**简介**
你是否遇到过这样的场景:需要快速迁移历史日志、补录数据、处理一批静态文件,却苦于传统采集工具“常驻监控,仅采集增量数据”的不便?LoongCollector 推出的 一次性文件采集,正是为这类需求量身打造的解决方案。
LoongCollector 是阿里云日志服务推出的一款集性能、稳定性和可编程性于一身的新一代数据采集器,专为构建下一代可观测 Pipeline 设计。LoongCollector扩展融合了可观测性技术栈,改变传统日志采集器的单一场景限制,支持Logs、Metrics、Traces、Events、Profiles 的采集、处理、路由、发送等功能。商业版:https://help.aliyun.com/zh/sls/what-is-sls-loongcollector/,开源版:https://github.com/alibaba/loongcollector。
与常规持续采集不同,一次性文件采集配置会在启动后 一次性扫描匹配文件、完成读取、自动结束,无需人工盯守。它适用于历史文件迁移、数据补录、临时批处理等场景,既节省资源,又能确保数据完整上传。
**快速体验**
阿里云日志服务已上线一次性文件采集能力,只需三步,即可体验新功能:
- 登录 SLS 控制台,在 Logtail 配置页面选择“一次性配置”,点击“添加 Logtail 配置”。
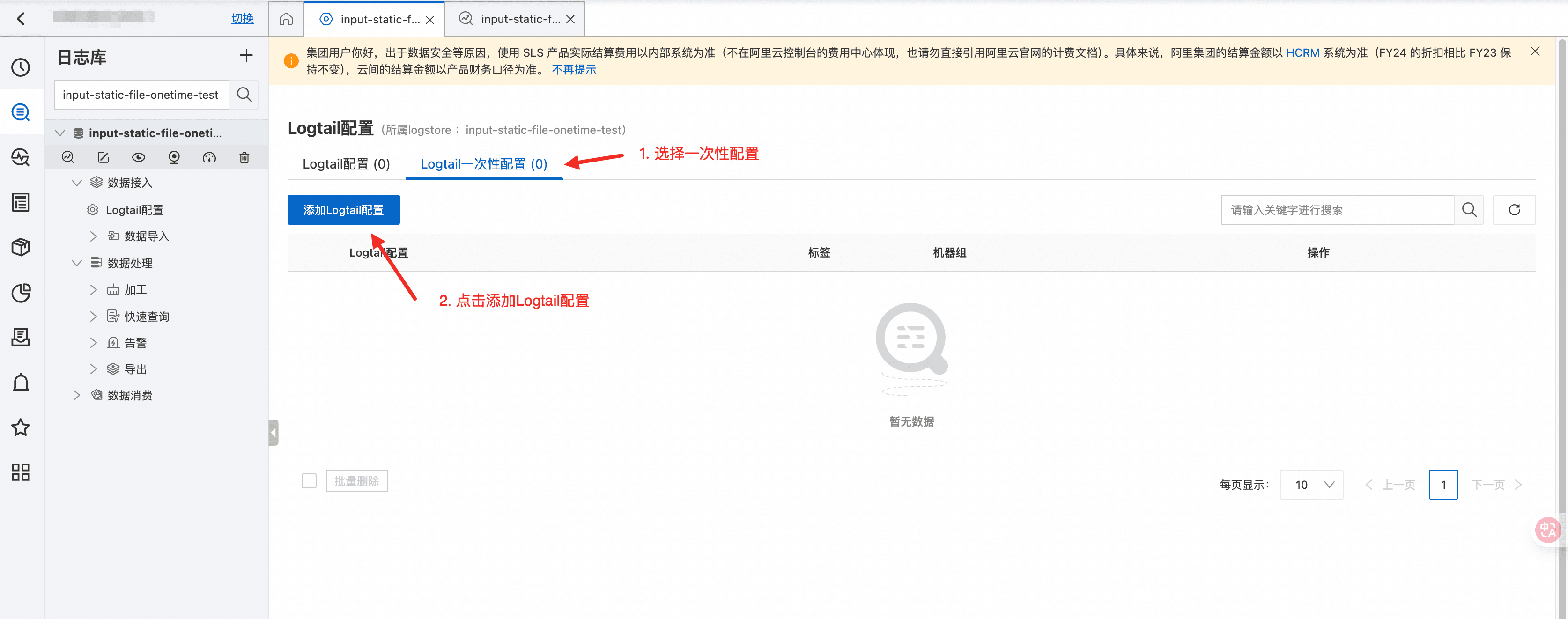
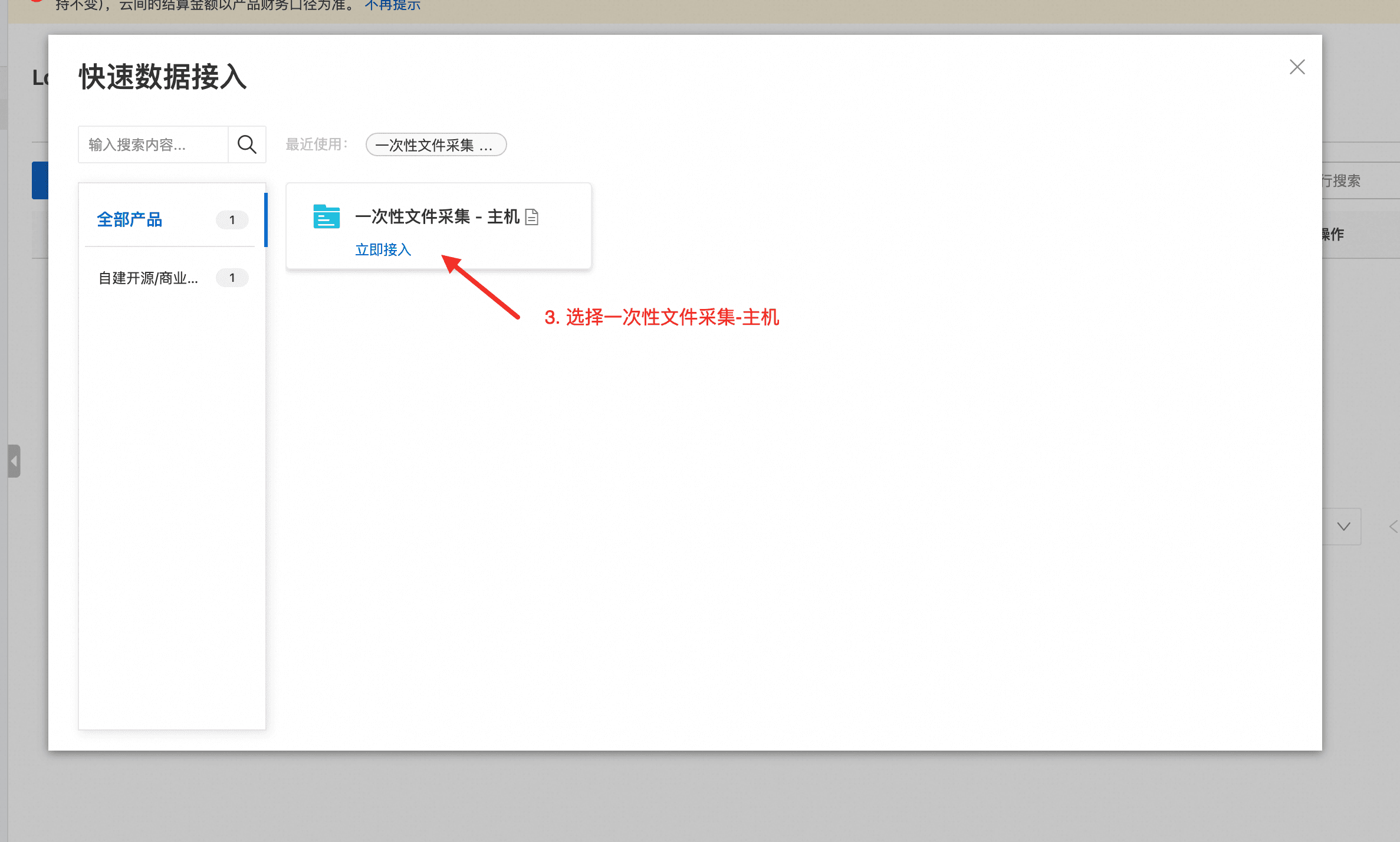
- 选择“一次性文件采集-主机”。
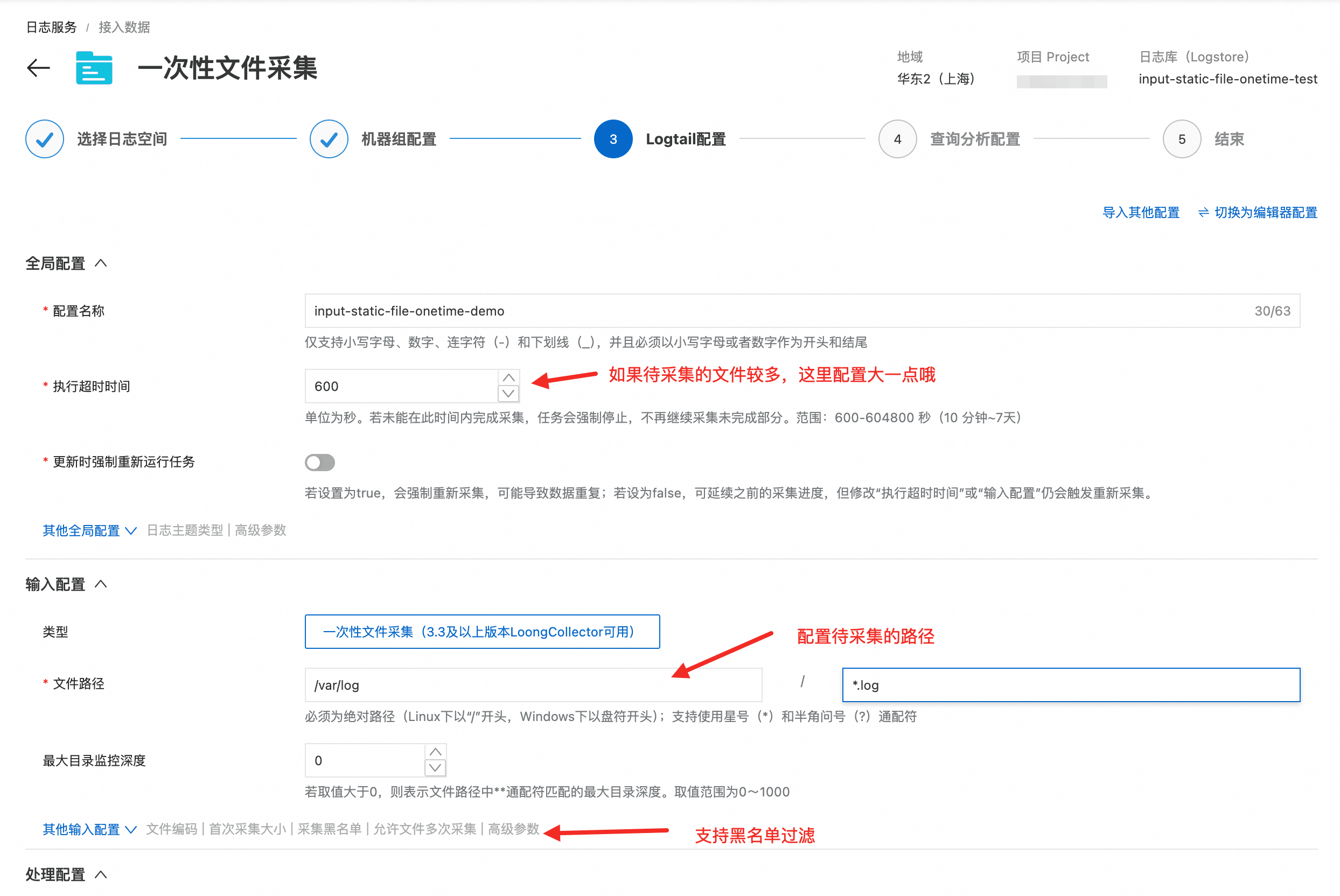
- 填写文件采集配置(与普通文件采集的配置习惯一致),按需配置处理插件后保存。更详细的说明和参数解释可以参考官网文档。
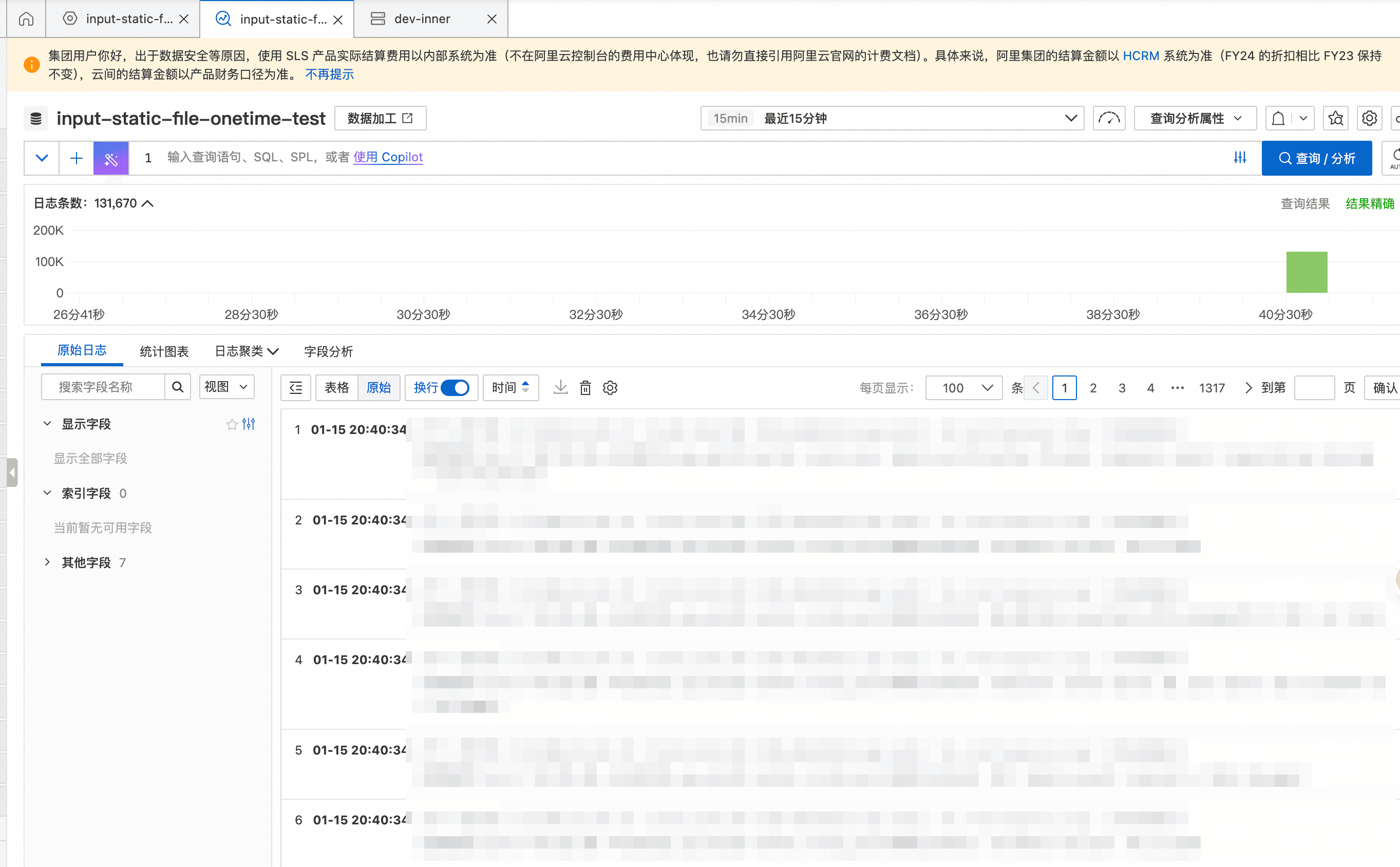
保存后即可看到数据被采集上来:
并可在配置详情里查看完整的采集配置:
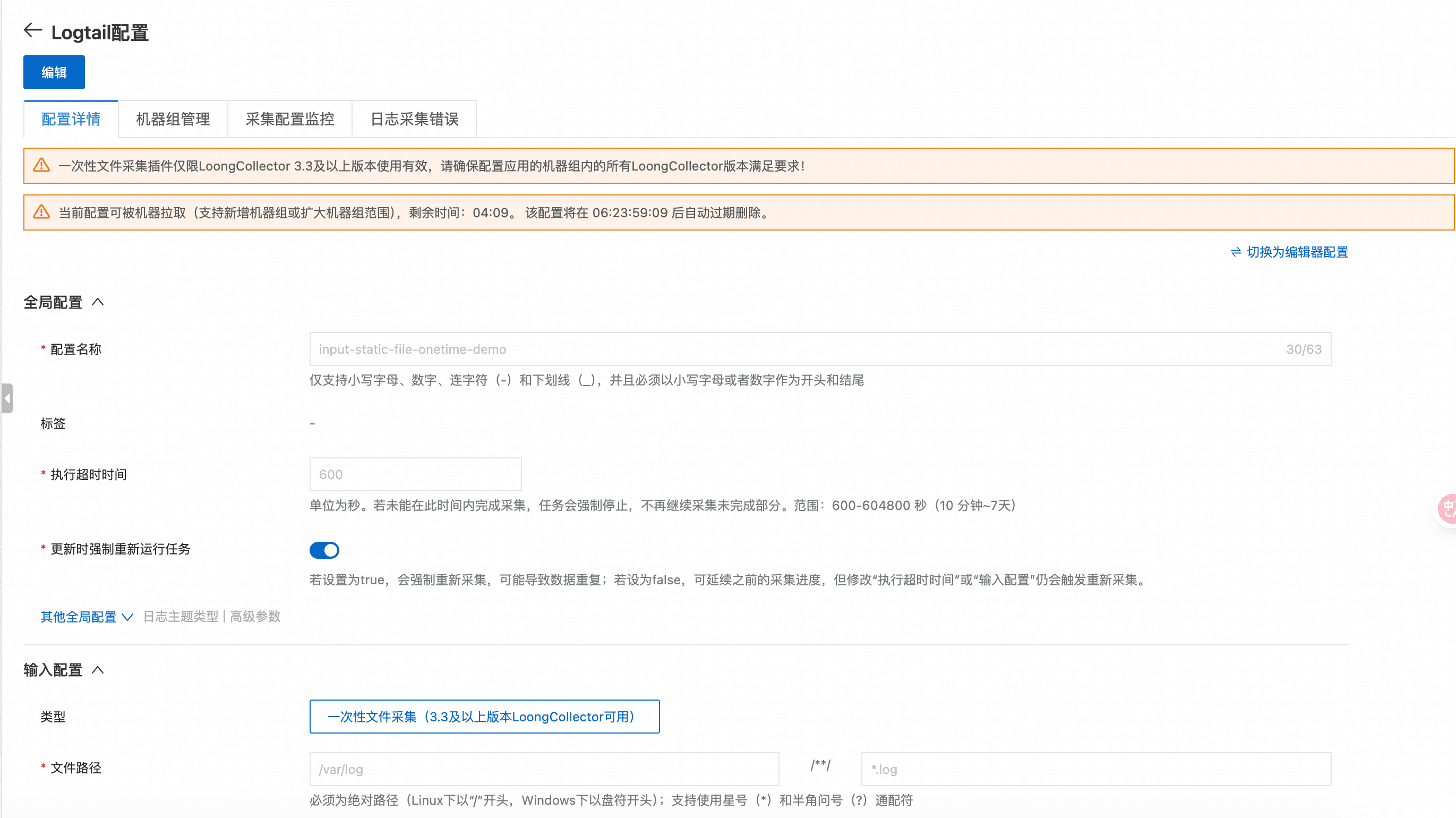
