**引言**
Prometheus已成为可观察指标领域的事实标准。由于各方面因素,当前还有部分用户的部分场景仍使用“自建开源Prometheus+自建开源Thanos+自建Grafana”来实现基础设施和业务应用的指标监控和告警。同时阿里云可观测监控Prometheus版全面对接开源Prometheus生态,支持类型丰富的组件观测,提供高性能、高可用、高扩展、低成本、易维护的指标可观察能力。为了便于用户从自建开源Prometheus迁移到阿里云Prometheus,本文讨论在各个典型场景下的迁移方案。
**自建开源Prometheus+Thanos的典型部署场景**
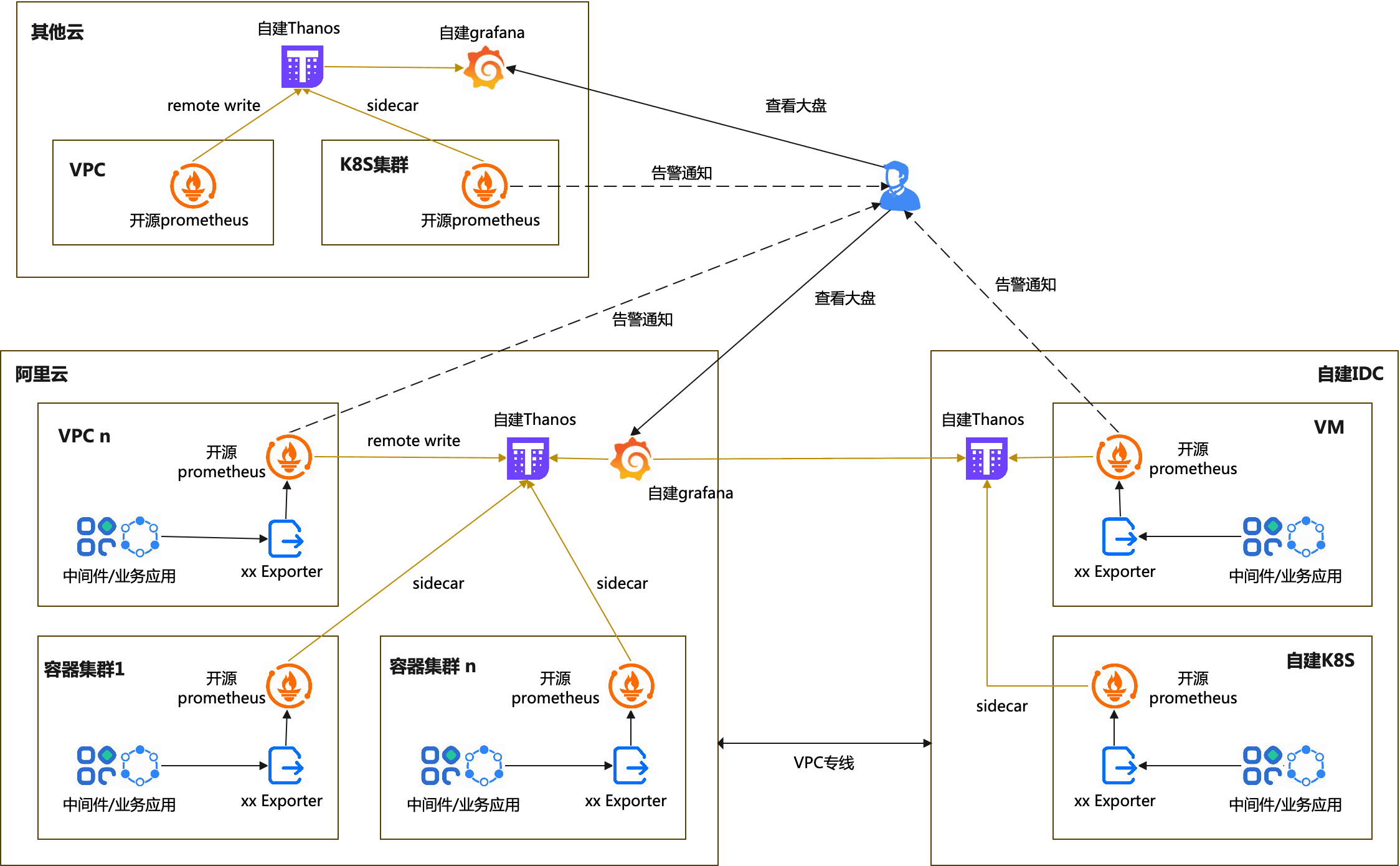
目前典型自建开源Prometheus+Thanos的部署场景包括:
- Kubernetes集群内安装开源Prometheus:
- 阿里云容器服务集群内安装。
- 其他云厂商的容器服务集群内安装。
- 自建IDC内的自建Kubernetes集群内安装。
- 非Kubernetes集群上安装开源Prometheus:
- 阿里云ECS上安装。
- 其他云厂商的ECS上安装。
- 自建IDC内的VM上安装。
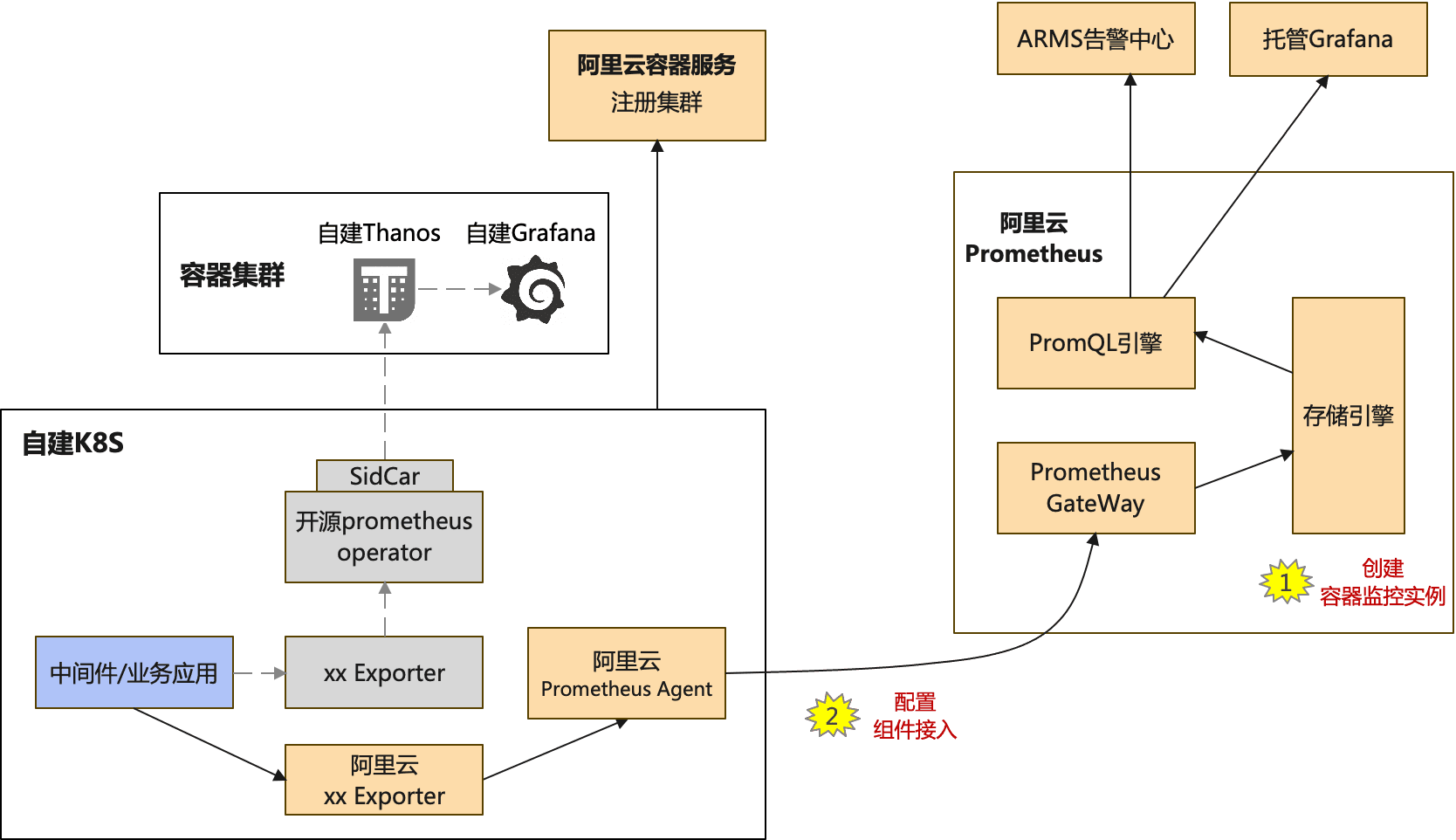
为了满足长期监控需求,通常用户在自建开源Prometheus的基础上,都会再部署一套或多套自建Thanos,将多个自建开源Prometheus数据集中、长期存储。
**自建开源Prometheus+Thanos的痛点**
对于自建开源Prometheus+Thanos,企业通常面临如下主要问题:
