让数据说同一种语言,让智能无界协作。
2026 年 5 月 20 日,杭州 —— 在 2026 阿里云峰会上,阿里云正式开源 Unified Model(UModel),同时发起 「企业通用语义标准」(Universal Semantic Standard, USS) 行业倡议,旨在破解企业数据语义割裂的底层障碍,为 AI 规模化落地打通语义底座。
企业的每个系统都在忠实地记录事实。告警系统记录异常,日志平台保存错误样本,Trace 系统记录调用链路,Kubernetes 管理运行状态,发布系统记录变更,CMDB 维护配置关系,CRM 跟踪客户,ERP 管理订单和库存。然而,企业数字化、智能化转型正面临一个被长期低估的底层障碍——语义割裂。
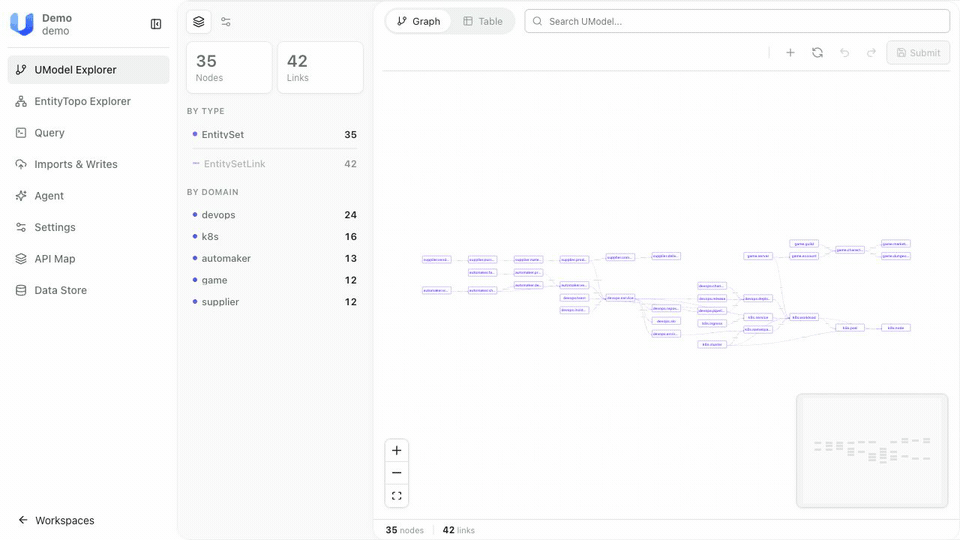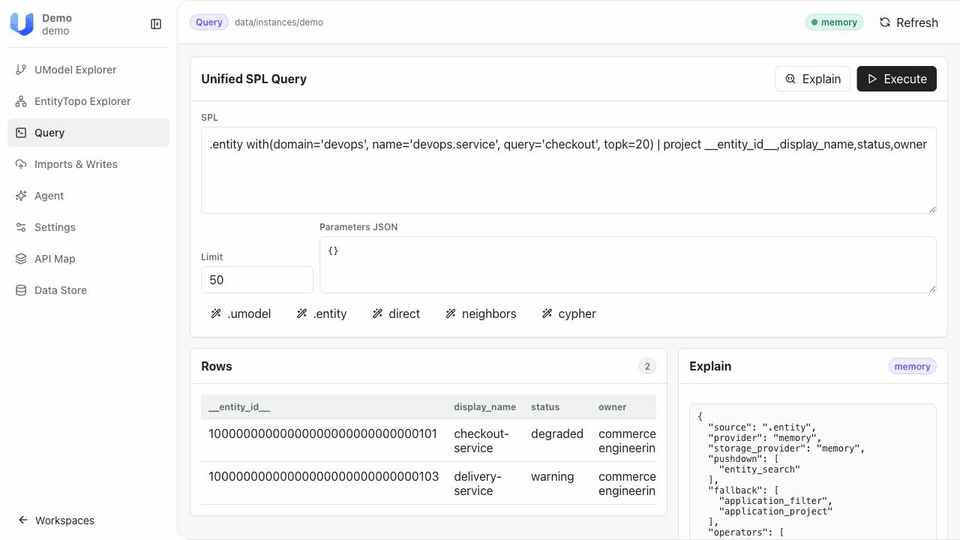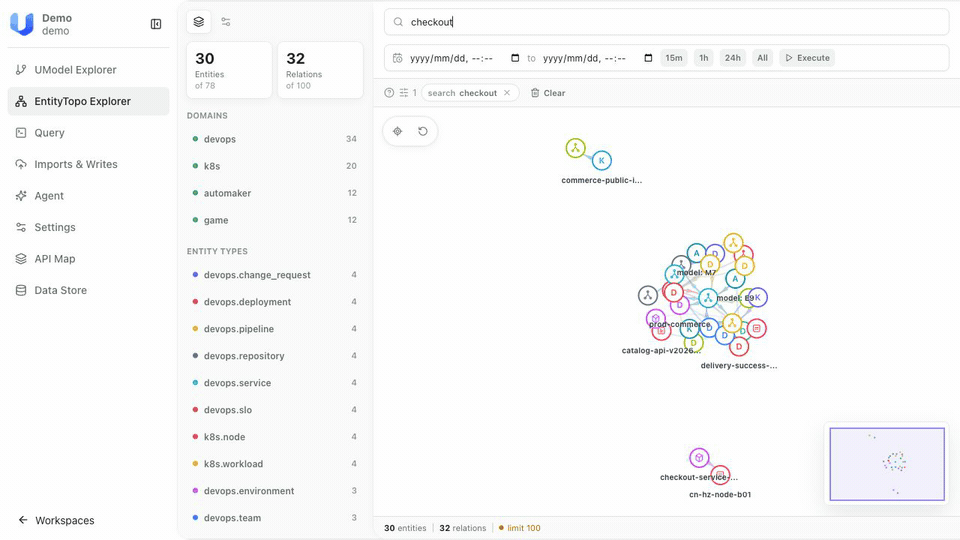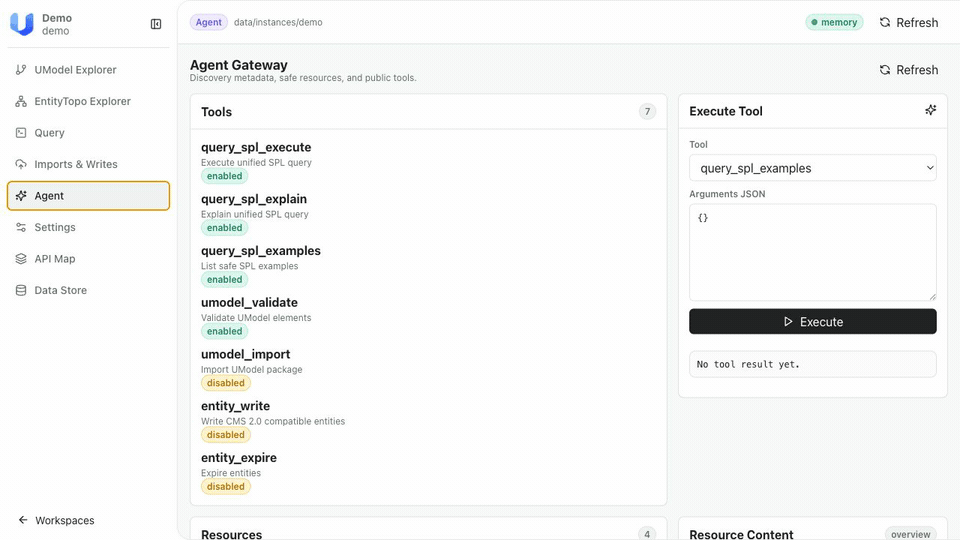
- 数据孤岛全域化:据行业机构调研,企业平均使用超过 30 种 SaaS 工具和内部系统,数据分散在运维监控、业务系统、财务平台、客户管理等上百个“数据烟囱”中。一个“checkout-service 错误率飙升”可能同时关联最近一次发布、一个下游依赖的超时、三个 Pod 的异常重启和一条 SLO 违规 —— 这些线索散落在五六个系统中,彼此之间没有统一的对象边界、关系结构和证据链。工程师靠经验在系统间跳转拼凑上下文,超过八成时间花在 “找信息” 而不是 “做判断” 上。
- 语义不一致成普遍问题:同一个“销售额”指标,财务、运营、电商各有一套——三个数字、三种含义、三套定义,却共用同一个名称。同样的问题在运维领域同样普遍:不同监控平台对“错误率”的采集方式、计算公式、时间窗口各不相同,一次跨平台的故障排查往往变成一场语义翻译的马拉松。数据分析师为了对齐“客户”这个概念在三个系统中的不同表达(account、buyer、customer_id),可能需要花两天做口径映射,才能开始真正的分析工作。