**与旧版历史文件采集的对比**
在一次性文件采集能力推出前,LoongCollector(及其前身 iLogtail) 也提供过“历史文件采集”方案(参考:导入历史日志)。相比旧方案,新版一次性文件采集配置更加简单快捷,具备更强的批量化能力与更清晰的生命周期,并通过更细粒度的 checkpoint 提升了稳定性与可观测性。
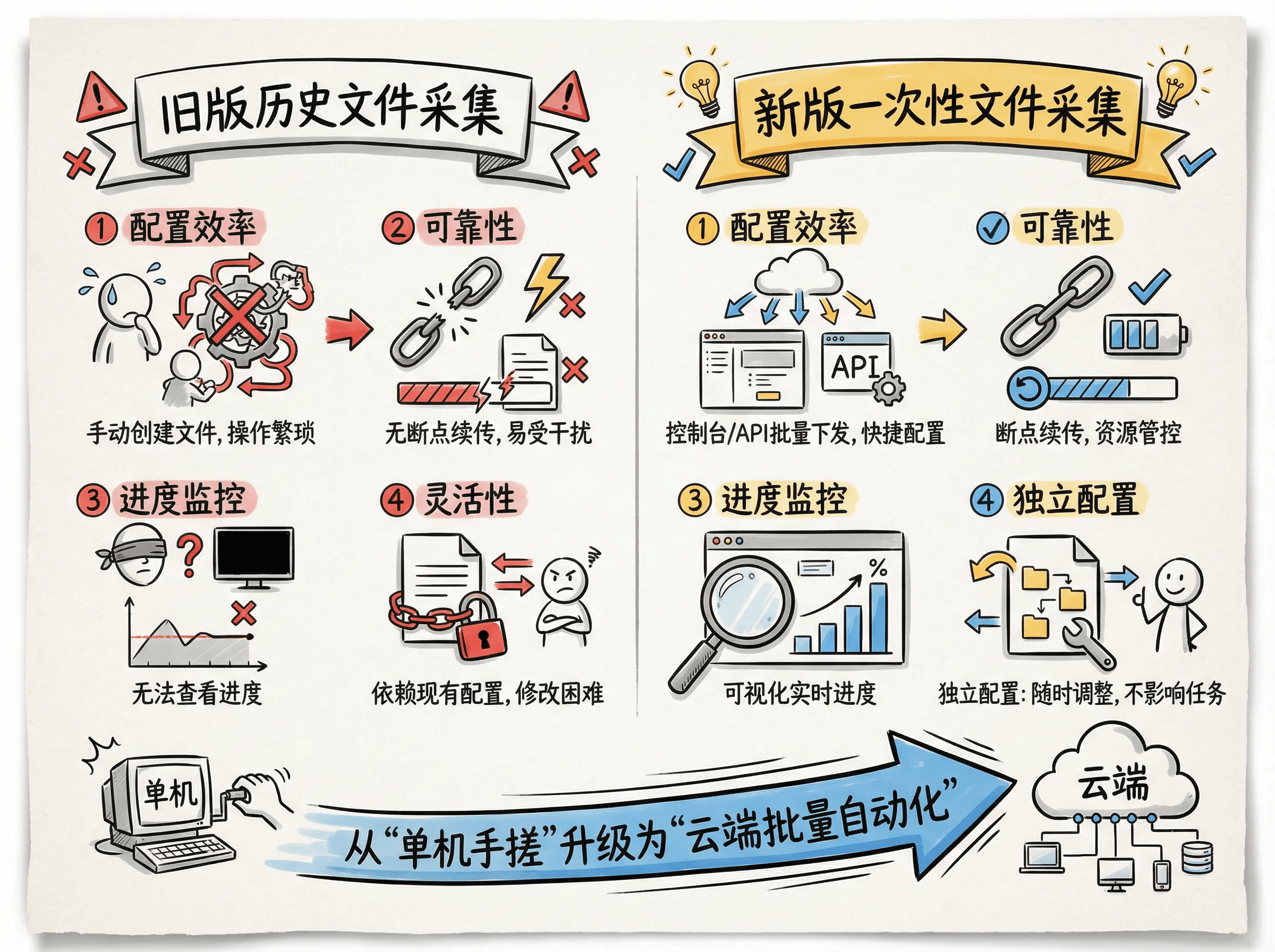
新版一次性采集让静态数据采集从“单机手动操作”升级为“云端批量自动化”,更稳定、可控、可追踪。这些优势具体是怎么实现的呢?下面来一一介绍。
**运行逻辑揭秘**
一次性(OneTime)采集配置
什么是“一次性(OneTime)”采集配置
LoongCollector 的采集流水线(pipeline)可以分为两类:
- Continuous(持续采集):常驻运行,持续发现并采集新增内容(典型如 input_file)。
- OneTime(一次性采集):启动后只执行一次,完成采集后结束(典型如 input_static_file_onetime)。
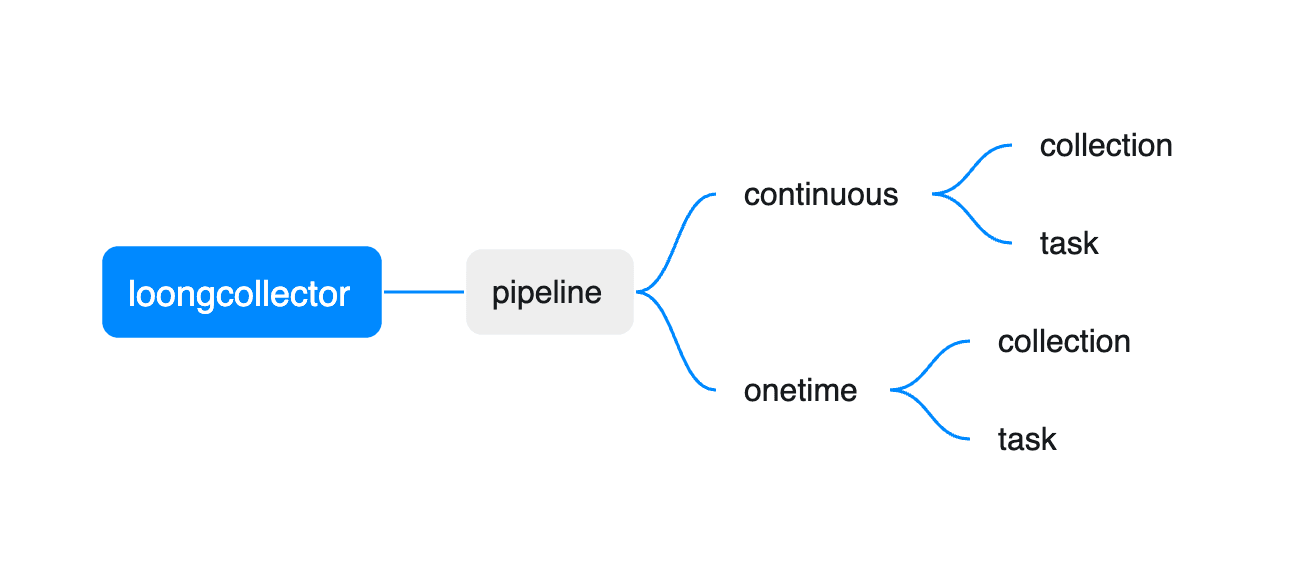
两类流水线的适用场景可概括如下:
| 常驻流水线(Continuous) | 一次性流水线(OneTime) | |
|---|---|---|
| 数据采集 | 日志/指标/Trace/事件等持续采集 | 历史日志导入、批量补录、目录结构预览等 |
| 运维任务 | 探针安装、后台升级 | 一次性诊断、临时任务 |
如何区分 OneTime 采集配置
在客户端侧,OneTime 流水线的“开关”是 global.ExcutionTimeout。
- 当配置中存在 global.ExcutionTimeout 时,LoongCollector 会将该 pipeline 识别为 OneTime,并计算其过期时间。
- 除了 global.ExcutionTimeout ,inputs 插件也需要是一次性的输入插件(通常为 _onetime 结尾),否则配置也无法生效。本文中,我们使用 input_static_file_onetime 插件来执行“一次性文件采集”。