- 业务系统使用到的各种组件,需要自行安装exporter、配置大盘和告警规则,工作量大,且通常开源Grafana大盘和告警规则不够专业,缺少结合观测组件的原理和最佳实践进行深入优化后的大盘和告警规则。
- 由于企业部门或业务系统不同,需要在不同的容器集群或VPC内,安装多套自建开源Prometheus,导致部署成本高、运维复杂等。
- 对于容器集群或ECS规模较大时,自建开源Prometheus无法承载大流量的指标处理。
- 引入自建Thanos进行集中、长周期存储后,增加了整个指标可观察体系复杂性。同时由于存在非Kubernetes场景,需要Thanos Receiver支持,导致整个Thanos部署和运维较复杂,成本高。
阿里云可观测监控Prometheus版的能力框架
阿里云可观测监控Prometheus版是一款全面对接开源Prometheus生态,支持类型丰富的组件观测,提供多种开箱即用的预置观测大盘,且提供全托管的混合云/多云Prometheus服务。除了支持阿里云容器服务、自建Kubernetes、Remote Write外,阿里云可观测监控Prometheus版还提供混合云+多云ECS应用的metric观测能力;并且支持多实例聚合观测能力,实现Prometheus指标的统一查询,统一Grafana数据源和统一告警。
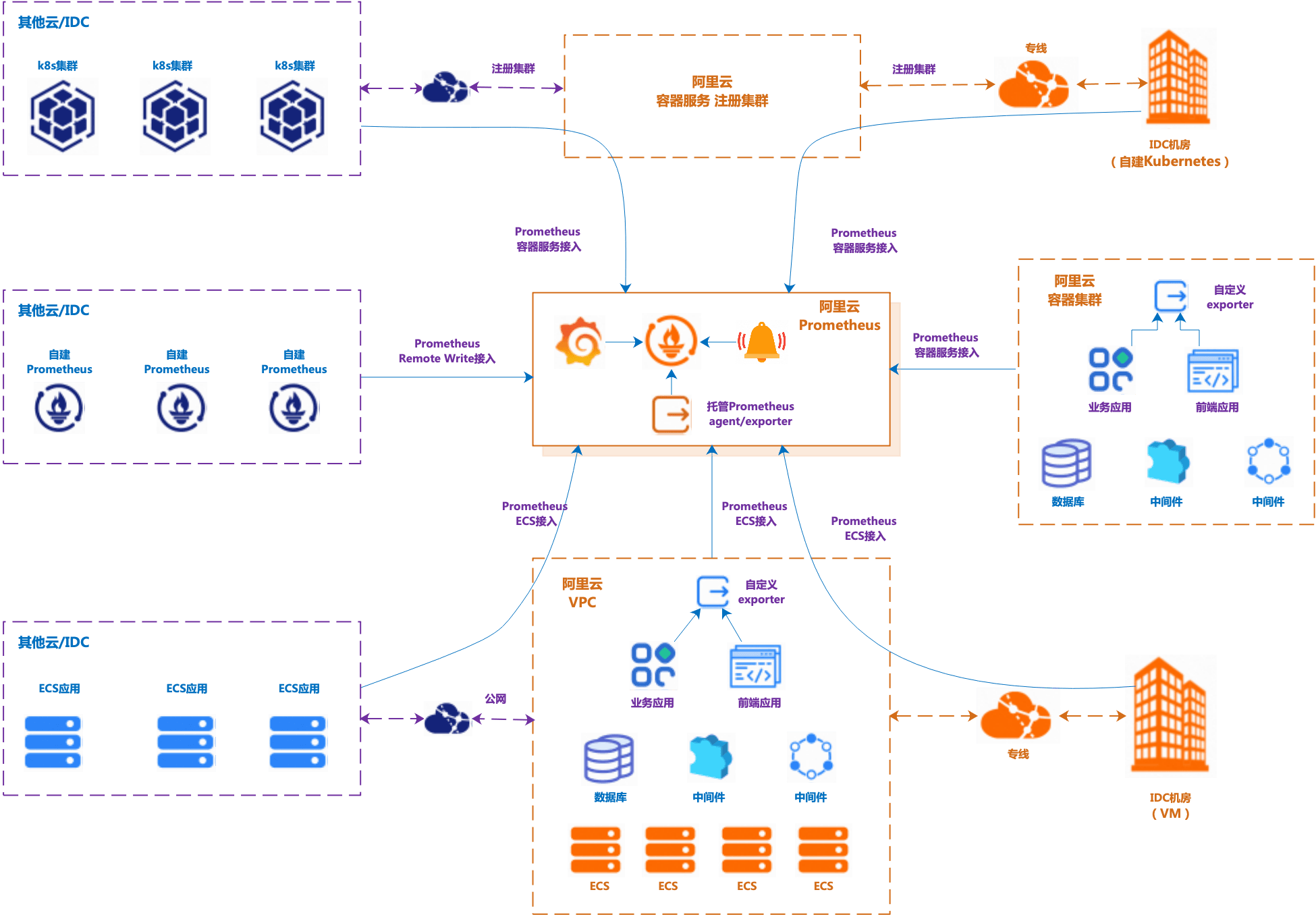
**自建开源Prometheus与阿里云**可观测监控Prometheus版**对比**
| 对比项 | 开源Prometheus | 阿里云可观测监控Prometheus版 |
|---|---|---|