- AI 规模化落地受阻:AI 智能体在缺乏统一语义上下文的情况下,无法可靠地跨平台理解数据含义,频繁产生“幻觉”,导致智能决策质量大打折扣。过去,人的经验可以弥补这种语义缺口,代价是效率低但结果可控。但当企业开始让 AI Agent 参与运维、客服、分析和自动化决策时,这个缺口就从“效率问题”变成了“能力问题”—— Agent 可以调用十个工具,拿到十份数据,却无法判断它们是否属于同一个服务、同一次变更、同一条因果链。没有语义,AI 无法跨系统建立数据的关联与因果,只能完成单源数据的归纳,无法支撑端到端的智能决策。
- 协作成本指数级增长:跨部门、跨系统、跨工具之间因数据语义不通,沟通摩擦居高不下。一次简单的数据分析可能需要 3-5 天用于对齐口径、翻译字段、确认含义——真正用于分析和决策的时间占比不到 20%。
企业不缺数据,也不缺工具。缺的是一套让人、系统和 AI 都能理解企业世界的统一语义运行时。为解决上述问题,阿里云于 5 月 20 日的云峰会正式开源 Unified Model(简称:UModel)。
- 项目仓库:https://github.com/alibaba/UnifiedModel
- 社区文档:https://cnops.com.cn/projects/h6nsi0u0v4kronqx4r7a48dc?doc=umodel--docs-overview
一、UModel :面向企业 AI 的对象图语义运行时
UModel 作为阿里云解决上述问题构建的核心技术方案 —— 一套面向企业 AI 的对象图语义运行时,用对象和关系描述企业世界,让这些描述可以被查询、被验证、被 Agent 编程调用。它不是另一个可观测工具、CMDB 或知识图谱。它站在这些系统之上,把它们中已有的事实组织成统一的对象图。将相应能力组合在一起,让企业数据从“被各系统分别记录”变成“围绕对象被统一组织、查询、验证和调用”。针对企业的核心问题,UModel 给出了清晰的解决方案:
企业面临的核心问题 | UModel 的解决方案 |
企业有哪些对象?对象之间是什么关系? | EntitySet 定义对象类型,EntitySetLink 定义关系结构 |
这些对象对应的观测数据、业务数据存在哪里? | DataLink 绑定数据查询路径,StorageLink 绑定存储位置 |
运行时的实体与拓扑如何动态管理? | EntityStore 承载实体写入、过期和关系拓扑 |
人、系统、AI 如何统一查询这些信息? | Query Service 提供 .umodel、.entity、.topo 三类查询入口 |