对比示例如下:
普通文件采集
enable: true
inputs:
- Type: input_file
FilePaths: - /var/log/*.log
flushers: - Type: flusher_stdout
OnlyStdout: true
Tags: true
一次性文件采集
enable: true
global:
ExcutionTimeout: 3600
inputs:
- Type: input_static_file_onetime
FilePaths: - /var/log/history/*.log
flushers: - Type: flusher_stdout
OnlyStdout: true
Tags: true
OneTime 的执行窗口与过期机制
一次性采集流水线要“讲透”,需要同时把服务端/控制台侧的配置生命周期,与客户端侧的执行与可靠性机制对齐起来。可以把它理解为:
- 服务端/控制台侧:决定配置什么时候下发、保留多久(影响“哪些机器能拿到配置、多久还能拿到配置”)。
- 客户端侧:决定配置拿到后怎么跑、跑多久、如何断点续采(影响“能否完整采完、重启后是否漏采/多采”)。
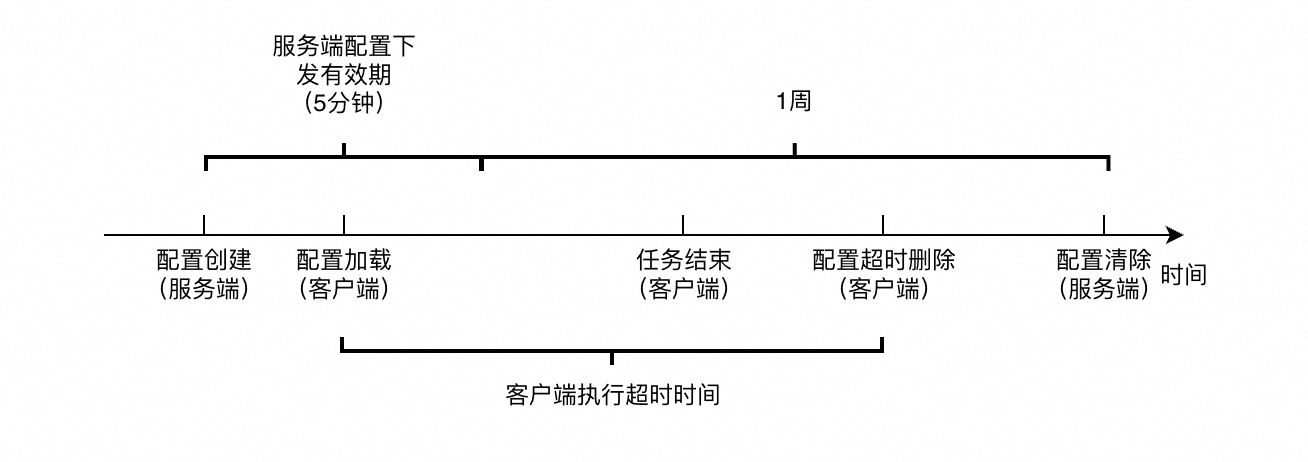
服务端:下发窗口、执行窗口、保留期限
一次性采集配置在控制台侧通常包含三个关键时间点:
- 配置下发窗口:仅向配置创建后的一段时间内上报过心跳的机器下发配置(5 分钟;更新配置会刷新窗口)。
- 配置执行窗口:配置生效后,允许配置运行的最长时间为配置的执行超时(即 global.ExcutionTimeout,默认 10 分钟,范围 10 分钟~1 周)。
- 配置保留期限:服务端侧保留配置一段时间用于追溯或复用(7 天)。
如果创建配置后再把机器加进机器组,可能已经错过下发窗口;数据量很大时,要提前把 ExcutionTimeout 调大,避免配置还没采完,就到达执行窗口时间上限,导致数据采集中断。