| 部署、维护成本 | 多VPC/多容器集群/多云/多IDC内,都要自购ECS部署Prometheus、Grafana和AlertManager,部署和运维成本高 | Prometheus+Grafana+告警中心的一体化、全托管、免运维、开箱即用 |
| 可用性、性能、 数据容量、保存周期 | 单节点、采集和查询性能低、数据容量小、保存周期短 | 高可用、高性能的采集和查询、大数据容量、长保存周期 |
| 组件监控接入 | 人工部署各种开源Exporter、创建采集job、创建大盘、配置常用告警规则。 | 提供常用组件的一键接入(自动部署exporter、采集job、创建大盘和告警规则)。 |
| 组件Grafana大盘 | 开源组件Grafana大盘通常较朴素,多数只是把采集的metric直接展示,缺少结合监控组件的原理和最佳实践进行深入优化 | 提供常见组件的专业大盘模板,方便用户快速、精准掌握组件运行情况和排查问题 |
| 组件告警项 | 缺少常用组件的告警项模板,需要用户自行研究、配置告警项 | 根据各个组件的监控实践,提供专业、灵活的告警项模板,用户可白屏化配置各个组件的核心和推荐告警项。 |
| 全局聚合查询 | 通过自建Thanos实现“物理聚合”,部署和运维成本高,灵活性低。 | 提供[全局聚合实例](https://help.aliyun.com/zh/prometheus/use-cases/unified-multi-account-monitoring-based-on-prometheus-global-aggregation-instance)能力,支持多个Prometheus实例数据的高性能的动态聚合查询、大盘展示和告警。 |