AI 如何自主探索这些信息? | AgentGateway / MCP 提供 Agent-Native 的渐进式探索能力 |
如何保证不同厂商的实现都能理解同一套语义? | Conformance Case + 一致性测试验证语义互通 |
(一)UModel 的设计选择
UModel 的做法和大多数数据集成方案不同。以下三个设计选择决定了它的工程形态——先定义对象,让规范可验证,然后基于稳定的规范连接已有系统。
- 对象优先:先定义边界,再映射数据
常见的替代路径是“数据优先”——先把多个系统的数据接入同一个平台,再试图从中聚合出对象。这条路径的问题是:同一个业务实体在不同数据源中的表达不同,每次聚合都需要重新做映射,且映射结果不稳定——今天聚合出的“服务 A”和明天聚合出的可能不是同一个东西。
UModel 选择承担前置建模成本:一个对象被定义一次,无论 Pod 重建、数据源切换还是新系统接入,它的身份和关系结构都是稳定的。这份成本在多场景复用时自然摊薄——同一个 EntitySet 可以被运维 Agent、分析 Agent 和客服 Agent 共同使用。
- 规范即代码:把语义规范变成可验证的工程资产
大多数企业也有数据字典或语义规范——通常是 Wiki 页面或 Excel 表。问题在于:文档过时了不会报错,字段改名了没有 diff 提示,两个团队对同一概念的理解是否一致没有验证手段。久而久之,规范和现实渐渐脱节,成为无人信任的摆设。
UModel 把语义规范当代码管理:模型变更走 PR review,导入有 schema 校验,不同实现是否理解同一套语义用 Conformance Case 自动验证。规范不是 “写了就有”,是 “测试通过才算数”,从根源上解决了规范与现实脱节的问题。
- 连接不替换:不搬数据,只搭语义桥梁
对象图存储的是“对象是谁、关系是什么、证据在哪里可以找到”。
UModel 通过语义映射连接已有数据源 —— 描述 “对象的指标在哪里查、日志在哪里找”,而不是把数据搬过来。数据留在原地,语义组织在 UModel 中。相比把所有数据汇聚到统一平台(成本高、周期长、管道脆弱),连接已有系统的成本远低于替换它们,企业可以渐进式落地,无需重构现有 IT 架构。
(二)UModel 的技术优势
- 对象图可遍历:沿关系自动组装完整上下文