客户端侧:执行与过期
- 超时范围与默认值:global.ExcutionTimeout 的单位为秒,范围限制在 600~604800(10 分钟~1 周) 之间。
- 过期行为:对于 OneTime 配置,客户端会计算并记录过期时间(start + ExcutionTimeout)。当配置过期时,客户端会清理过期配置文件并移除其状态记录。
- 配置更新是否“重跑”(避免误采/重复采):OneTime 配置更新时,客户端会结合以下因素判断是否需要“重新执行一次”:global.ForceRerunWhenUpdate 为 true 时只要配置发生任意变化就强制重跑;为 false(默认) 时则以 inputs 的 hash 与 ExcutionTimeout 是否变化来判断——两者都未变化则不重跑并沿用原过期时间,否则按“新的一次性配置”处理。
OneTime 的设计目标之一就是“避免重复执行相同配置”,因此更新策略会尽量做到可控重跑。
**一次性文件采集**
一次性文件采集的“快照语义”
input_static_file_onetime 的核心语义可以概括为三点:
- 启动时一次性发现文件:启动时扫描匹配路径,将“当时存在的匹配文件列表”固化到 checkpoint;后续新增文件不会被纳入本次采集目标。
- 只读取启动时刻的文件大小:每个文件会记录一个 initial size,采集过程中即使文件被追加写入,本次也只读取到 initial size 为止(避免边采边写带来的不可控重复/漏采)。
- 支持轮转定位:文件 fingerprint 包含 dev、inode、sig_hash、sig_size 等信息,其中 sig_hash/sig_size 来自 文件开头最多 1024 字节 的签名;当文件轮转导致路径变化时,客户端会尝试在目录中按 dev+inode 查找并继续读取,尽可能避免漏采。
一次性文件采集的可靠性(checkpoint 机制)
一次性文件采集通过 checkpoint 记录“配置级别状态 + 文件级别进度”,以支持重启/升级/异常恢复,并尽量避免重复采集。