**自建开源Prometheus迁移到阿里云**可观测监控Prometheus版 **技术方案**
从自建开源Prometheus迁移到阿里云可观测监控Prometheus版包含指标采集、可视化分析、告警配置等三个阶段步骤,下面分别对这三个阶段在不同自建Prometheus部署场景下的方案进行讨论。
**步骤一:指标采集迁移**
指标采集是指Prometheus根据采集Job配置,定时从目标监控组件或其对应的Exporter拉取和保存指标数据。
**阿里云容器服务场景:**[**容器集群监控**](https://help.aliyun.com/zh/prometheus/container-observable)
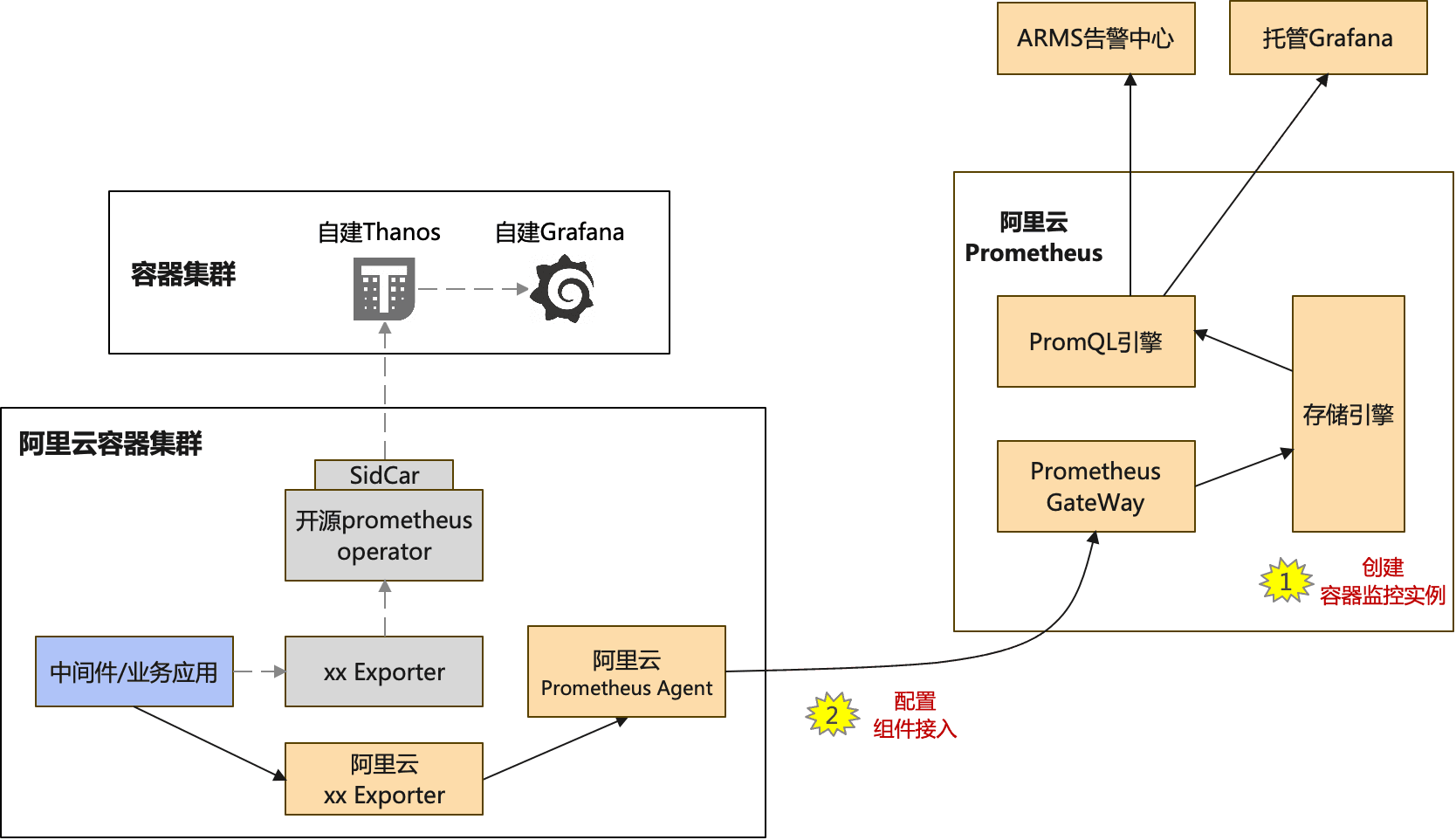
迁移要求
- 阿里云Prometheus配置、验证完,需要n天(现有自建开源prometheus数据保存天数)后,才能完成迁移,以便阿里云Prometheus采集到完整监控数据。
迁移步骤
- 在阿里云Prometheus控制台的“接入中心”,选择“容器集群监控”接入,完成“容器环境”实例创建。
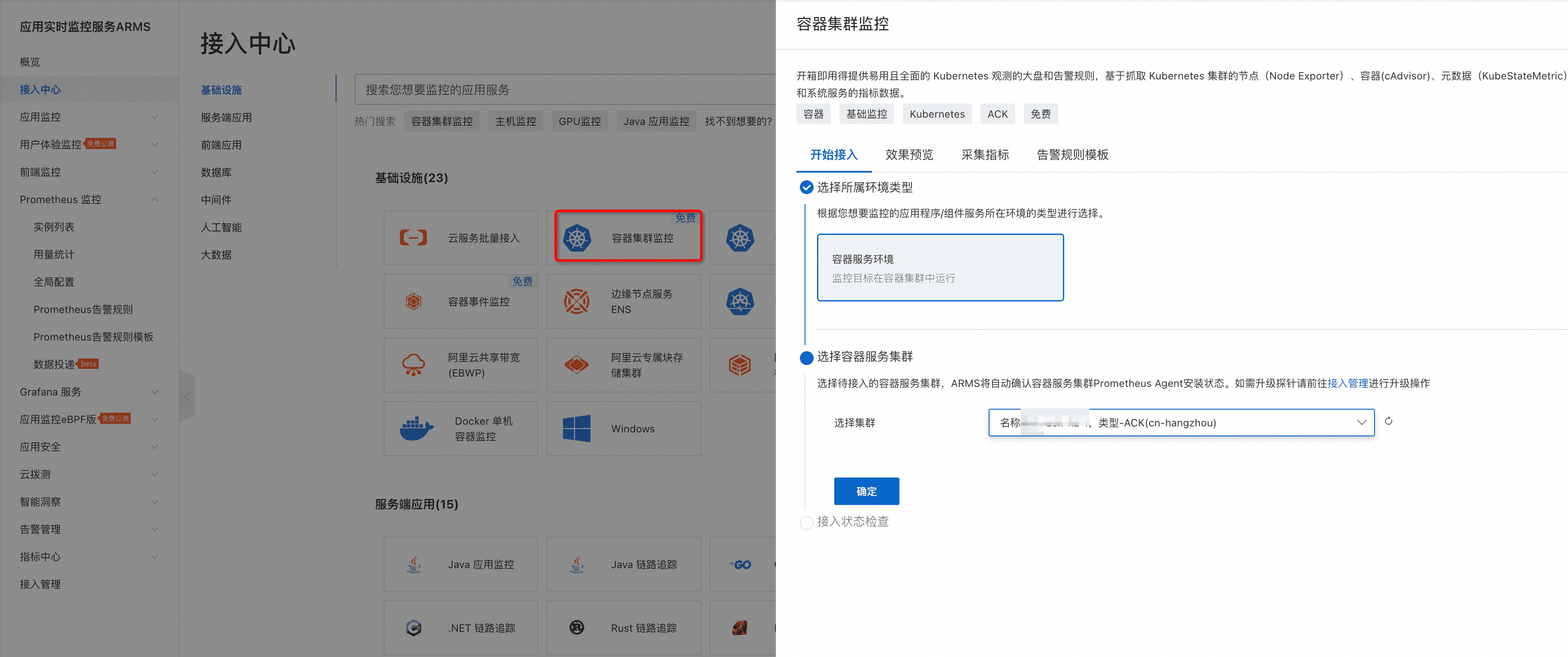
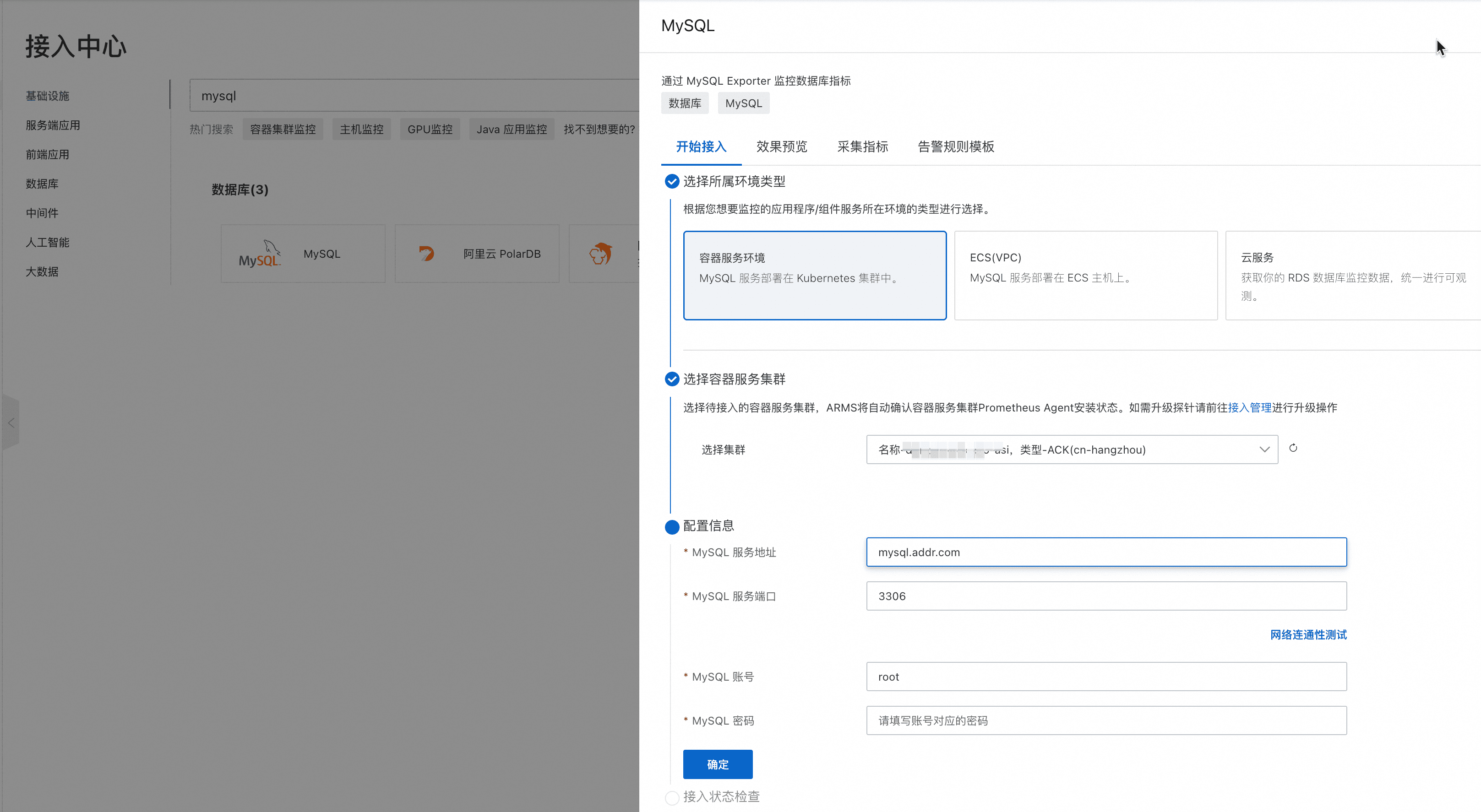
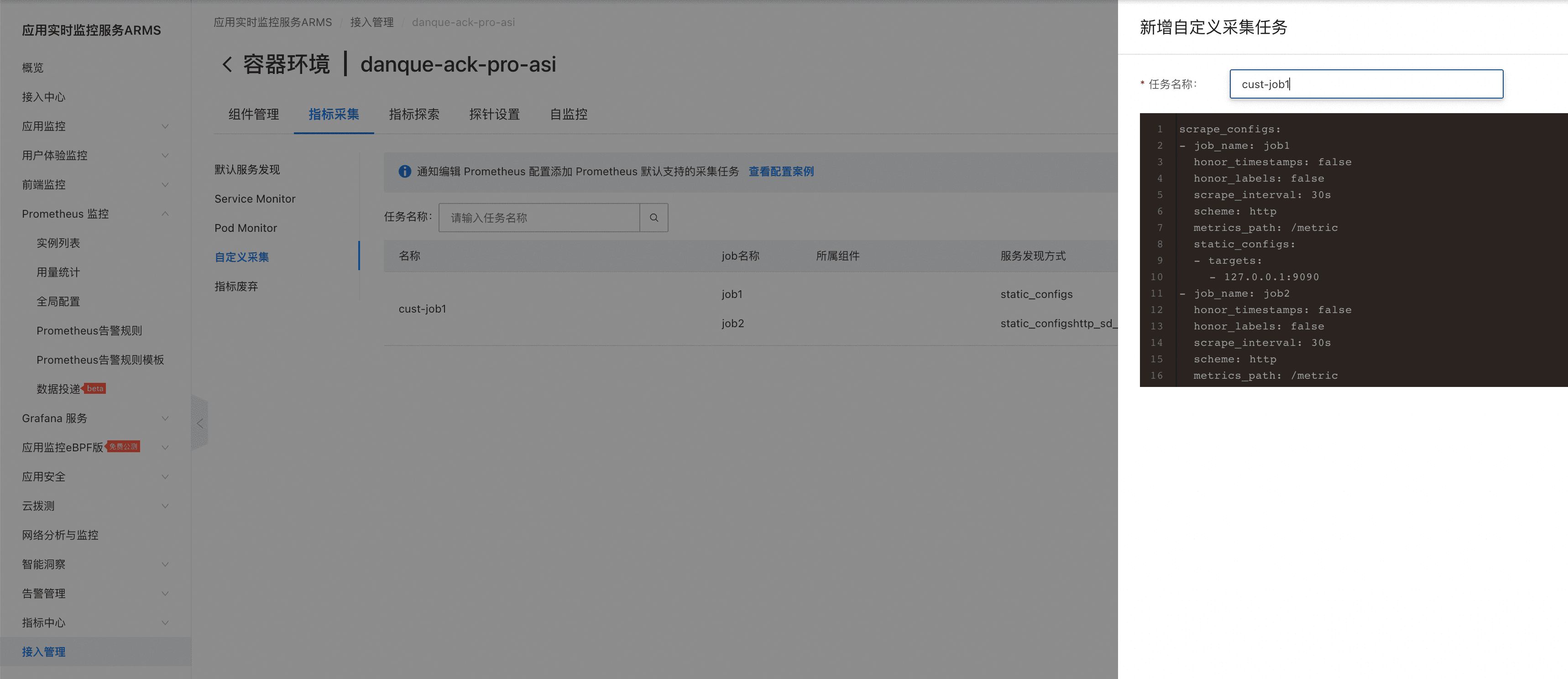
- 【可选】对于用户自定义的采集任务(ServiceMonitor、PodMonitor和自定义Job),可在“接入管理”的对应环境实例进行自定义采集规则配置。
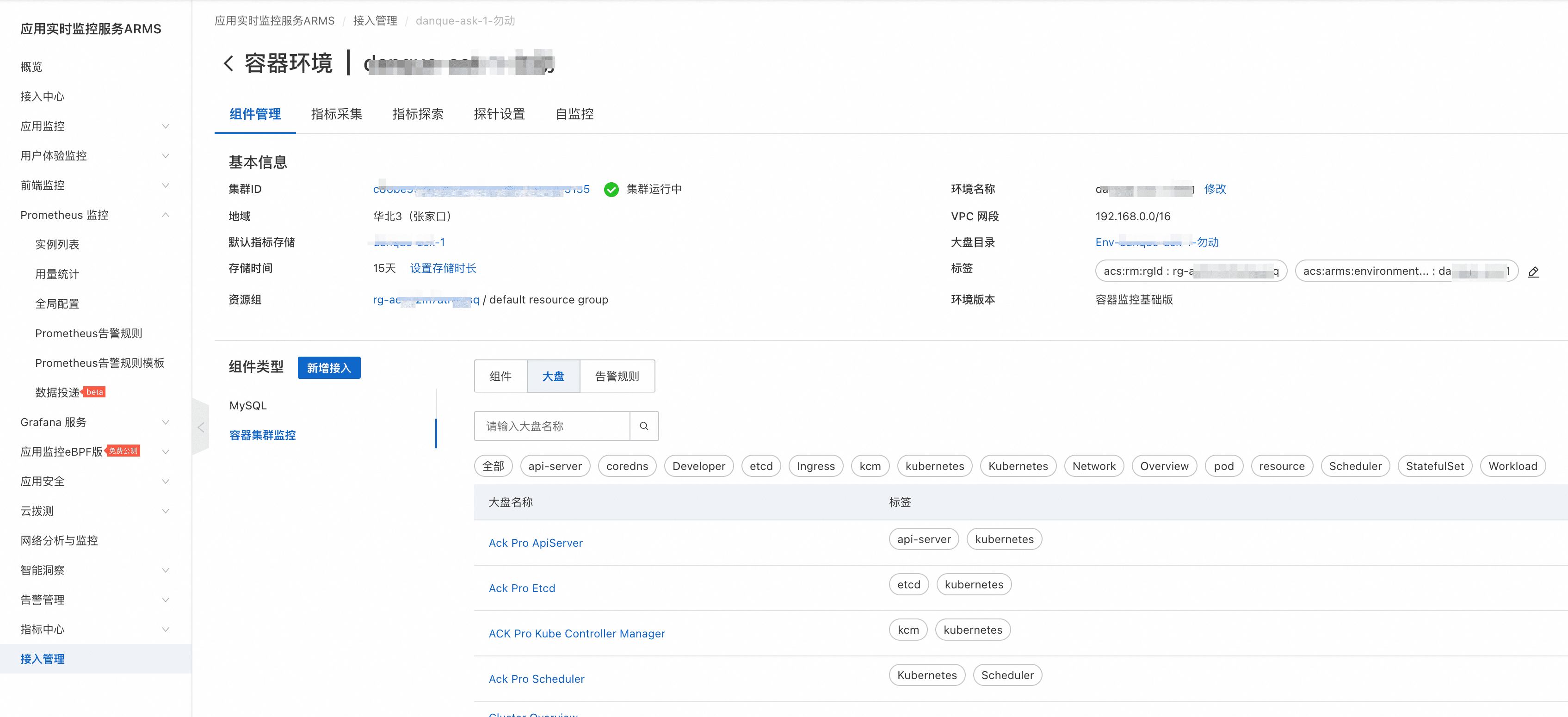
