SQL作为SLS基础功能,每天承载了用户大量日志数据的分析请求,既有小数据量的快速查询(如告警、即席查询等);也有上万亿数据规模的报表级分析。SLS作为serverless服务,除了要满足不同用户的各类需求,还要兼顾性能、隔离性、稳定性等要求。过去一年多的时间,SLS SQL团队做了大量的工作,对SQL引擎进行了全新升级,SQL的执行性能、隔离性等方面都有了大幅的提升。
**SQL引擎重磅升级**
- 计算引擎切换为C++版本,充分利用CPU的SIMD指令集加速能力
- 计算存储融合,将计算和存储(只读)并入一个进程,减少数据转换和拷贝开销
- Pipeline计算模型支持细粒度并行,充分释放单机多核 CPU 的计算能力
- 调度模型升级,使任务调度更均衡和稳定,减少数据倾斜,并充分利用历史亲和力和多级缓存
- 更优的分布式执行计划,优化了多count distinct、高基数聚合等场景
- 增量计算,对于相同的SQL,复用历史局部查询结果,只计算最新的数据
- 数据缓存,引入阿里自研的缓存组件,自适应缓存列存数据,减少直接IO开销
- 高频函数性能升级,包括ip函数、json函数等,性能有数倍甚至数十倍的提升
- 支持logstore的跨project、跨region的查询和分析,更多细节参考 StoreView
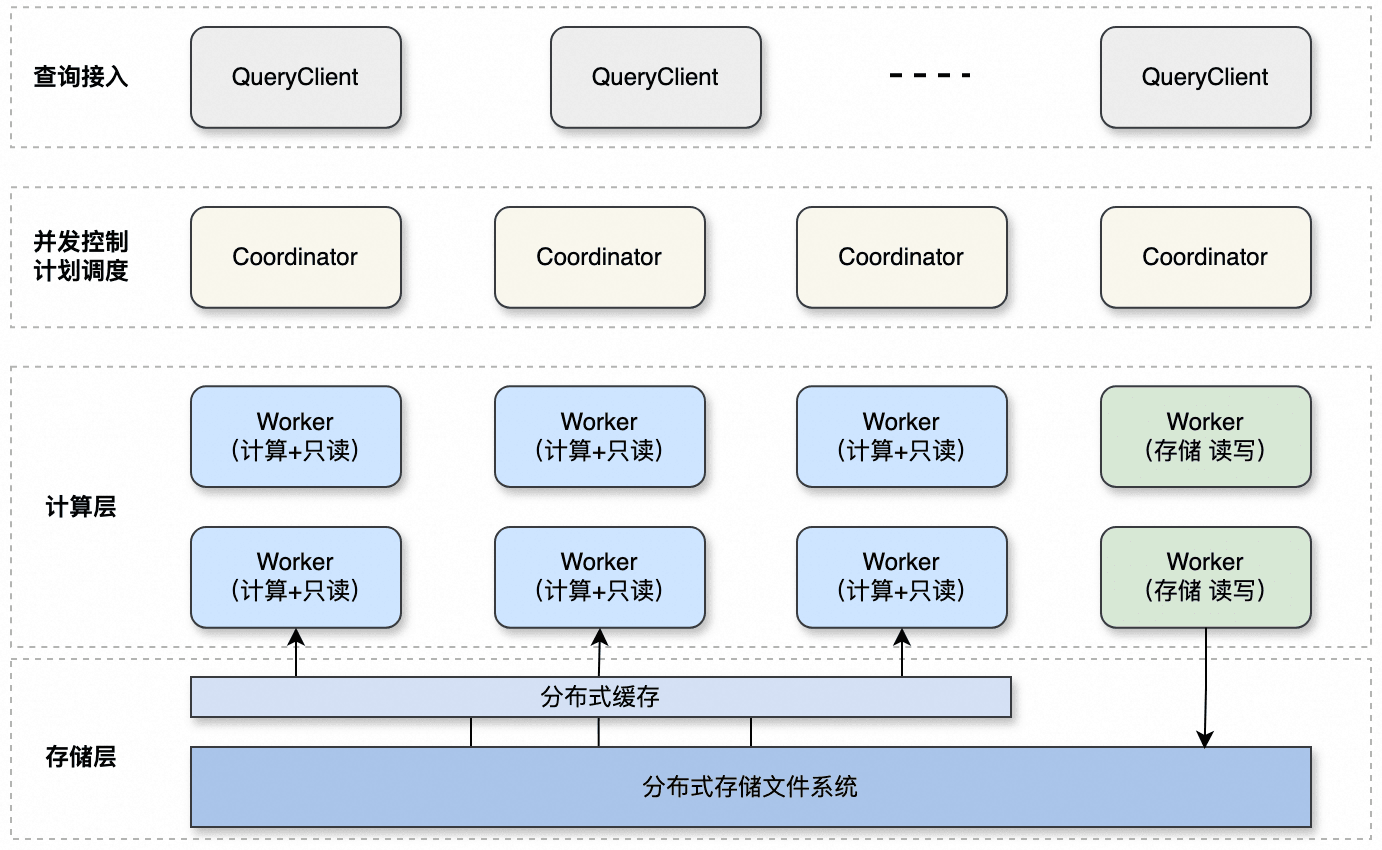
升级后的架构如下,QueryClinet作为查询代理,负责请求接入、负载均衡、结果缓存等;Coordinator负责整体SQL的并发控制和计划调度;整体采用计算存储分离的架构,同时对于只读Worker,计算和存储融合部署在同一进程,尽可能减少数据转换和拷贝开销;升级后的SQL引擎,计算性能相比于之前有3倍左右的提升。
**整体提升效果**
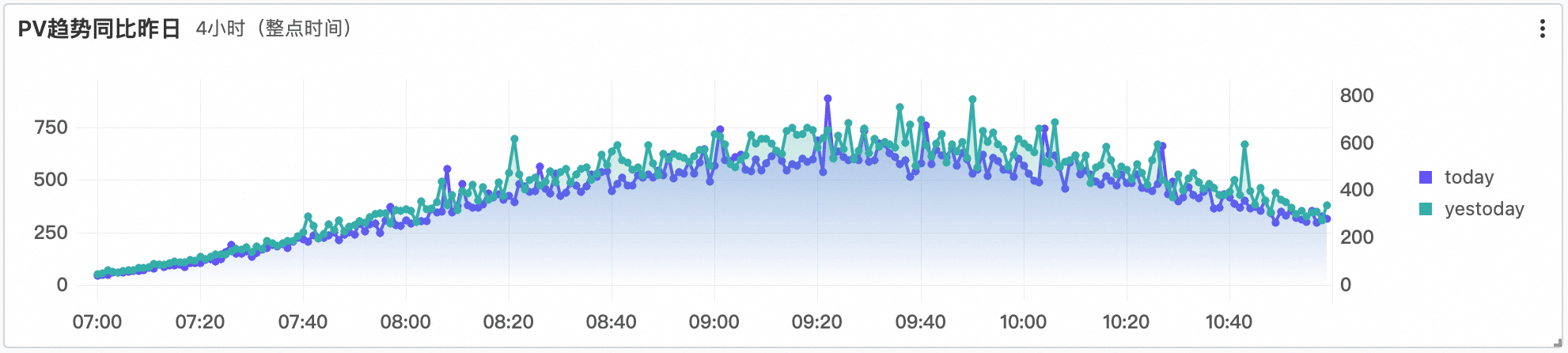
下图是线上某大集群升级后,SQL整体延时的变化情况,平均延时下降了50%,整体性能提升了一倍左右,同时查询毛刺大幅减少。

