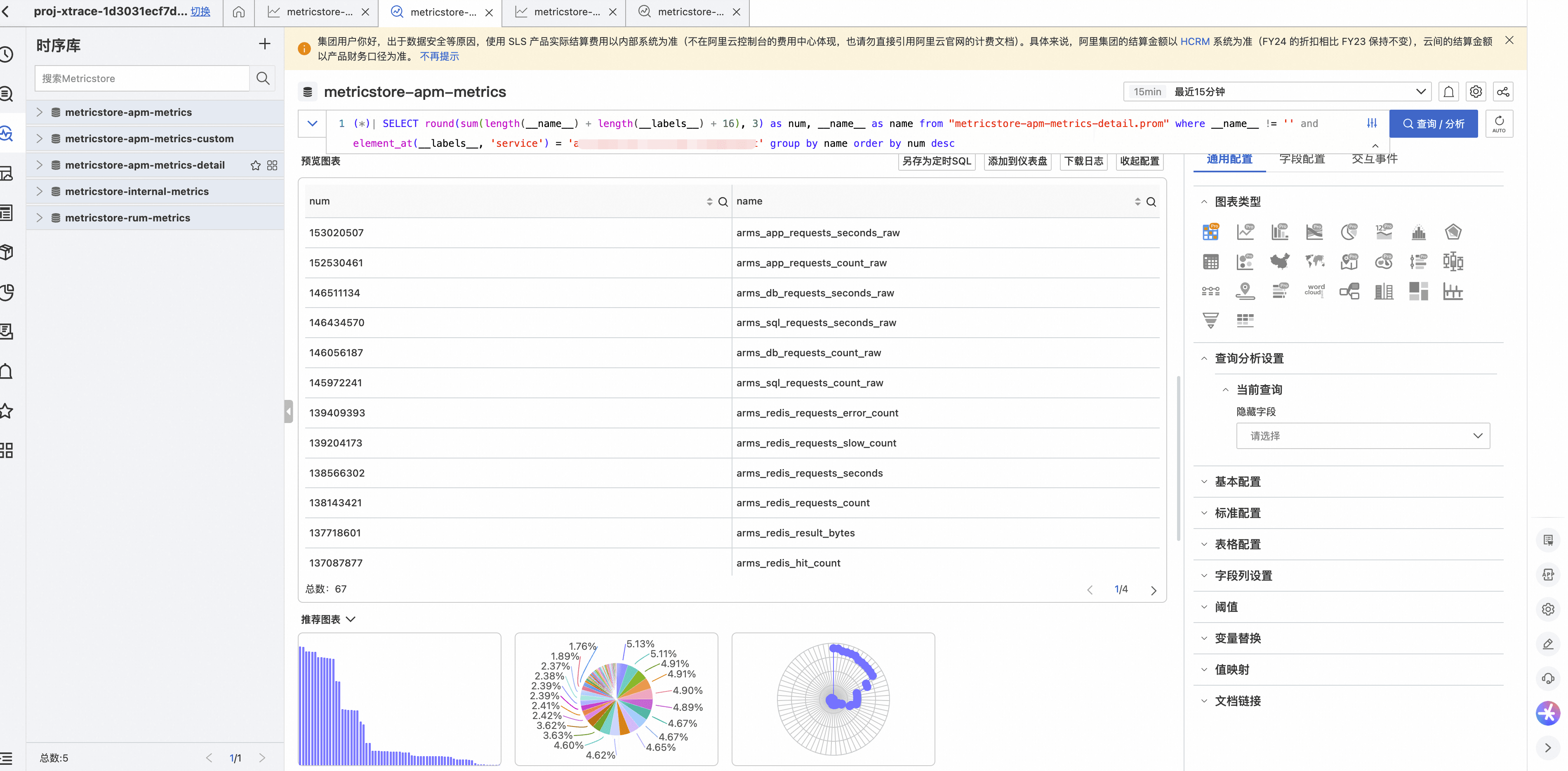
2.3 常见“大户”与对应处理建议
常见的高上报量指标类型通常包括以下几类:
- arms_thread_pool 开头指标上报量高:一般意味着业务中线程池实例很多。ARMS 线程池监控会采集所有线程池实例指标,详情见 ARMS 线程池监控功能介绍。此时可以在应用配置页面关闭池化监控功能,或过滤部分不关注的线程池实例,详情参见线程池监控配置
- arms_grouped_thread 开头指标上报量高:一般是应用线程数较多。ARMS 会采集 JVM 线程耗时与状态分布,并按线程名聚类统计,详情参见 ARMS 线程分析功能介绍。此时只能通过关闭线程池监控来整体关闭线程分析能力,详情参见线程分析配置
- **arms_callTyperequests∗∗开头指标上报量高:通常是某类插件采集过多。这里的‘callTyperequests∗∗开头指标上报量高:通常是某类插件采集过多。