- 验证阿里云Prometheus上容器集群的容器集群大盘和各组件的默认大盘是否正常。
自建Kubernetes场景:[容器集群监控](https://help.aliyun.com/zh/prometheus/container-observable)
此场景与“自建Kubernetes场景:容器集群监控”一样,只是需要先将自建Kubernets集群注册为阿里云容器服务的“注册集群”即可。
阿里云ECS场景:[ECS监控](https://help.aliyun.com/zh/prometheus/host-observable)
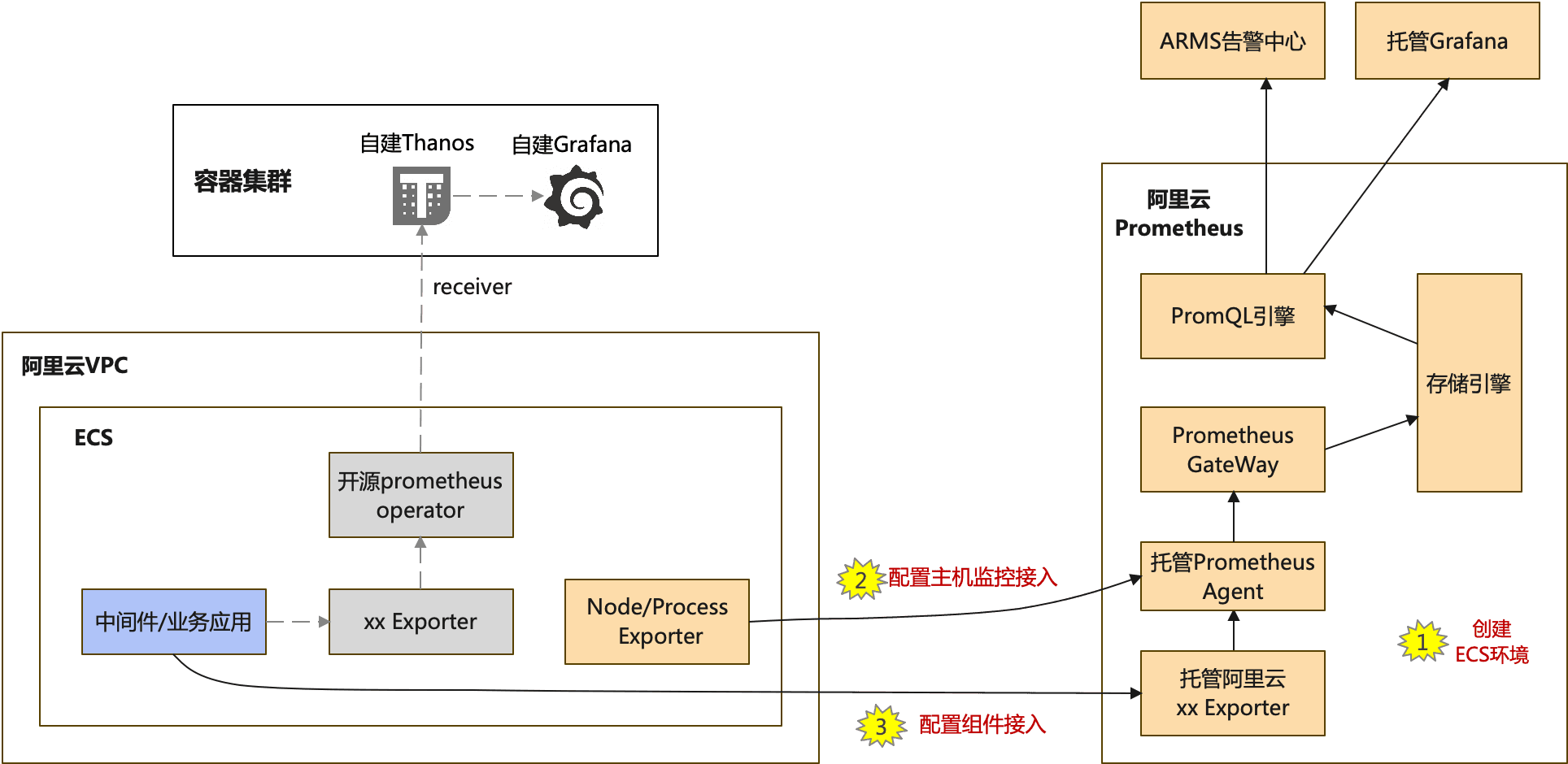
迁移要求
- 阿里云Prometheus配置、验证完,需要n天(现有自建开源prometheus数据保存天数)后,才能完成迁移,以便阿里云Prometheus采集到完整监控数据。
迁移步骤
- 在阿里云Prometheus控制台的“接入中心”,选择“主机监控”,并按界面向导接入后,创建出“ECS环境”实例,同时部署ECS主机监控的Exporter和采集配置。
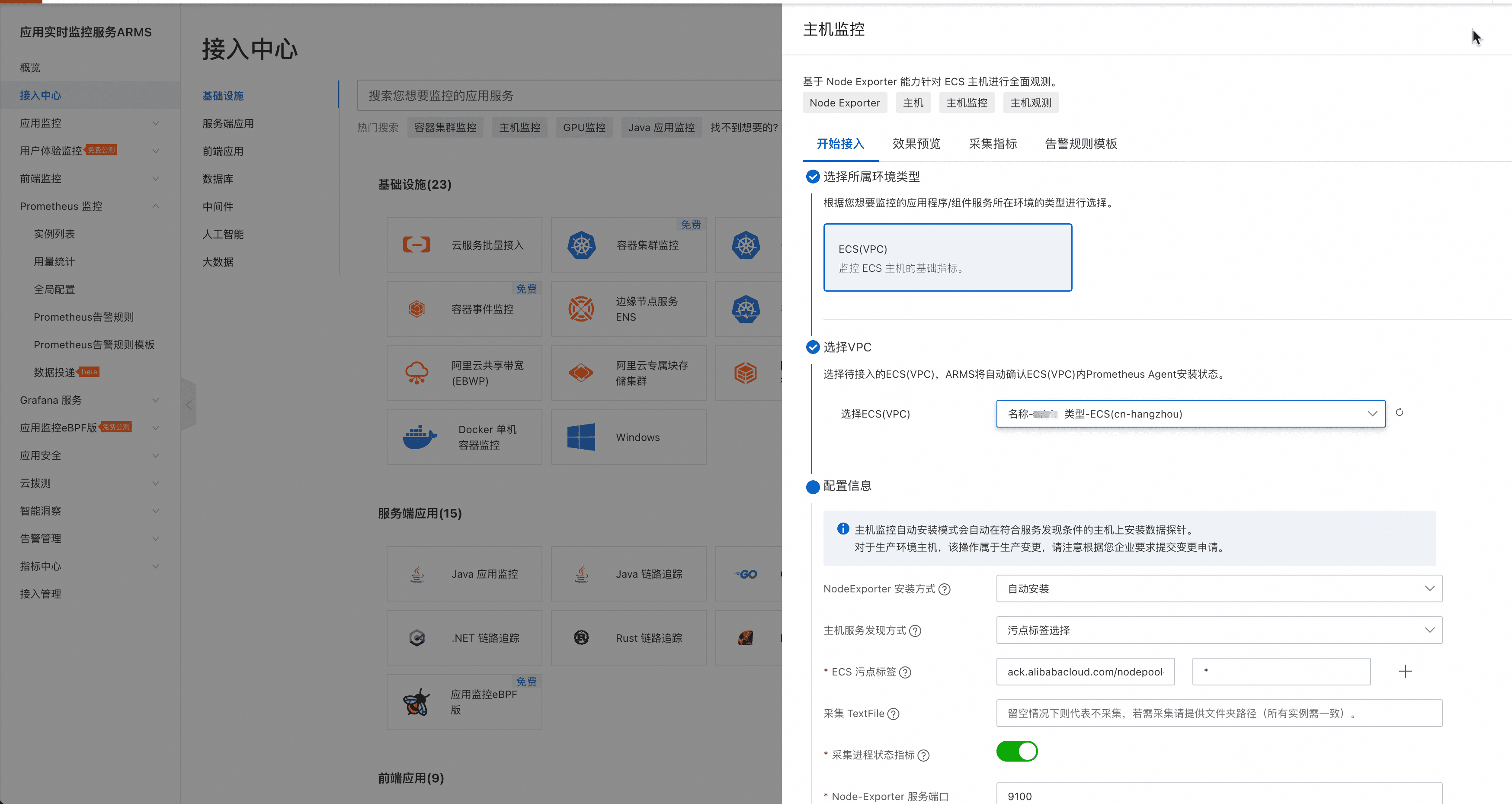
- 在阿里云Prometheus控制台的“接入管理”,配置VPC内各个要监控组件的接入,以便阿里云Prometheus生成采集Job、抓取监控数据、生成默认大盘和默认告警规则。
- 【可选】对于用户自定义的采集任务,可在“接入管理”的对应环境实例进行自定义采集规则配置。
- 验证阿里云Prometheus上各组件的默认大盘是否正常。