**典型场景提升效果**
下面给出一些典型分析场景的具体示例,来看看SQL引擎升级之后的表现情况。
**1、千亿规模单列聚合秒级完成,万亿规模仅需10s**
对1000亿规模数据进行单列聚合统计,执行耗时在1.46s。

对万亿规模数据,开启增强SQL模式,单列聚合只需15s。

更进一步,通过设置合适的计算并行度,万亿规模数据单列聚合可以10s内完成。

**2、中间结果复用,支持增量计算**
先查一段时间的数据,1.5秒左右完成。

相同的查询条件,查询时间范围扩大10分钟,400毫秒完成。

**3、json函数性能大幅提升**
新引擎优化了json函数的实现,和旧引擎相比,平均有数倍的提升。
以json_extract_scalar处理函数为例,对1.7亿条包含json字段的日志数据进行计算分析,
使用老引擎,耗时34.9秒,结果不精确。

使用新引擎,耗时5.8秒完成,且结果精确,json处理性能提升了6倍以上。

**4、ip函数性能10倍以上提升**
4.1 子网网段计算is_subnet_of (纯内存计算)
对10亿行包含ClientIp字段的日志数据进行子网网段计算分析,使用老引擎,耗时20s。

使用新引擎,耗时1s内完成,性能提升20倍左右。

4.2 依赖IP数据库查询
对87亿行包含ClientIp字段的日志数据进行IP计算分析,使用老引擎,耗时24s。

使用新引擎,耗时2s完成,性能提升12倍左右。

**5、千万级高基数聚合2s内完成**
计算引擎专门针对高基数聚合场景进行了特定优化,分别对数值型和字符型两种高基数聚合场景进行测试
5.1 数值型高基数聚合
测试200亿规模数据,其中有768w个distinct值
| 老引擎:17.7s | 新引擎:1.8s |
|---|
5.2 字符型高基数聚合
测试20亿规模数据,有20亿个distinct值(实际每一个RequestId都不一样,平均长度24个字符)
| 老引擎:接近40s | 新引擎:12s |
|---|
通过设置合适的并行度,延时进一步减少到6.2s

同时需注意:并行度并非越大越好,越大调度开销越高。因此可以看到,随并行度提升,性能逐渐收敛。有时,也可能出现负优化。
**6、多列聚合性能提升**
测试1000亿规模数据,同时对两列进行group by聚合分析,一列是数值型,一列是字符型
使用老引擎,耗时27.5秒,结果不精确。

使用新引擎,耗时6.5秒,性能提升4倍左右,且结果精确。

**7、多表join性能提升**
使用compare函数计算同比
使用老引擎,耗时3秒。

使用新引擎执行,耗时560毫秒,性能提升5倍左右。

备注:所有测试均在线上环境进行,使用模拟数据,数值列为随机值,字符列为长度24-30之间的随机字符,上述测试指标与测试数据、shard数量、集群节点规模均有一定关系,以实测数据为准。
**典型案例:以游戏运营分析为例**
引擎升级之后,SLS具备基于日志数据的快速运营分析能力,无需建仓、无需额外组件(如消息、流处理、数仓等)投入,一站式的日志采集、存储、加工,可见即可得的查询、监控告警、运营分析,为业务带来了前所未有的轻松体验,特别适合以数据为驱动的业务场景快速落地。
下面,我们将以游戏运营分析场景为例,给大家分享一些使用实践。
**1、基于SQL设置业务监控告警**
游戏场景中,单个区服一般有人数上限的限制,当某款游戏上线人数突然暴增,我们可以设置监控告警,以快速发现高压区服「大量注册用户涌入」,并及时进行扩容或引流等业务运营处理
event:register | select
__time__ - __time__ % 60 as time,
serverId as "区服Id",
count(*) as "注册数"
group by time,serverId
having "注册数" > 5000
order by "注册数" desc

**2、使用compare函数实现PV/UV同环比监控**
一款游戏的发行或发版,通常会持续观测用户数以及访问情况,以及时评估游戏和版本质量并进行调整。
通过SLS内置的compare函数(内部转化成join统计分析)可以轻松获取用户PV/UV同环比数据分析。
基于SQL实现PV/UV环比:
* | select diff[1] as today, round((diff[3]-1.0)*100, 2) as growth
from (
select compare(pv, 86400) as diff
from (select count(distinct remote_addr) as pv from log)
)