配置级 checkpoint
该文件用于记录 OneTime 配置的核心信息(如 config_hash、expire_time、inputs_hash、excution_timeout 等),用于在重启后恢复 OneTime 配置的过期时间与更新策略判断,路径通常位于/etc/ilogtail/checkpoint/onetime_config_info.json
文件级 checkpoint
该文件记录一次性文件采集的执行进度与每个文件的状态。路径通常位于:/etc/ilogtail/checkpoint/input_static_file/{config_name}@0.json
字段说明(与实际落盘 JSON 对齐):
| 参数名 | 参数解释 | |
|---|---|---|
| config\_name | 采集配置名 | |
| expire\_time | 采集配置的过期时间(Unix 秒) | |
| file\_count | 要采集的文件数量(启动时刻快照) | |
| start\_time | 采集开始的时间(Unix 秒) | |
| finish\_time | 采集完成的时间(Unix 秒) | |
| status | 采集配置状态:running / finished / abort | |
| current\_file\_index | running时,当前处理到的文件索引 | |
| files | filepath | 文件路径(启动时刻的绝对路径) |
| sig\_hash/sig\_size | 取文件开头最多 1024 字节计算文件签名hash,并记录签名长度 | |
| dev/inode | 设备号与 inode,用于轮转定位 | |
| status | 文件状态:waiting / reading / finished / abort | |
| size | 启动时刻的文件大小(本次只采集到该位置) | |
| offset | 采集偏移量(reading/abort 时存在) | |