自建IDC场景:[ECS监控](https://help.aliyun.com/zh/prometheus/host-observable)
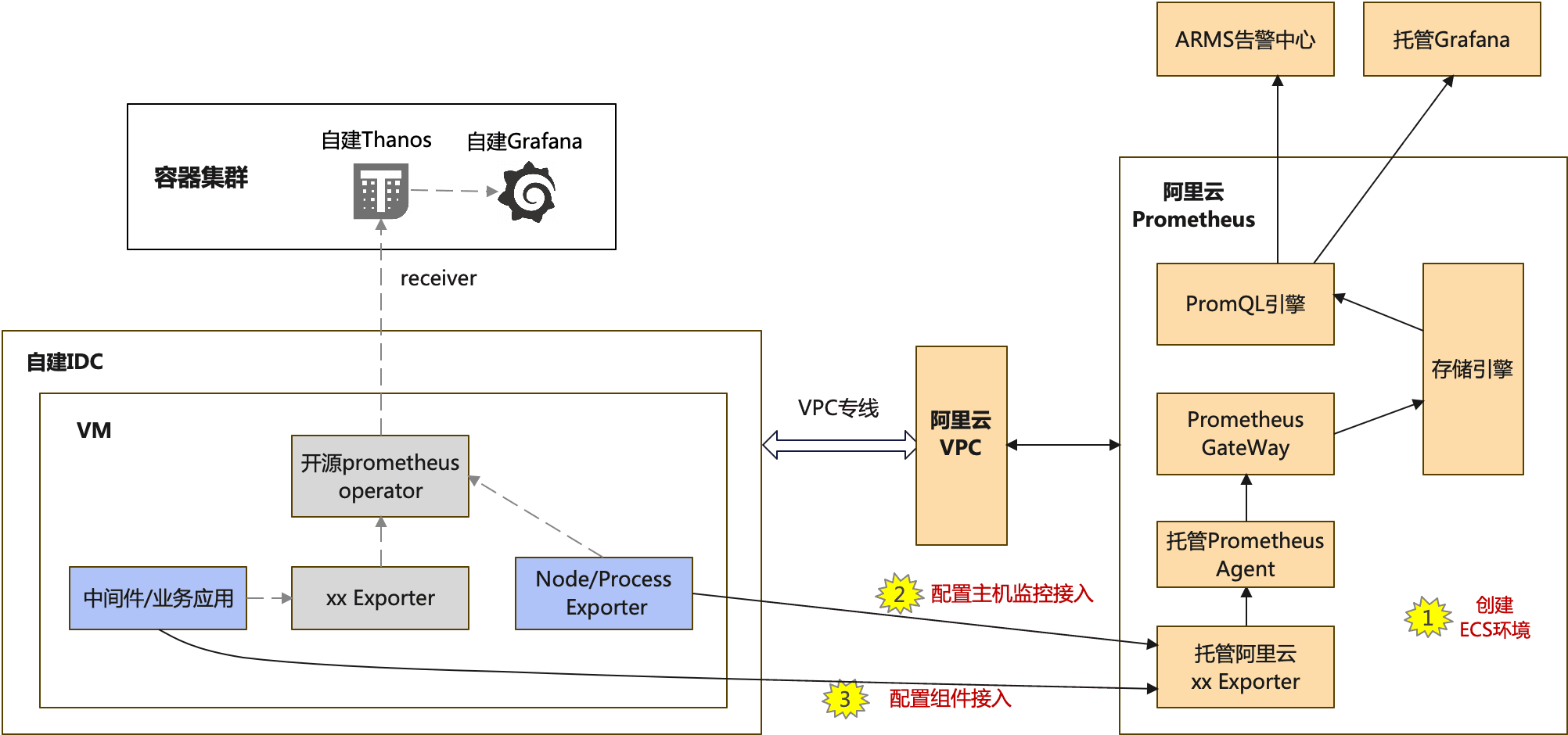
迁移要求
- 阿里云Prometheus配置、验证完,需要n天(现有自建开源prometheus数据保存天数)后,才能完成迁移,以便阿里云Prometheus采集到完整监控数据。
- 需要将自建IDC通过VPC专线等方式与用户的某个阿里云VPC打通。
- 需要用户自行在自建IDC的各个VM上安装Node/Process Exporter。
迁移步骤
- 在阿里云Prometheus控制台的“接入中心”,选择“主机监控(自助安装+IP域选择)”,并按界面向导接入后,创建出“ECS环境”实例,同时生成主机监控的采集配置。
- 在阿里云Prometheus控制台的“接入管理”,配置VPC内各个要监控组件的接入,以便阿里云Prometheus生成采集Job、抓取监控数据、生成默认大盘和默认告警规则。
- 【可选】对于用户自定义的采集任务,可在“接入管理”的对应环境实例进行自定义采集规则配置。
- 验证阿里云Prometheus上各组件的默认大盘是否正常。
**通用RemoteWrite场景:通用实例**
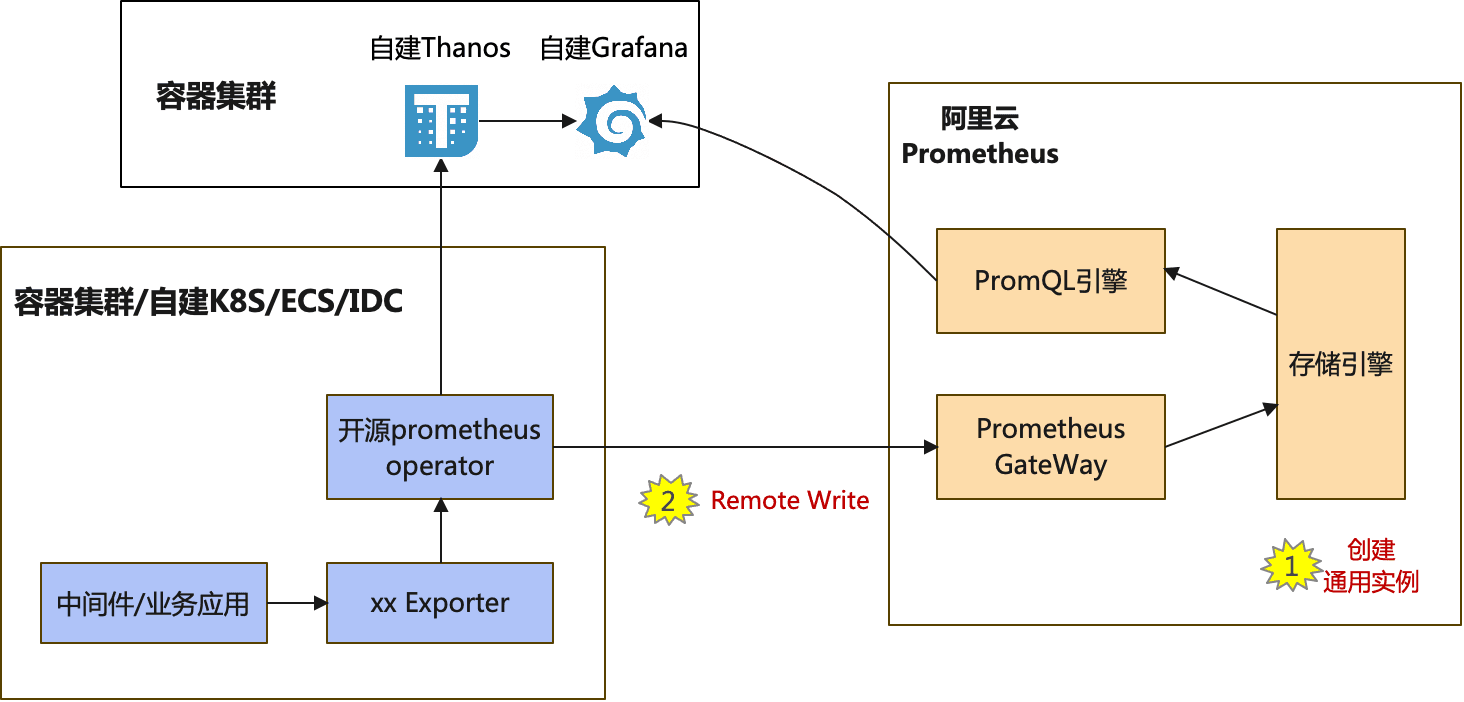
迁移要求
- 阿里云Prometheus配置、验证完,需要n天(现有自建开源prometheus数据保存天数)后,才能完成迁移,以便阿里云Prometheus采集到完整数据。
迁移步骤
- 在阿里云Prometheus控制台的“实例列表”,点击“新建Prometheus实例”,选择“通用实例”后创建出实例。