这里的‘callType` 代表协议类型,如 http、redis、grpc 等。可按实际场景选择两种治理方式:
三、降低调用链数据上报量:先校准采样,再排查“外部采样决策”
ARMS 在某个 region 的调用链数据会存储在 SLS 的 Logstore 中。调用链写入量偏高时,最常见的优化手段是调整采样率,并确认采样是否真的生效。
3.1 采样率调整的关键前提:只在“入口”生效
调用链数据上报过多时,通常可以先尝试调整采样率。但需要特别注意:在 ARMS 当前采样策略下,采样率仅对调用入口有效。
例如:应用 A 调用应用 B。若 A 的采样率为 100%,那么 B 无论设置多少采样率都不会生效,最终会以 A 的采样决策为准。做治理时更推荐:修改完采样率后批量复制到所有应用,减少寻找入口应用的成本。
3.2 如何验证采样率是否生效?
调整后可按如下方式校验:
在应用的提供服务页,找一个调用量较大的接口,观察右上角时间范围内的总调用量。例如下图中 /api/ruler/v1/alerts 最近 30 分钟调用量为 123 万次,然后点击右侧调用链进入该接口的 trace 数据:
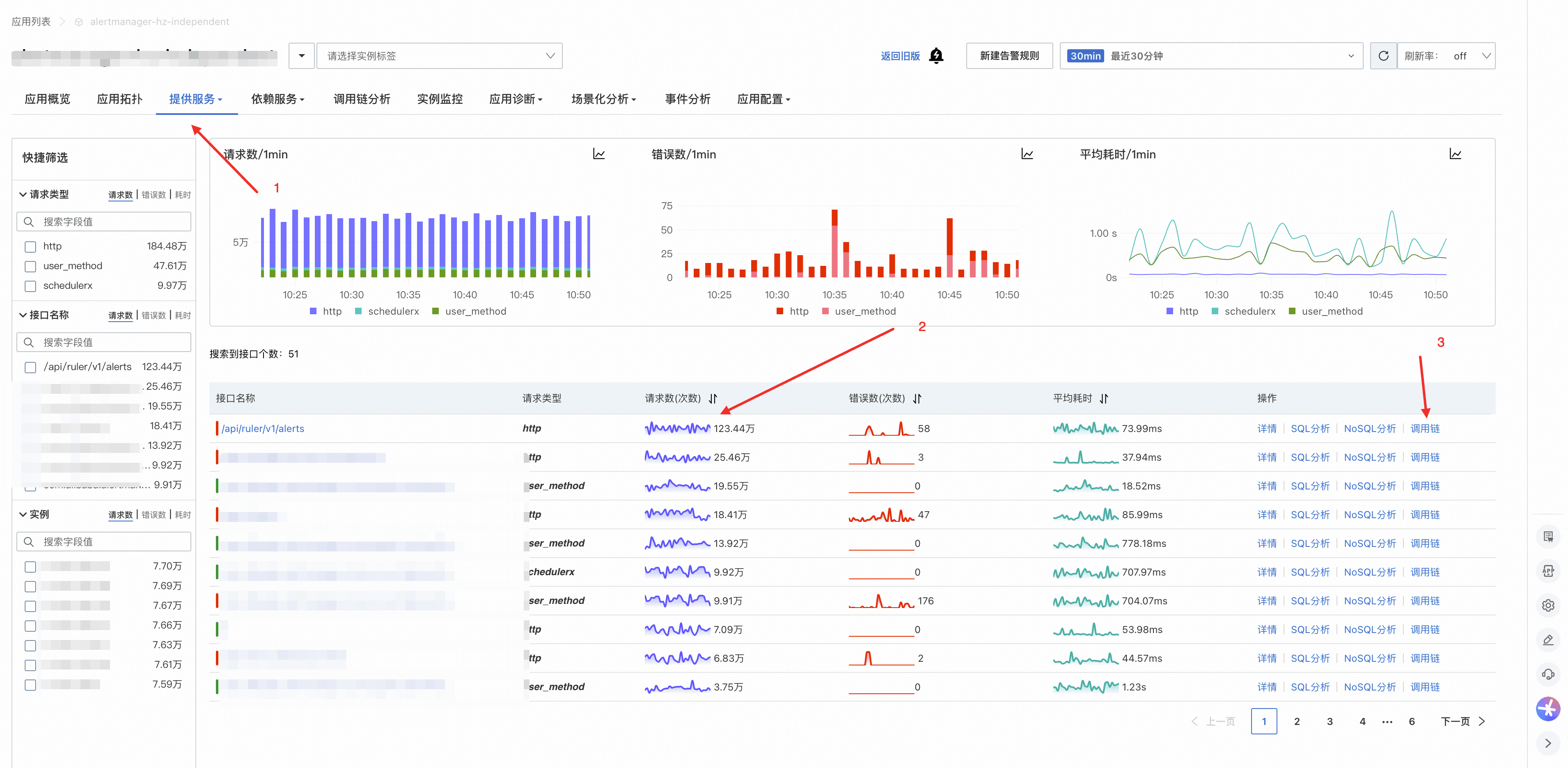
接着观察该接口的 span 数,对比 span 数与调用次数的比例,是否与采样率大致一致:
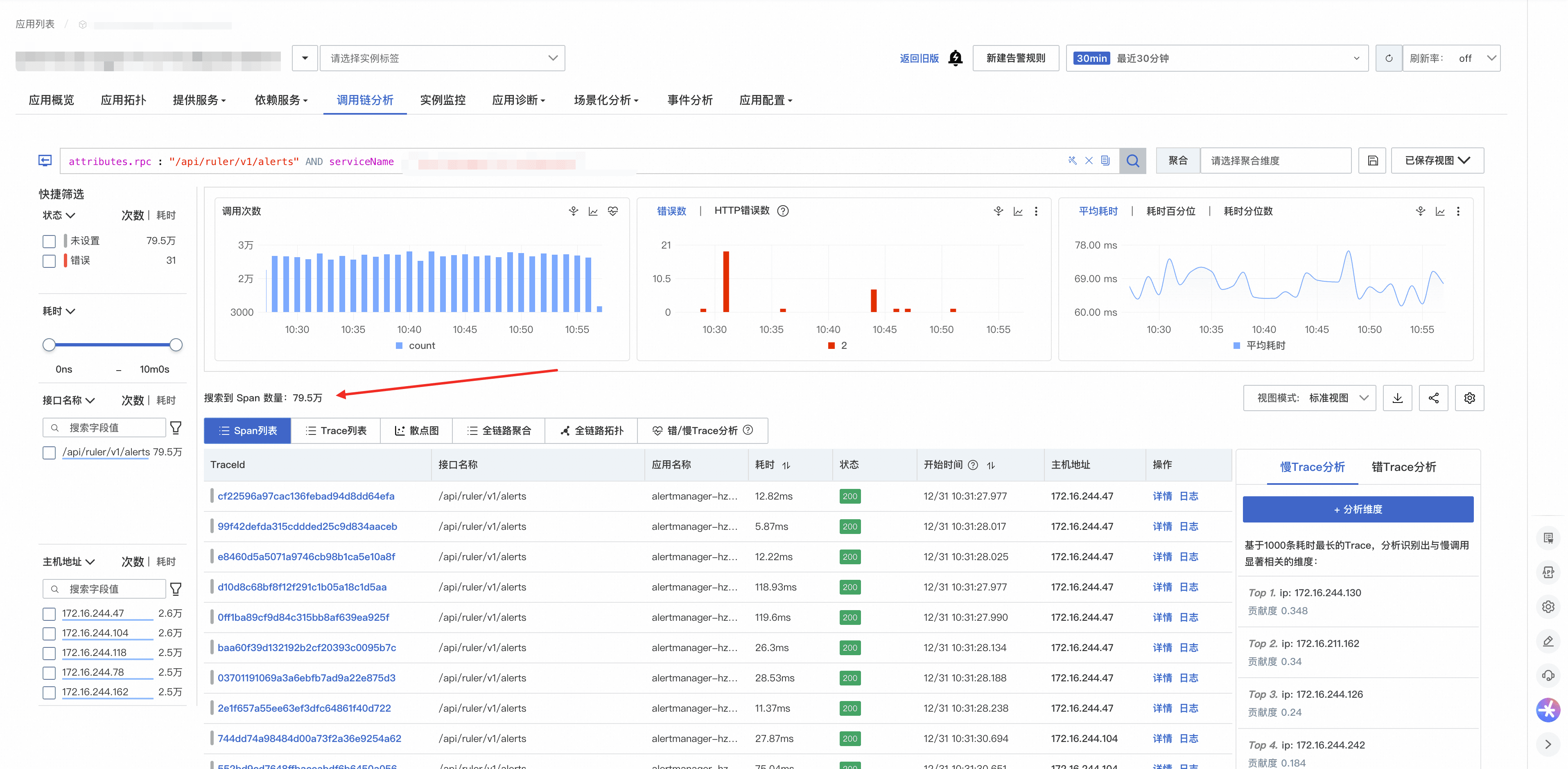
如果不一致,通常落在两类原因里:
3.3 只比采样率略高:多半是“非头采样”在补采
如果相比采样率只是小幅上涨,一般考虑 ARMS 的一些非头采样策略导致,常见三种:
- 小流量采样:可以在过滤条件中新增
- 错/异常采样:可通过 attributes.sample.reason=s9 或 attributes.sample.reason=s11 查找。目前对这类 span 没有控制手段,建议从业务侧优化,减少接口报错和异常抛出。