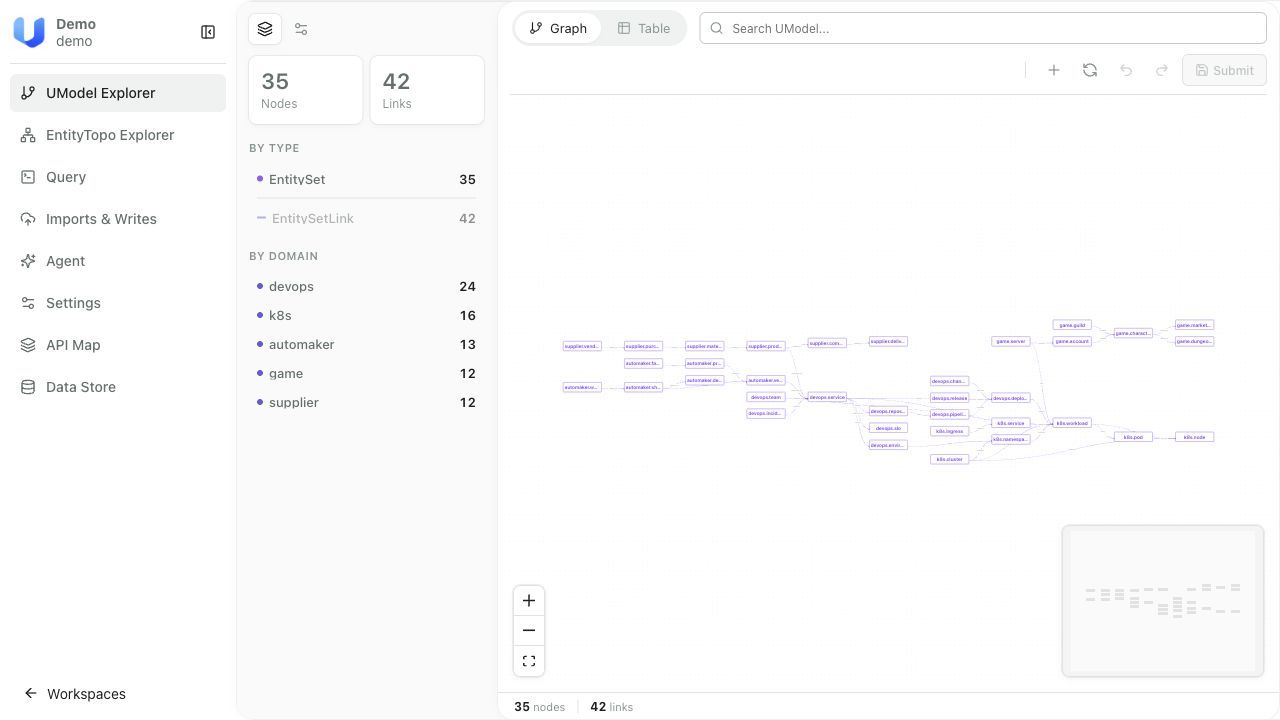
作为 UModel 最核心的技术能力。在对象图中,每个实体都通过有类型的关系连接到其他实体:一个 devops.service 关联着部署它的 devops.deployment、度量它的 devops.slo、归属的 devops.team、运行的 k8s.workload。这些关系不是文档中画的示意图——它们是运行时可查询的拓扑数据。
给定任何一个对象,通过 .topo 查询可以拓扑它的完整关系网络。Agent 不需要预先知道“排查一个服务故障应该看哪些系统”——它从故障对象出发,沿关系图遍历就能找到关联的部署、变更、SLO 违规和下游依赖。因果链是沿图结构走出来的,不依赖提示词工程猜测。
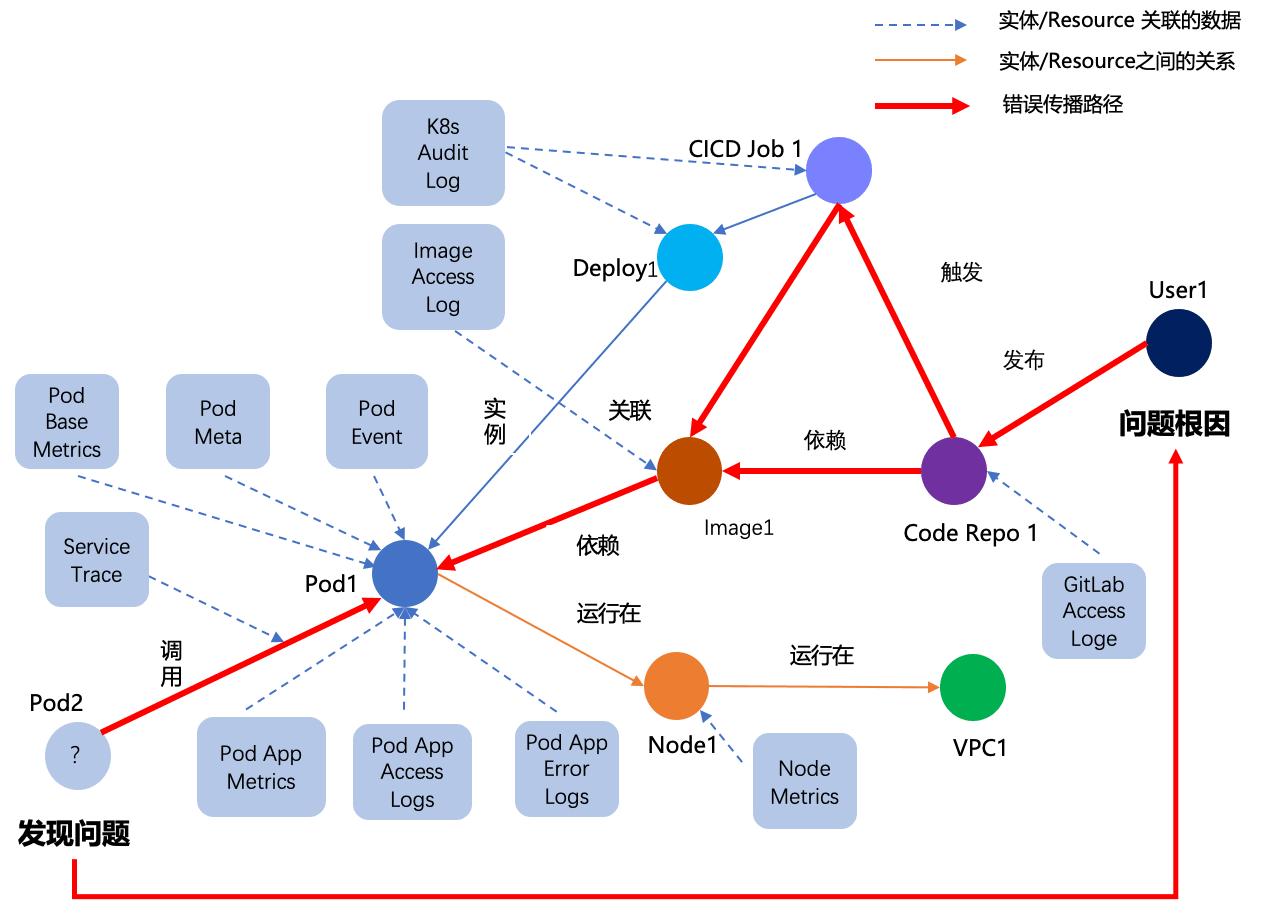
- Link 体系:把 “数据在哪里” 变成对象的属性
UModel 不只是定义了“有哪些对象”—— 通过 Link 体系把对象和它的证据完整地连接起来。DataLink 连接实体与观测数据:一个 devops.service 通过 DataLink 关联到它的指标集、日志集和 Trace 集,并通过字段映射说明如何从实体定位到具体的监控数据(例如:实体字段 service_id 对应指标标签 monitored_service_id)。StorageLink 连接数据集与物理存储:指标存在哪个 MetricStore、日志存在哪个 LogStore,由 StorageLink 描述——这让“数据在哪里”成为对象图的一部分,而非散落在配置文件或运维人员的记忆中。EntitySetLink 定义对象间的拓扑关系语义。
三类 Link 组合在一起,让对象图成为“对象是谁、证据在哪、数据怎么查”的完整语义描述。Agent 拿到一个对象后,可以沿 Link 找到它的指标、日志和 Trace 的查询路径和存储位置——即使当前需要 Agent 自己去对应数据源执行查询,它至少知道该去哪里查、用什么条件查。
- 厂商中立、规范先行:语义层不绑定任何平台
UModel 的语义定义和运行时服务都不绑定特定厂商或平台:
- GraphStore Provider 抽象了存储后端——当前提供 memory、file.memory 和 local.ladybug 三种实现,企业可以开发自己的 Provider 对接已有图数据库或存储系统。