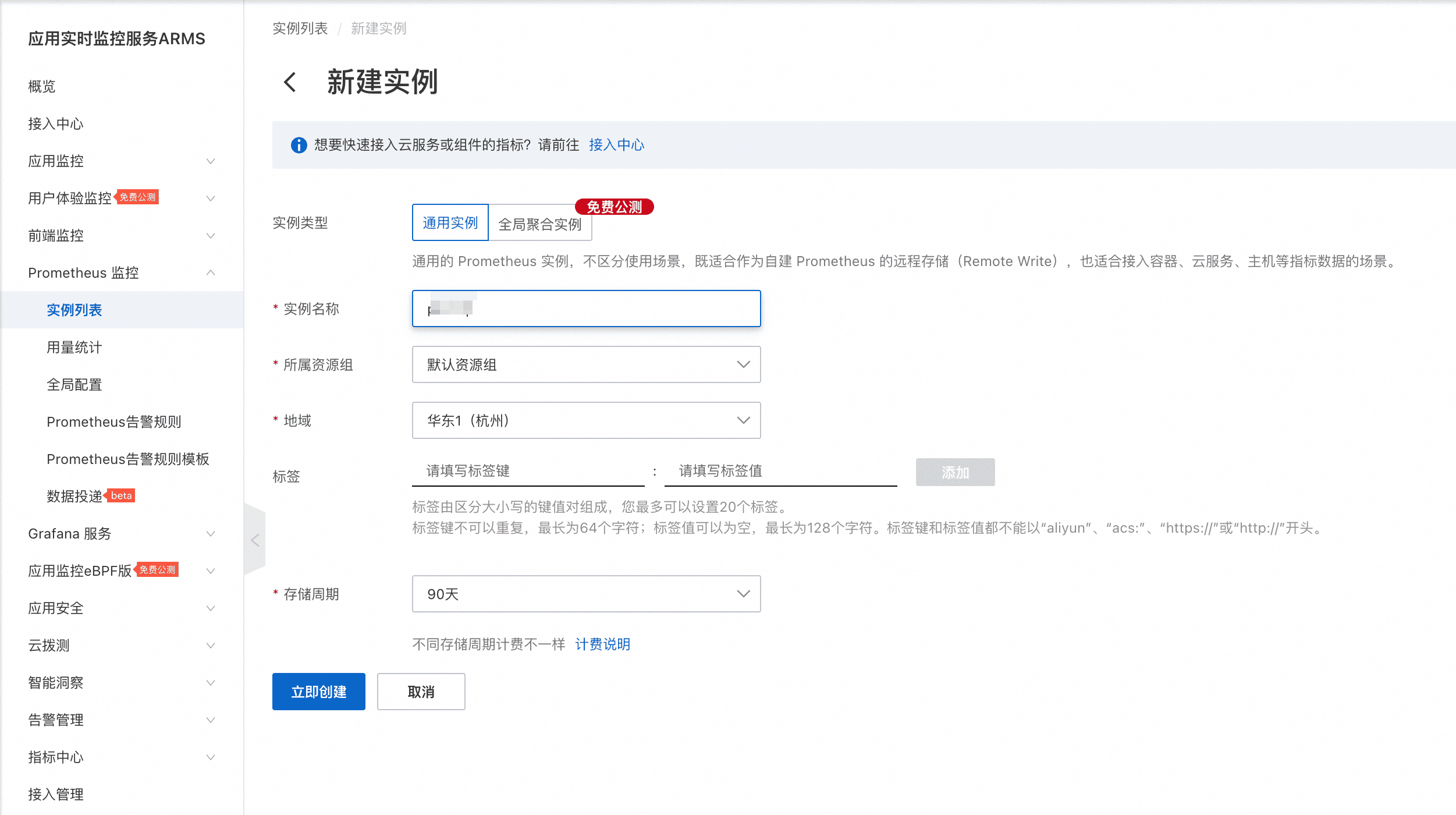
- 修改自建开源Prometheus配置,将监控数据Remote Write到阿里云Prometheus。
- 在阿里云Prometheus控制台的“指标中心”,查询并验证自建开源Prometheus Remote Write上来的指标数据。
**步骤二:可视化分析迁移**
在上述指标采集迁移过程中,涉及到的容器集群和各个常用组件(如Mysql、Redis等),阿里云Prometheus都已内置默认的专业的、开箱即用的大盘。
- 对于容器/Kubernetes和ECS监控场景:
- 在阿里云Prometheus控制台的“接入管理”的“大盘查询”界面,即可查看各组件的默认大盘。
- 对于用户的自定义大盘,需要用户新建专家版Grafana,然后自建Grafana迁移或导入指定大盘即可。
- 对于RemoteWrite场景的通用实例:用户继续使用已有的自建Grafana,只需要将grafana的数据源改为阿里云Prometheus对应实例数据源即可。
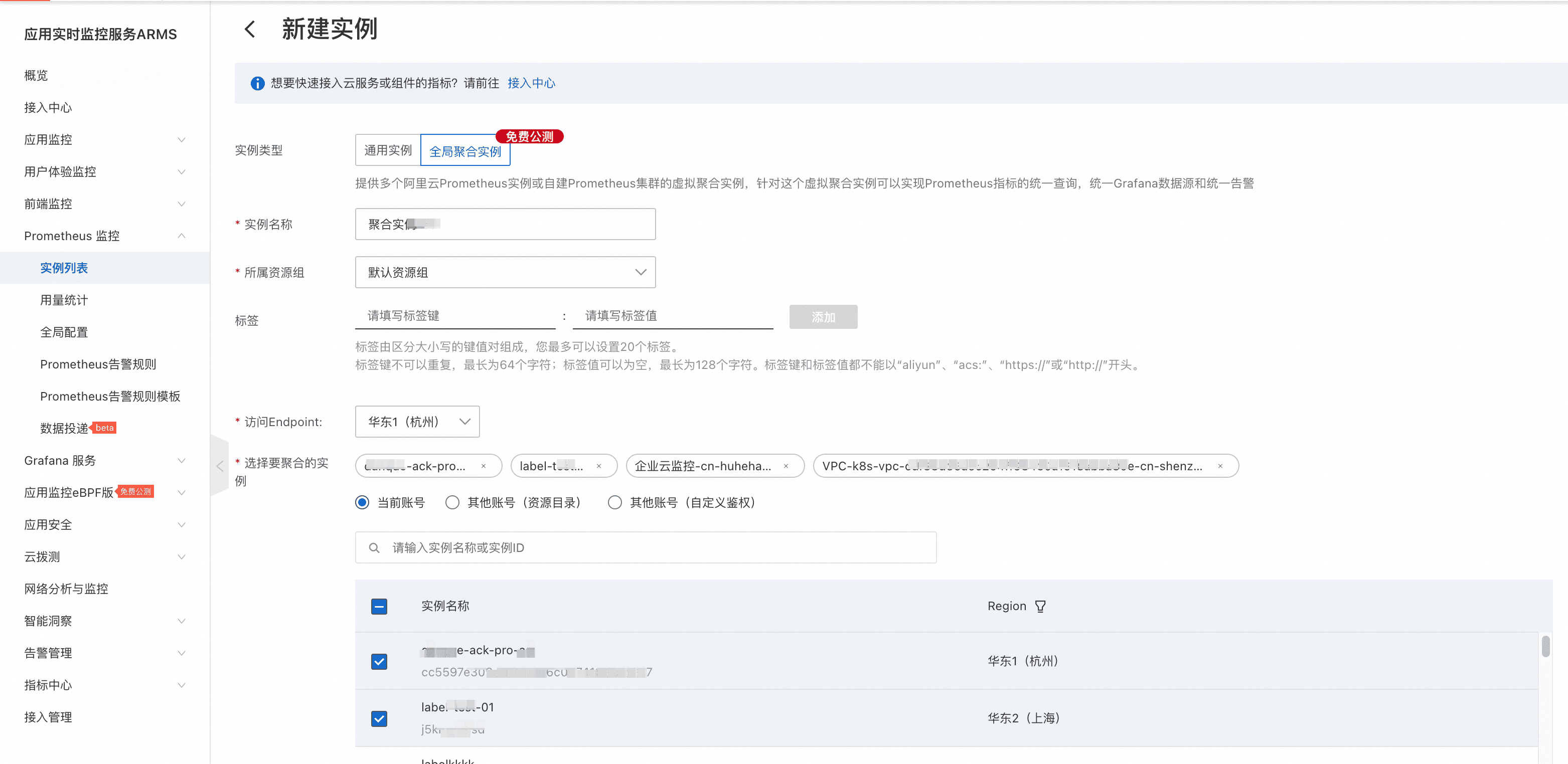
- 对于期望将多个容器/Kubernetes/ECS/IDC的监控数据进行聚合展示的场景,使用阿里云Prometheus的全局聚合实例能力即可轻松实现。

**步骤三:告警配置迁移**
与可视化分析迁移一样,在指标采集迁移过程中,涉及到的容器集群和各个常用组件(如Mysql、Redis等),阿里云Prometheus也已创建了专业的、开箱即用的告警规则。