- 慢采样:可通过 attributes.sample.reason=s10 查找。如果过多,可在接口调用配置中调大慢调用阈值降低。
3.4 远高于采样率:入口可能“继承了外部的采样决策”
如果 span 数与采样率差距很大,通常是外部系统调用入口应用时携带了 trace 上下文,入口应用会遵从外部的采样决策,从而导致本地采样率不生效。常见场景如下:
- 接入 ARMS RUM 监控:需要在 RUM 中调整采样率,参见 调整 RUM 采样率
- 开启了 MSE 网关链路追踪:可在 MSE 网关配置页调整采样率,参见 调整 MSE 网关采样率
- K8S Ingress Controller 开启了链路追踪:场景较多,建议查阅对应项目文档。下面以 Nginx Ingress Controller + OpenTelemetry 为例:通过 ConfigMap 决定是否开启以及采样率,如下为 10% 采样率配置
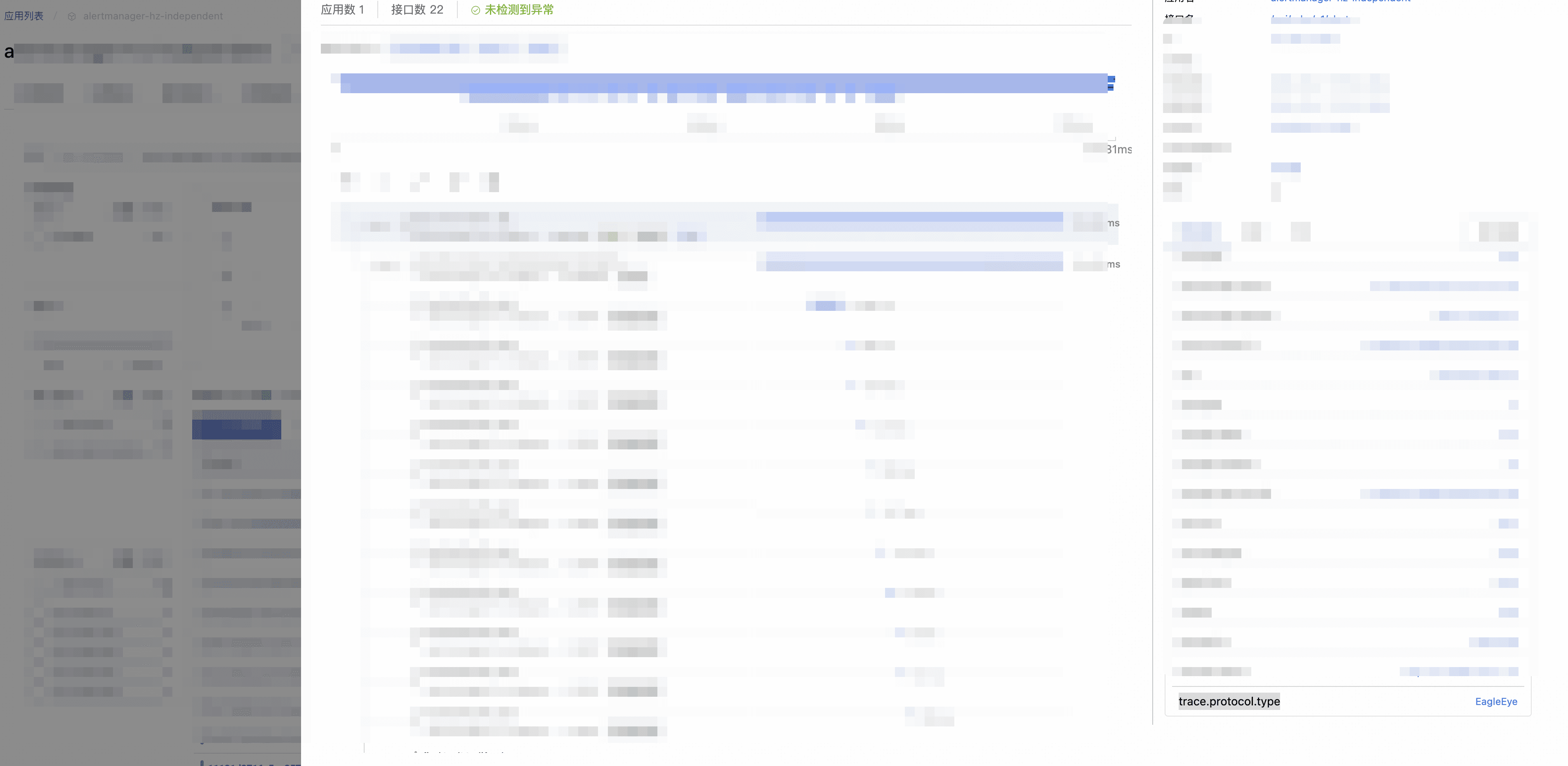
- 无法确认外部 trace 上下文来源:可以随机点开一些调用链,查看 LocalRootSpan 的 trace.protocol.type 这个 attributes(如下图)。随后可在 trace 上下文传播协议配置中 配置强制使用另外一个协议,从而忽略外部携带的 trace 上下文,这里建议使用 W3C 协议
四、降低持续剖析数据上报量:三种最直接的手段
如果持续剖析数据上报量比较大,当前有下述三个优化方案:
- 在持续剖析设置页面调整部分功能开关。当前建议的持续剖析功能使用优先级是:代码热点 > CPU 热点 > 内存热点,可按优先级选择性开启部分功能
- 当一个应用存在多个实例时,可以选择性开启部分节点,而不是所有节点全部开启
- 调高 CPU 热点和代码热点的采样频率,或调高内存热点的采样阈值。需要注意:阈值调高可以显著降低该类数据的上报量,但同时也会导致持续剖析数据精度大幅下降。