- 多域共存——DevOps、Kubernetes、业务系统的模型可以定义在同一个 workspace 的不同 domain 中,并通过跨域 EntitySetLink 建立关联。前面对象图可遍历的示例中,devops.service → k8s.workload 就是一个跨域关系。
- 模型定义和公共契约(OpenAPI、MCP schema、SDK types)都是标准格式文件,不依赖特定工具链。
这种设计让企业可以渐进式采用:先为一个领域定义模型,验证价值后再扩展到其他领域——语义层的演进不受底层存储变更或平台切换的影响。
(三)Umodel 演进路线规划
本次开源与发起倡议只是 UModel 的第一步。以下能力已在内部验证,将在后续版本中逐步开放:
- USearch:统一语义搜索。当前 Query Service 提供了结构化的对象图查询(.umodel、.entity、.topo),适合已知对象类型和 ID 的精确访问。USearch 补充的是“根据实体字段快速定位实体”的能力——支持倒排索引精确匹配、向量语义近似搜索,以及混合检索。当 Agent 面对模糊线索(一个服务名片段、一段错误描述)时,USearch 让它能快速收敛到具体实体,再通过对象图展开上下文。
- PaaS API:对象级语义查询。开源版本的 Query Service 查询的是对象图本身(模型、实体、拓扑)。PaaS 查询代理解决的是下一步问题:给定一个实体,如何获取它关联的数据?根据 DataLink 和 StorageLink 的映射关系,将“查询 checkout-service 的错误率指标”这样的对象级意图翻译成可执行的查询语句——但不负责执行。返回的查询语句交由 AI Agent 或上层系统在对应数据源中执行。
- 更多领域模型和 Provider:围绕数据库、消息队列、云产品、网络设备、业务系统等领域持续扩展模型包;同时开放更多 GraphStore Provider 实现,支持企业将对象图持久化到自己选择的图数据库或存储后端。
(四)治理模型与参与路径
UModel 目前已经正式开源:核心闭环可进行本地运行,语义规范和 Query Service 已经稳定,AgentGateway / MCP 已经可用。生产级图存储 Provider、更多领域模型覆盖和大规模性能验证是接下来需要社区共同推进的方向——这也意味着现在是影响项目方向最有效的参与窗口。