| start\_time | 文件开始采集时间(reading/finished/abort 时存在) | |
| last\_read\_time | 文件上次读取时间(reading 时存在) | |
| finish\_time | 文件采集完成时间(finished 时存在) |
{
"config_name" : "xxxx",
"expire_time" : 1768550944,
"file_count" : 1,
"files" :
[
{
"dev" : 2051,
"filepath" : "/var/log/tmpfs.log",
"finish_time" : 1768550345,
"inode" : 2888304,
"size" : 1282,
"start_time" : 1768550345,
"status" : "finished"
}
],
"finish_time" : 1768550345,
"input_index" : 0,
"start_time" : 1768550344,
"status" : "finished"
}
资源占用与吞吐控制
一次性文件采集为原生输入插件(C++ 实现),与常规文件采集共用 reader 体系,具备较好的吞吐能力,单线程采集单行文本日志的理论极限性能可以达到 300MB/s;同时也对资源占用做了“可控”的约束:
- 单线程顺序执行:所有 input_static_file_onetime 采集配置由 LoongCollector 内部的 StaticFileServer 模块统一调度,整体为单线程循环处理(不同 input 在循环中分配时间片),避免并发过高导致资源失控。
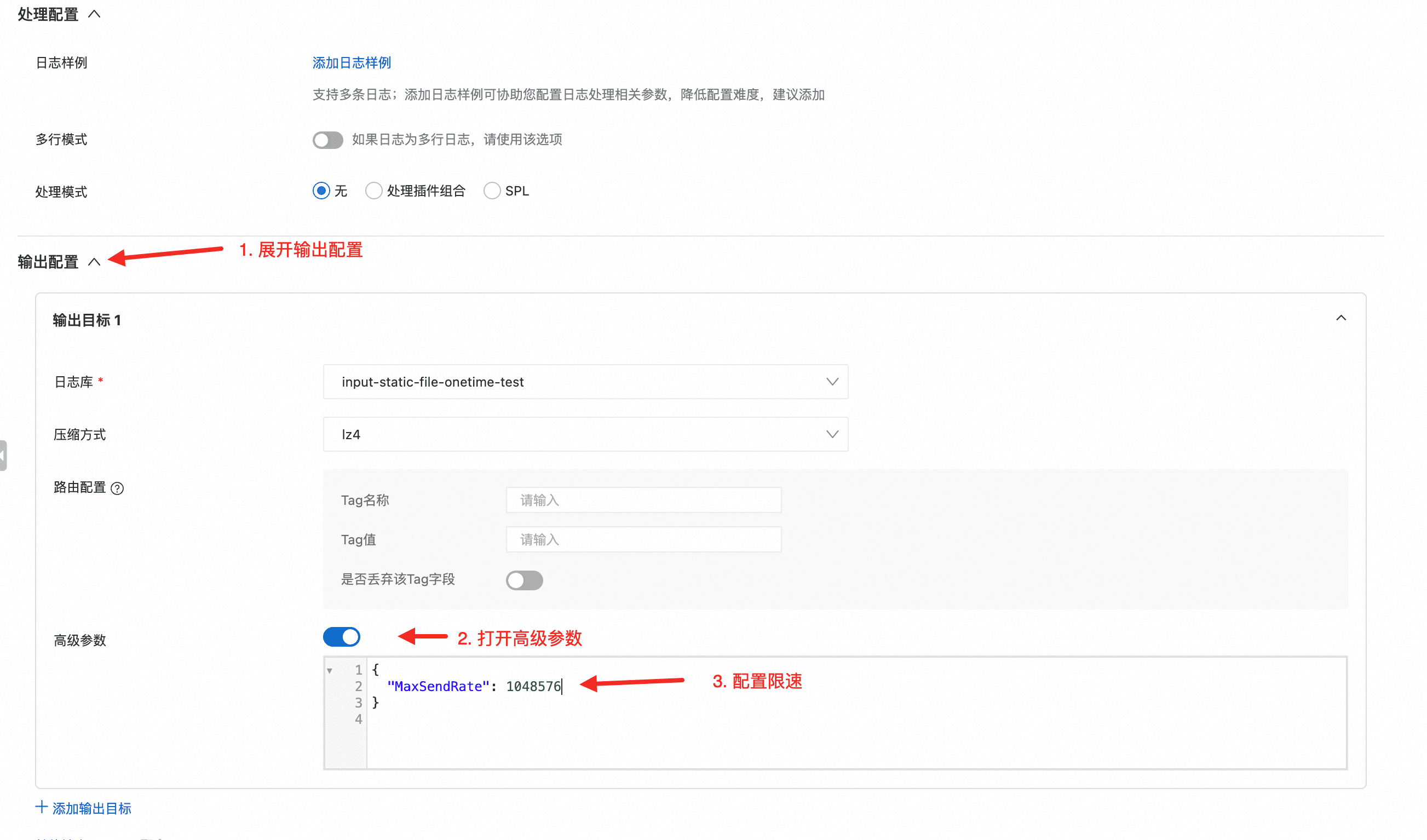
- 发送限流(flusher_sls.MaxSendRate):可通过 SLS 输出的高级参数 MaxSendRate 做发送速率限制,单位为 B/s。当 MaxSendRate > 0 时,发送队列会启用 rate limiter,从而降低对网络带宽、SLS 写入配额的冲击。