- 对于容器/Kubernetes和ECS接入场景,在阿里云Prometheus控制台的“接入管理”的“已接入组件”界面,点击对应组件的“告警列表”即可查看该组件默认生成的告警规则。
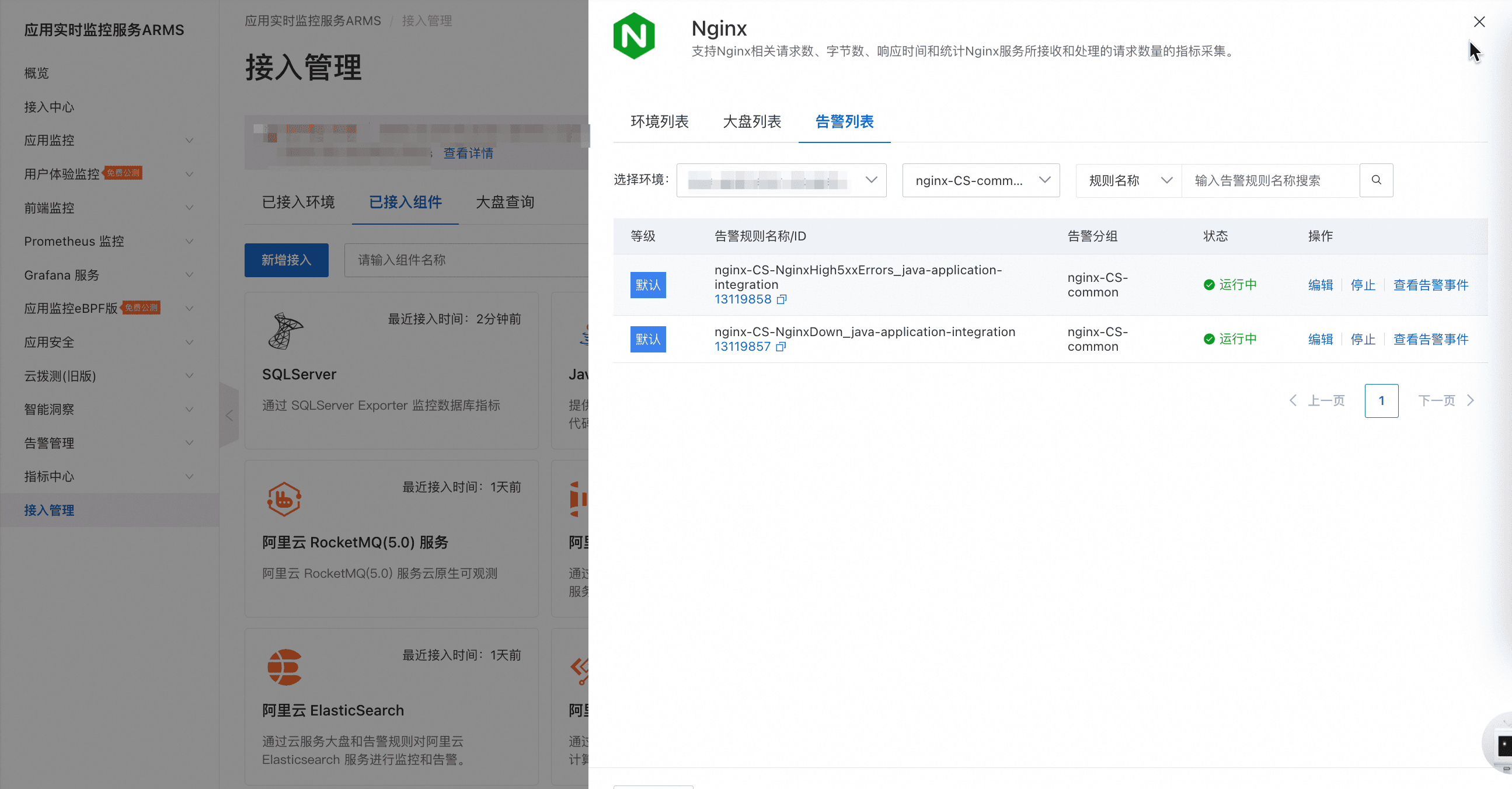
- 对于用户自定义告警规则,可在阿里云Prometheus控制台的“Prometheus监控”的“Prometheus告警规则”菜单创建和管理,或通过“Prometheus告警规则模板”导入已有的Prometheus告警规则。

- 对于期望将多个容器/Kubernetes/ECS/IDC的监控数据进行聚合告警的场景,使用阿里云Prometheus的全局聚合实例能力即可方便快捷地实现。

**关于阿里云**可观测监控Prometheus版
阿里云可观测监控Prometheus服务是基于云原生可观测事实标准 - Prometheus开源项目构建的全托管观测服务。默认集成常见云服务,兼容主流开源组件,全面覆盖业务观测/应用层观测/˙中间件观测/系统层观测。通过开箱即用的Grafana看板与智能告警功能,并全面优化探针性能与系统可用性,帮助企业快速搭建一站式指标可观测体系。助业务快速发现和定位问题,减轻故障给业务带来的影响,并免去系统搭建与日常维护工作量,有效提升运维观测效率。
与此同时,阿里云可观测监控Prometheus作为阿里云可观测套件的重要组成部分,与Grafana服务、链路追踪服务,形成指标存储分析、链路存储分析、异构构数据源集成的可观测数据层,同时通过标准的PromQL和SQL,提供数据大盘展示,告警和数据探索能力。为IT成本管理、企业风险治理、智能运维、业务连续性保障等不同场景赋予数据价值,让可观测数据真正做到不止于观测。