- 1 分钟:为项目点亮 Star,关注项目最新动态;
- 5 分钟:快速体验 Demo,拉取代码后执行make quickstart,打开 Web UI 浏览示例对象图,直观了解方案能力;
- 半天:提交第一个贡献,阅读 examples/quickstart-multidomain/ 中的模型定义 → 为你熟悉的领域定义 3 个 EntitySet → 补充关系和样例数据 → 提交 PR
持续贡献方向(详细贡献指南见项目文档):
- 领域模型:为数据库、消息队列、云产品、业务系统等领域贡献 EntitySet 和关系定义
- GraphStore Provider:接入新的图存储后端,推动生产级存储能力
- Agent 工具:贡献 MCP tools、查询模板和 prompts,降低 Agent 的探索成本
- Conformance Case:编写一致性验证用例,确保不同实现理解同一套语义
(五)快速体验
快速体验
本次开源提供了一个可以本地跑通的完整闭环:定义模型 → 导入 Workspace → 写入实体和关系 → 统一查询 → Agent 探索 → 一致性验证。仓库包含完整测试套件(contract / integration / e2e / golden tests)约束公共契约。
启动
make quickstart
启动后有三个入口可用:
- API:localhost:8080(REST + MCP)
- Web UI:localhost:5173(浏览对象图、执行查询、查看 Agent 工具列表)
- 预加载数据:demo workspace,包含 DevOps、Kubernetes、供应链等多域模型示例
开发者视角:CLI 与 Web UI
用 CLI 查询对象图:
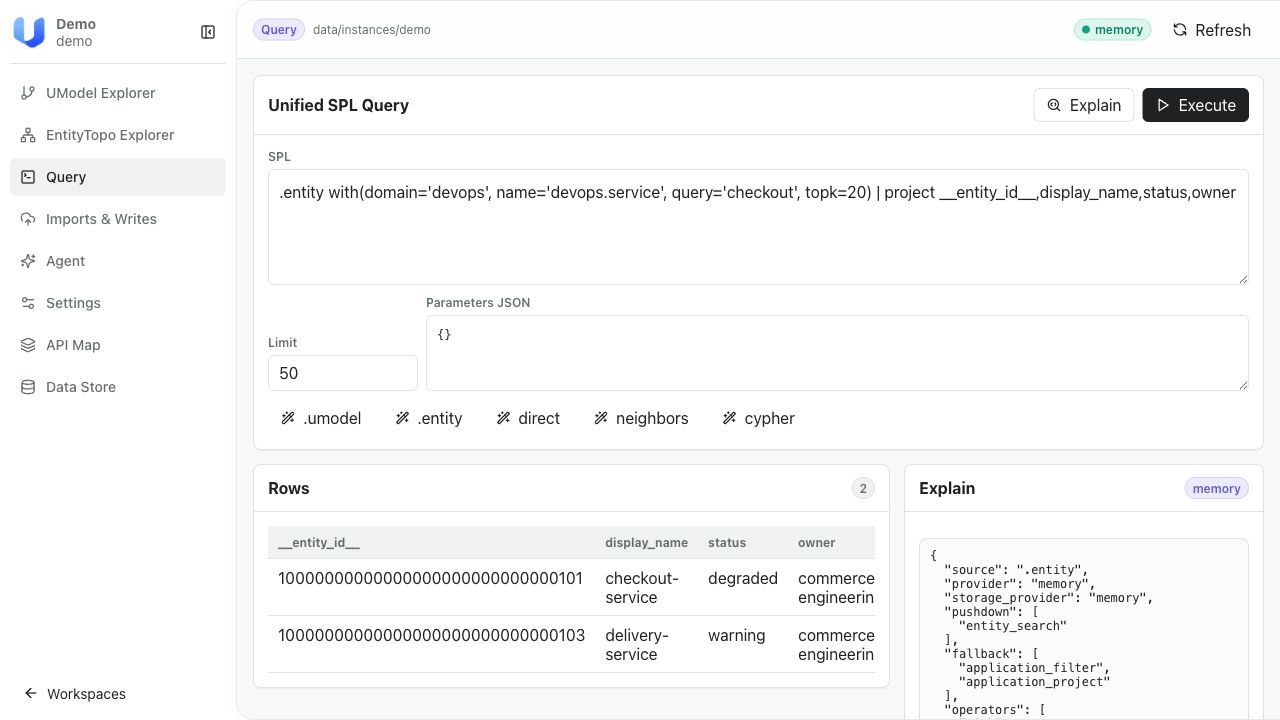
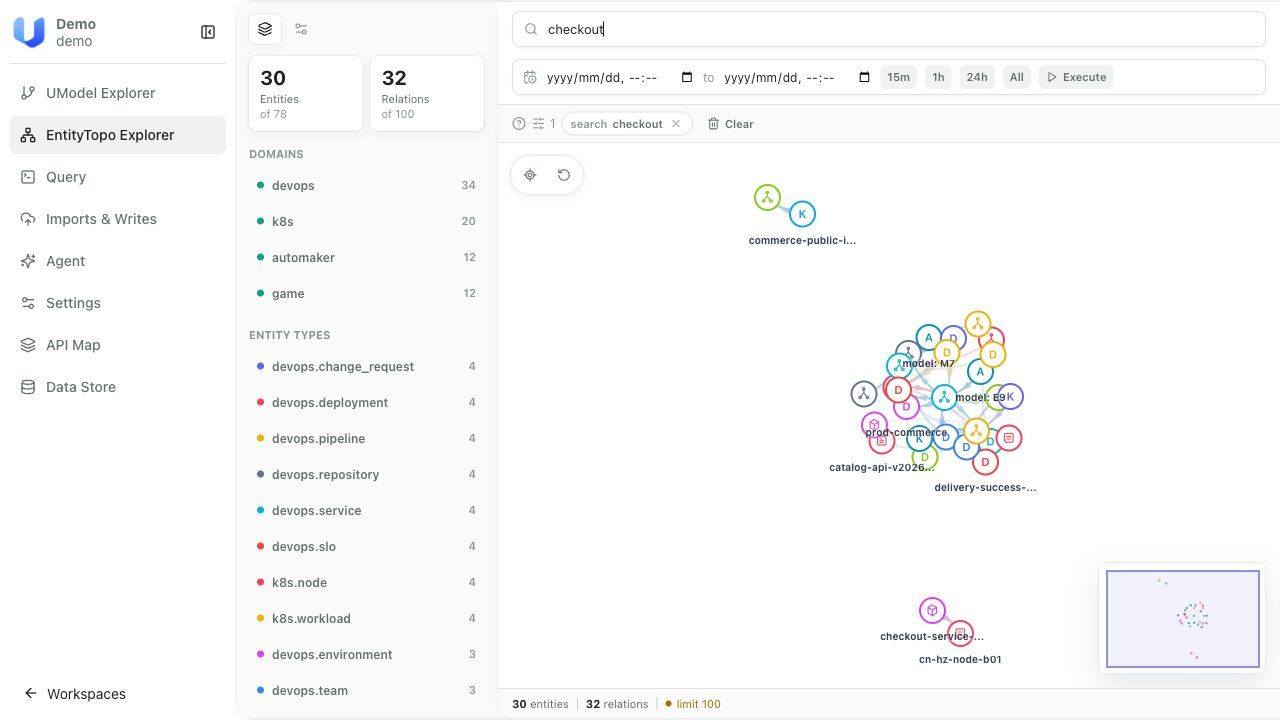
# checkout-service 这个对象长什么样?
umctl query run demo \
".entity with(domain='devops', name='devops.service', query='checkout') | limit 10"