**最佳实践建议**
**场景一:大规模机器组补采大量文件**
假设场景:
- 由于意外断网过久,超过了 LoongCollector 本地容错限制,1000 台节点需要补采数据,每台补采约 10 GB;
- 目标 Logstore 有 256 个 shard,每个 shard 写入上限约 5 MB/s;
- 每台机器的日常流量约 1 MB/s。
如果直接使用默认参数下发一次性文件采集配置,可能出现:
- 写入速率瞬间冲高,触发 shard write quota 报错;
- 补采流量挤占日常采集流量;
- 发送端积压导致 OneTime 任务在 ExcutionTimeout 内无法完成。
建议做两步控制:
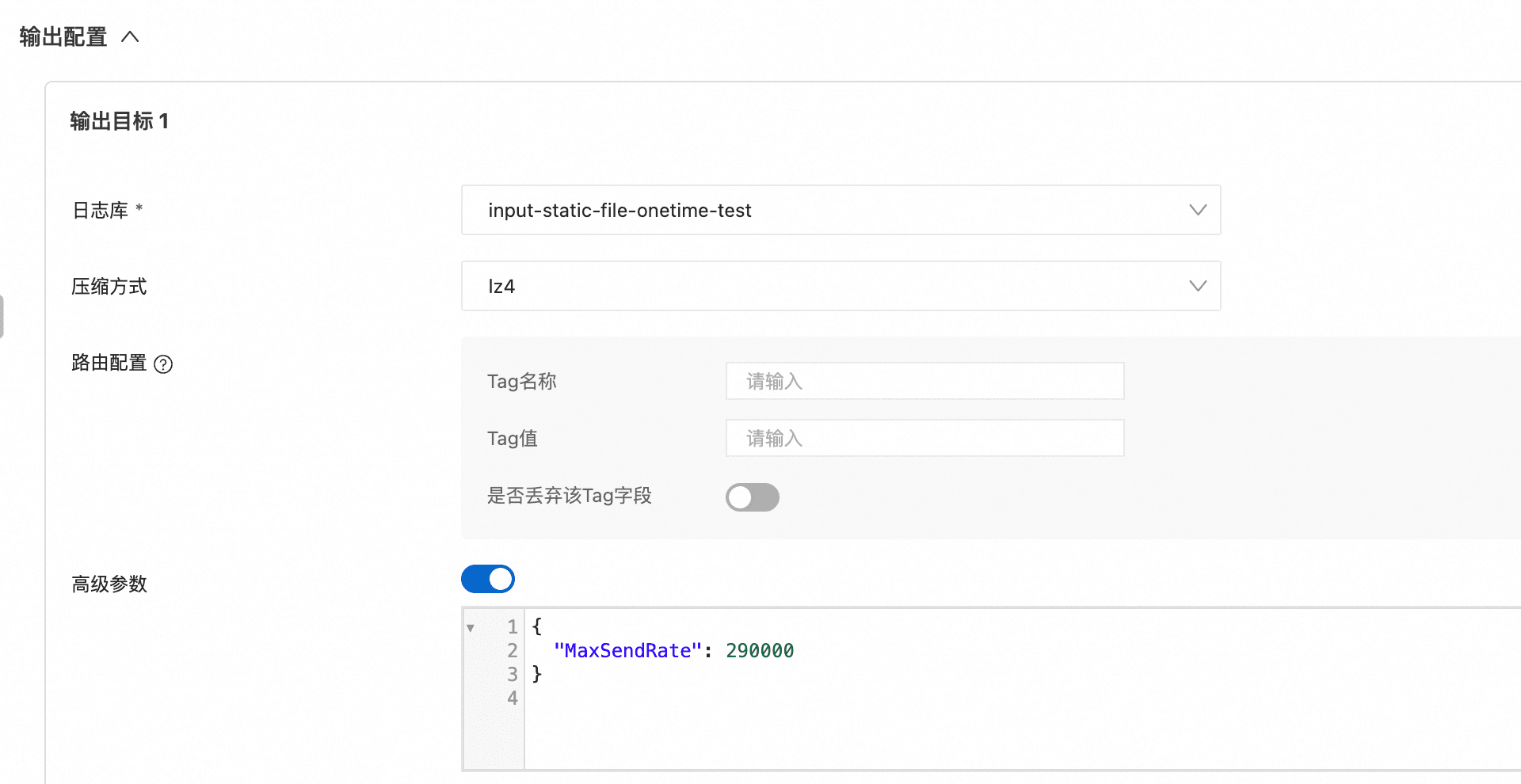
第一步:限流(MaxSendRate)
按可用 quota 粗略估算:剩余可用写入约为 (256 * 5 - 1000 * 1 = 280) MB/s,平均到每台约 0.28 MB/s(≈ 286 KB/s ≈ 286720 B/s),取整约 290000 B/s。可将 MaxSendRate 设置为约 290000(B/s)进行限流。
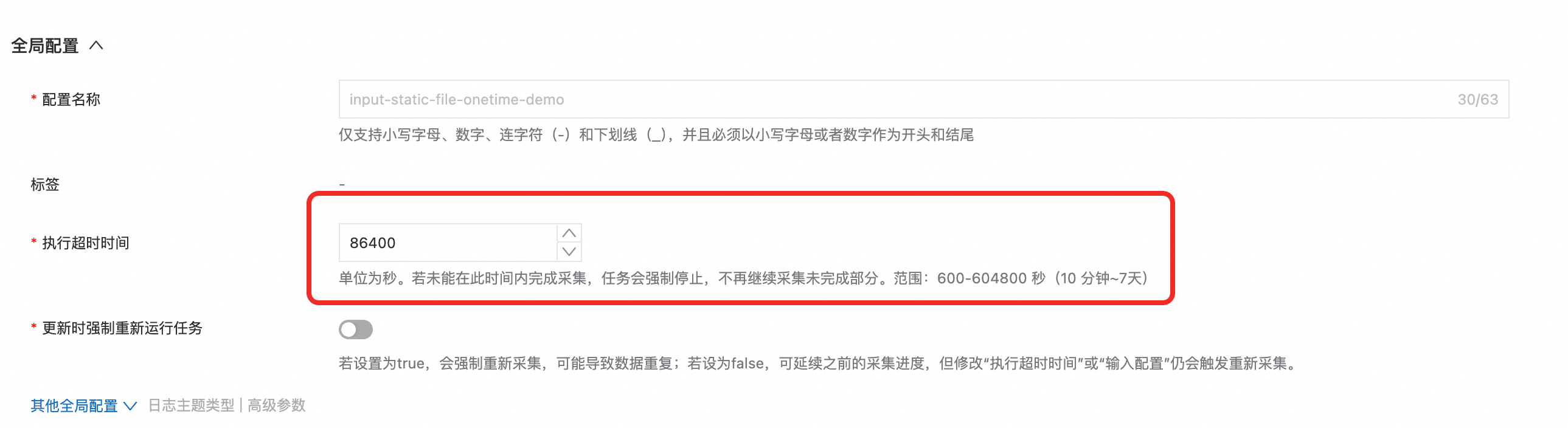
第二步:放大执行超时(ExcutionTimeout)
在 286 KB/s 的发送速率下,补采 10 GB 至少需要约 10GB / 286KB/s ≈ 36663s ≈ 10.2h。建议将 ExcutionTimeout 设置为 86400(约 1 天),给采集留出足够余量。
总结:ExcutionTimeout: 86400 + MaxSendRate: 290000,即可在尽量不影响线上日常采集的前提下完成大规模补采。
**场景二:只补采文件中某个时间段的数据**
假设场景(不考虑配额,仅讨论“避免重复”):
- 节点出现网络异常过久,超过了 LoongCollector 本地容错限制,丢了约 12 小时数据;
- 节点上有多个轮转文件,很多文件只缺失一部分;
- 日志为一行 JSON,包含
- {"timestamp":1768556120,"message":"hello world","level":"INFO"}
一次性文件采集以“文件快照”为单位执行,若直接补采,很可能把已经上报过的时间段也一起重新采集。
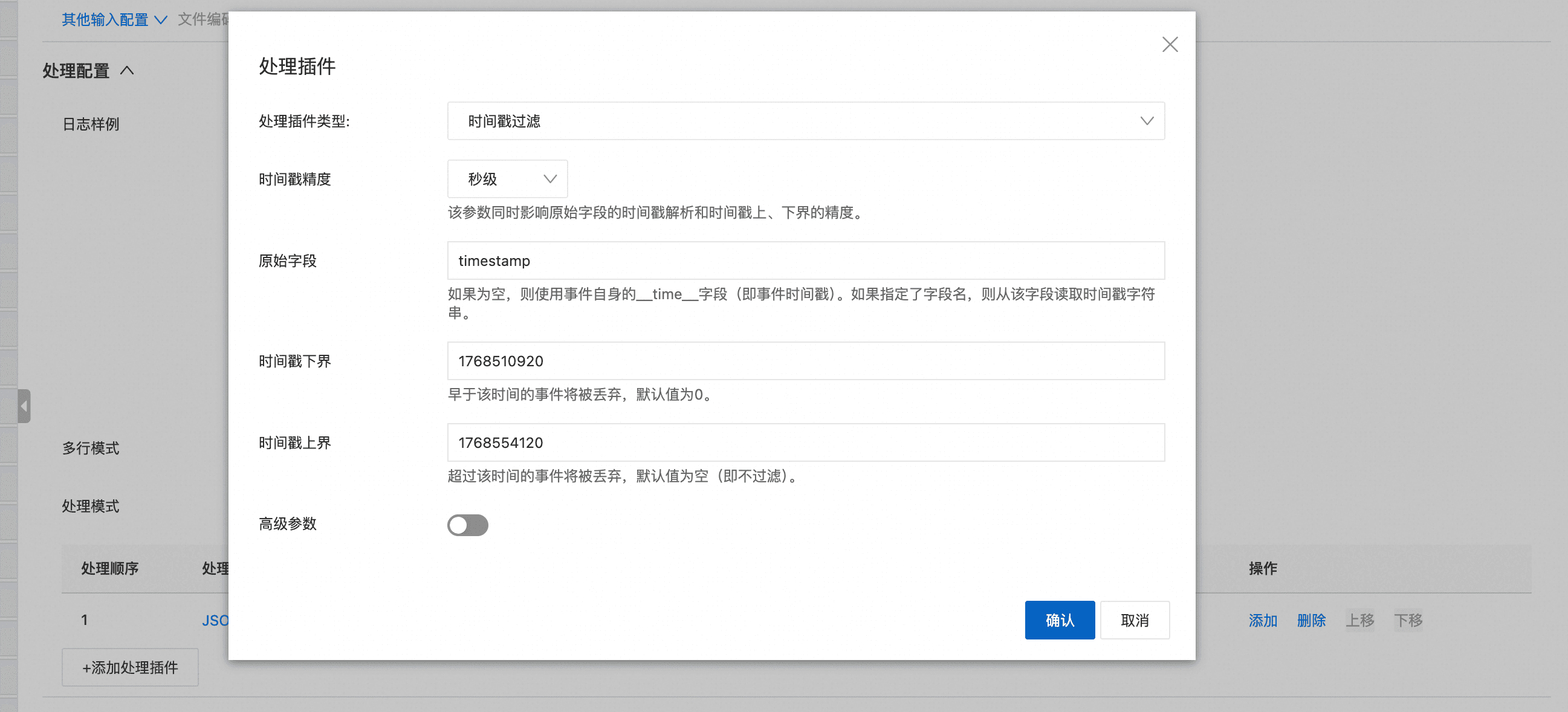
解决思路:在 OneTime 采集流水线中增加 时间戳过滤处理插件 processor_timestamp_filter_native(必要时配合 processor_parse_json_native/processor_parse_timestamp_native),只保留目标时间区间内的事件,从而实现“精准补采”。
控制台配置示意图如下:
**场景三:需要修改一次性采集配置(避免“脏数据”混入)**
一次性采集“下发即执行”,如果首次配置存在处理逻辑错误,哪怕立刻更新配置,也可能已经产生部分非预期数据,导致新旧数据混在一起影响分析。
建议做法:
- 首次创建 OneTime 配置,发现产出不符合预期;
- 更新 OneTime 配置(可设置 ForceRerunWhenUpdate: true 以强制重跑,中断之前的采集任务),验证新采集到的数据格式是否正确;如不满足要求,可反复重试。
- 使用查询语句筛选出非预期数据,并通过 日志服务软删除 清理(示例文档:日志服务软删除)。
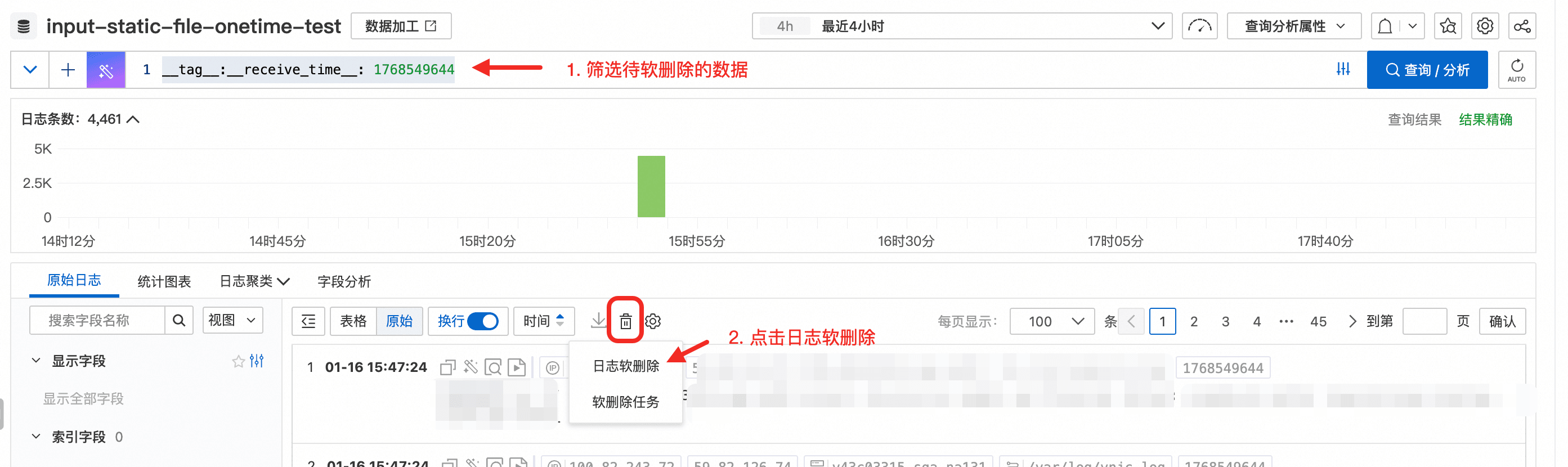

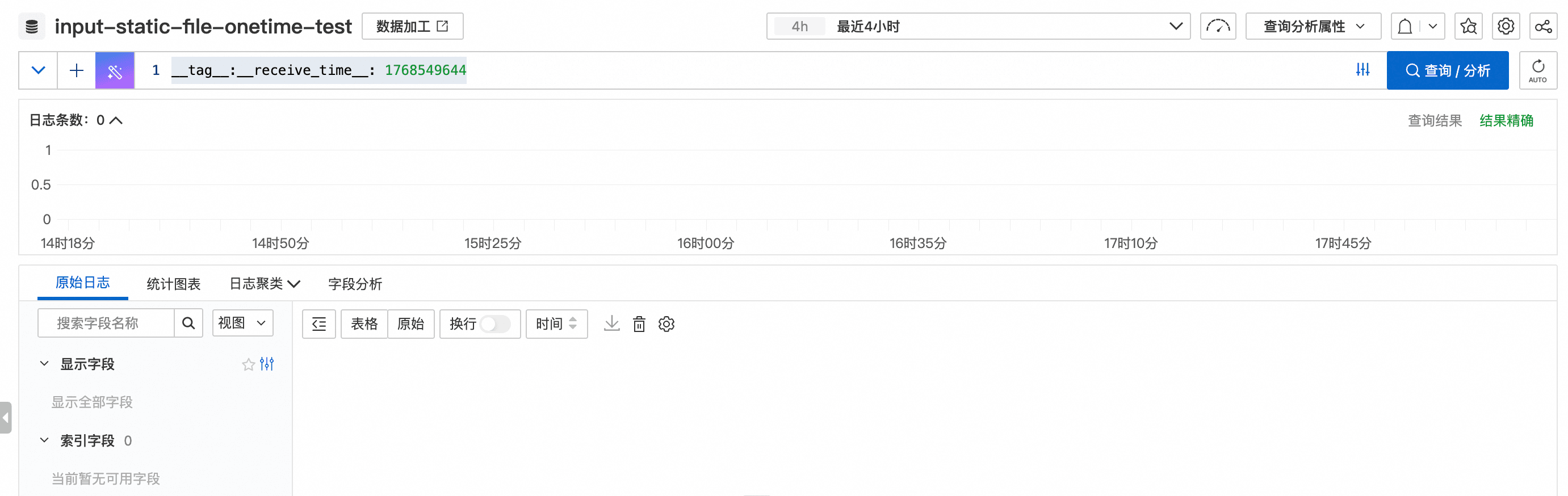
这样就可以只保留“最终正确配置”对应的采集结果,避免影响后续分析。
**总结**
一次性文件采集适合历史数据迁移、断网补采、临时批处理等场景——配置下发后按“启动时刻文件快照”执行,配合 checkpoint 保障可恢复、可观测,再结合 ExcutionTimeout 与 MaxSendRate 做好“时长 + 流量”双重兜底,就能在不扰动线上持续采集的前提下,把静态数据稳稳补齐。欢迎大家试用和反馈!