# 它和哪些对象有直接关系?
umctl query run demo \
".topo | graph-call getDirectRelations([(:\"devops@devops.service\" {__entity_id__: '10000000000000000000000000000101'})]) | limit 10"
也可以直接打开 Web UI——在 Explorer 视图中浏览对象类型和实例,在 Query 视图中交互式执行上述查询,在 Graph 视图中可视化对象关系拓扑。完整查询语法参见文档;Agent 通过 MCP 调用时不需要手写这些语句。
AI 深度场景:Agent 通过 MCP + Runbook 系统化排查
上面的 checkout-service 例子是单因果、无干扰的——Agent 沿图走几步就能找到答案。但真实生产环境中的故障往往更复杂:原因不是一个而是多个变更的叠加,有误导性的线索干扰判断,关键证据散落在不同团队管理的不同系统中。当线索超过 5 个、涉及 3 个以上管理域时,纯粹的图遍历不够了——你需要一套结构化的诊断协议来保证排查的完整性和正确性。
场景:凌晨 02:17,payment-gateway P99 延迟突破 SLO
值班 SRE 被告警叫醒。payment-gateway 是 platinum 级服务——每分钟异常都有直接的业务损失。需要快速判断:是回滚最近的部署?扩容?还是另有原因?
时间线:
- T-24h:checkout-service 的重试配置从 2 调到 5(一个常规的配置变更,当时流量正常,没有引发问题)
- T-4h:618 促销活动激活,流量开始爬升至 3.5 倍
- T-0:告警触发,P99 延迟 > 2000ms
这件事难在哪里? 根因不是单一事件,而是两个独立变更在特定时间窗口内的叠加:配置变更单独存在不会出事(4000 × 2.5 = 10,000 QPS,容量范围内);促销流量单独存在也不会出事(4000 × 3.5 = 14,000 QPS,可接受)。但两者同时生效:4000 × 3.5 × 2.5 = 35,000 QPS,是正常容量的 8.75 倍——payment-gateway 被压垮。
更棘手的是:12 小时前有一次部署。SRE 的第一直觉一定是怀疑它——"最近改了什么"是排障的认知捷径。但这次是红鲱鱼:变更内容是日志格式调整,与延迟无关。如果凭直觉先回滚这次部署,问题不会解决,反而浪费了宝贵的时间。
而且关键线索分属不同管理域:告警和部署记录在 Platform 域(运维团队管理),促销活动在 Business 域(业务团队管理)。传统排障中,SRE 可能根本不知道有促销在进行——直到打电话问业务团队。
payment-gateway (degraded, platinum SLO)
← calls ← checkout-service
← affects ← cfg-checkout-retry (max_retries 2→5, 24h前)
← triggers ← 618 Flash Sale (3.5x traffic)
排除: payment-gw v3.2.1 (12h前, trivial logging change)
根因: 4000 × 3.5 × 2.5 = 35,000 QPS → 8.75x 过载
UModel 的回答:Runbook——Agent 可执行的诊断协议
UModel 通过 Runbook 解决这类复杂场景。Runbook 不是文档或 Wiki——它是 Agent 可以程序化执行的结构化协议,包含三个层次:
- Observation(检查什么):定义每个检查项的具体步骤——查哪些实体、沿哪些关系遍历、比对什么字段
- Conclusion(怎么判断):为每个观察定义匹配条件——满足什么条件得出什么结论、严重等级是什么
- Knowledge(为什么是问题):提供故障模式的解释和计算公式,帮助 Agent 理解而不只是匹配
不同于 RAG 让 Agent 检索文档后自行推理(容易遗漏、不可复现),Runbook 保证了两件事:完整性——不会忘记检查业务流量这个关键因子;确定性——同样的数据,不同时间、不同模型执行,结论一致。
在这个场景中,platform.service.ops Runbook 为 Agent 定义了三个 Observation:upstream_retry_amplification(检查上游重试配置)、recent_deployment_correlation(排除或确认近期部署)、business_traffic_pressure(识别业务流量压力)。Agent 按协议逐一执行,不会因为"最近有部署"就跳过后续检查。
视频:Claude Code + UModel MCP 实际排查对话
以下视频展示这个场景的完整排查过程——用户用自然语言提问,Agent 通过 MCP 连接 UModel 对象图,按 Runbook 协议系统化执行:从定位故障服务,到发现上游重试风暴,到排除无关部署,到识别跨域的促销流量叠加,最终给出根因分析。
二、从 UModel 到通用语义标准:一家企业做不完的事
阿里云服务全球超过 400 万企业客户,在可观测性、数据治理、企业智能等领域拥有深厚的产品实践。在长期服务企业客户的过程中,我们深刻感受到语义割裂对数据价值释放和 AI 落地的系统性阻碍。企业语义涉及太多领域、太多场景、太多已有系统 —— 运维有运维的对象模型,业务有业务的实体定义,每个行业又有各自的领域知识。这绝不是一家公司能够独立完成的事。我们坚信:统一与开放是释放企业全量数据价值与 AI 全部潜力的唯一钥匙。
因此,阿里云在开源 UModel 的同时,正式发起「企业通用语义标准」(Universal Semantic Standard, USS)行业倡议——一项面向全行业的开源协作计划,旨在从根本上解决企业数据的“语义方言”问题,重塑人类与数据、数据与应用之间的交互方式。
我们携手首批创始成员畅捷通、神州商龙、小鹏汽车、卓驭科技、嘉立创科技等行业标杆企业,以及信通院、中科院等行业机构,涵盖云计算、可观测性、BI 分析、企业软件等领域的生态伙伴,共同为构建更开放、互联、智能的企业数据生态奠定基础。通过 USS 倡议,我们希望与伙伴一起,直面人工智能在企业领域的核心障碍——统一语义标准的缺失。这是一次超越竞争的行业协同,目标是共同解决企业数据互通互认的根本问题。
(一)通用语义标准倡议的核心目标与原则
USS 倡议的核心目标是:建立一套通用的、厂商中立的企业级语义模型规范,为指标、日志、链路、事件、业务实体等企业全类型数据提供统一的语义表示;实现企业业务软件、运维工具、AI 智能体之间的无缝语义互操作;加速不同行业的数字化转型与 AI 规模化落地。通过提供统一、标准的语义规范,确保所有企业数据在各平台、各部门、各系统间定义统一、价值对齐,彻底消除跨工具、跨部门、跨系统的语义歧义。倡议遵循五大核心原则:
- 标准化:建立统一的企业语义模型定义语言与数据结构,覆盖业务实体、指标定义、日志字段、链路标签、告警规则等核心要素,确保各工具与系统之间的一致性与可解释性。
- 互操作性:促进 APM、日志平台、智能运维、BI 工具、CRM、ERP 等多样化企业系统之间实现数据的无缝交换与语义模型的跨平台应用。
- 可扩展性:语义模型支持灵活扩展与定制,满足从单体应用到云原生微服务、从传统 IT 到大规模分布式系统、从通用业务到行业特定场景的需求演进。
- 开源共建:以开源社区为驱动,鼓励全球开发者、厂商、企业共同参与贡献,确保框架在技术快速迭代中保持持续的生命力与相关性。
- 领域特定建模:针对企业典型场景——如运维黄金信号、SLO/SLA 定义、业务指标体系、客户实体模型、供应链关系——提供标准化的语义表示,简化多源数据的融合与复用。
USS 充分尊重并兼容业界已有的优秀标准成果,并非要替代它们,而是在更高抽象层提供统一的语义框架。OpenTelemetry 在可观测领域定义了 traces/metrics/logs 的命名规范,但不涉及业务数据语义——USS 将在此基础上扩展至企业全场景;Open Semantic Interchange(OSI)解决了 BI/分析平台间语义模型交换的问题——USS 将与之协作互补,向上覆盖更广泛的企业应用场景;Schema.org / W3C 语义网标准提供了通用的语义标注和本体建模能力——USS 将参考其设计哲学,但专注于企业内部数据生态的实际需求。USS 面向企业全场景的语义统一层,既能向下桥接各领域专有标准,又能向上为 AI 智能体提供跨系统的统一语义上下文。
(二)预期成果
通过 USS 倡议的推进,我们将共同实现:
- 加速企业 AI 规模化落地:统一的语义标准让 AI 模型能够真正“理解”来自不同平台、不同部门的数据含义,显著提升智能运维、智能客服、智能分析、智能预测等全场景 AI 应用的准确率与落地速度。
- 将数据治理成本降低一个量级:通用语义标准为多数据源、多工具、多系统的企业数据体系提供共同语言,使数据团队从繁琐的口径对齐和字段翻译中解放出来,将更多精力投入数据价值挖掘。
- 保障厂商中立与选择自由:框架独立于任何特定的平台或 AI 工具供应商,企业在构建数字化基础设施时拥有真正的选择自由,避免厂商锁定。
- 构建企业级“语义操作系统”:从被动查阅的“数据辞典”升级为活的、主动的、可被 AI 智能体编程调用的语义运行时,为未来企业多智能体大规模协作奠定基础。
结语
站在 AI 大规模渗透企业生产系统的时代节点,数据的语义统一已经成为产业升级的核心底座。UModel 与 USS 倡议,正是我们为这个时代交出的答卷 —— 让数据不再是散落的碎片,让 AI 真正读懂企业的运行逻辑。
UModel 的核心理念清晰而坚定:将企业的业务与数据世界重构为统一的对象图,让 AI 得以沿着实体间的关联关系理解完整上下文,基于可追溯的证据做出可靠判断。随着 Agent 的能力边界不断拓展,真正制约其价值释放的,将不再是模型本身的能力上限,而是企业的业务世界是否能够被 AI 真正理解与感知。UModel 的使命,正是填补这一关键的语义鸿沟 —— 目前,我们已率先在可观测领域完成了这套路径的落地验证,证明了其可行性。
这一目标的实现,绝非单一团队可以独立完成。正因如此,我们选择将项目开源,并发起通用企业语义标准倡议 —— 我们坚信,这项事业的正确路径,本就根植于开放协作的精神,我们坚持三大开放原则:开放的标准规范、开放的技术实现、开放的效果验证。我们以可观测场景为起点完成了方法论的初步落地,而今,我们期待与社区伙伴携手,将企业对象图的能力,从这一领域逐步拓展至数据治理、业务系统与跨域协作的广阔版图。
在此,我们诚挚邀请每一位行业同行者 —— 无论您是企业软件供应商、AI 解决方案提供商、开源社区的开发者,还是各行业的企业用户 —— 与我们并肩同行,共同开启这场构建更开放、更互联、更智能的企业数据新生态的关键征程。我们相信,通过开放协作,我们将共同推动企业 AI 从 “碎片归纳” 迈向 “深度理解” 的产业变革,一同打造真正可被 AI 感知的智能企业未来。
让数据说同一种语言,让智能无界协作。