基于SQL实现PV/UV同比(同比字段为t,同比时需保证值相同,如08:40):
* | select t, diff[1] as today, diff[2] as yestoday, diff[3] as percentage
from (
select t, compare(pv, 86400) as diff
from (
select count(1) as pv, date_format(from_unixtime(__time__), '%H:%i') as t
from log group by t
)
group by t order by t
)
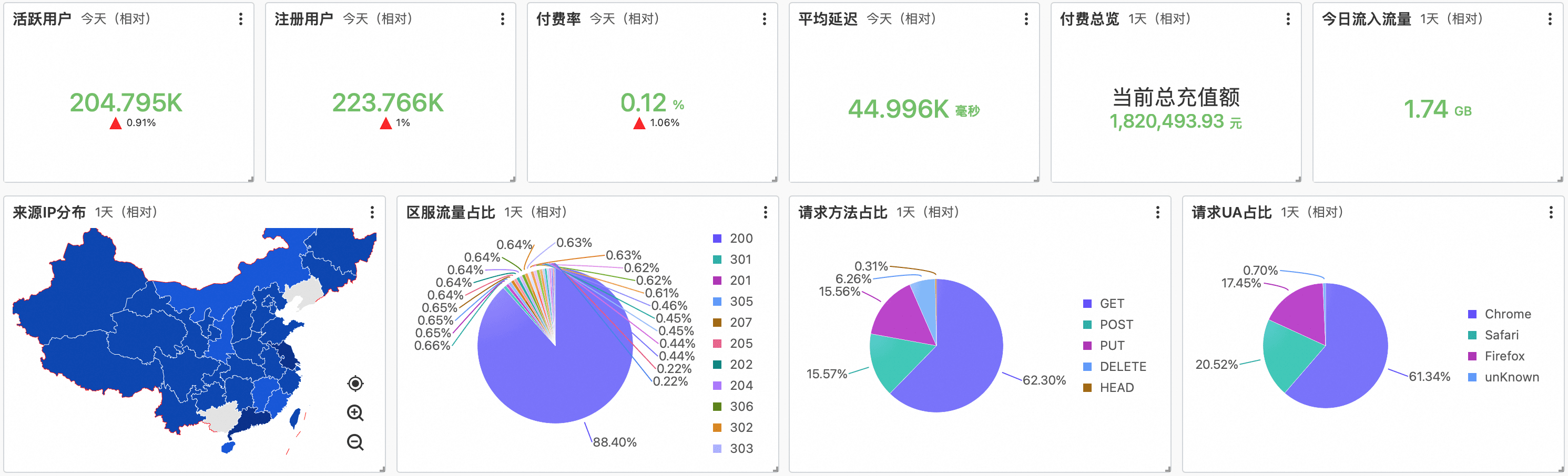
**3、基于SQL搭建看板/大盘/报表**
更进一步,我们可以基于SQL和仪表盘功能制作每日业务大盘、运营分析看板或者业务报表等。
在现有SQL能力基础上,这样的报表分析和运营数据随着游戏业务的快速落地,所见即所得。
**4、和MySQL外表(在线业务数据)做联邦查询,实现业务运营分析**
一般来说,一些业务数据和用户信息,通常是在MySQL这样的常用在线数据库中,运营分析时常常会结合游戏用户的日志数据和在线业务数据进行联合分析,SLS支持MySQL/OSS等多源外表联邦查询,只需要配置一个外表数据源,即可在SQL中进行多表Join联邦分析。

有了外表支持,比如想要分析不同性别的活跃用户分布,通过以下SQL即可实现:
-- sls_join_meta_store是一个外表(MySQL或OSS)
* |
select
case gender when 1 then '男性' else '女性' end as gender,
count(1) as pv
from log l join sls_join_meta_store u on l.userid = u.uid
group by gender
order by pv desc
**更多特性,敬请期待**
在全新SQL引擎升级基础之上,我们接下来还将陆续推出更进一步的特性支持。
1、过滤下推
计算存储融合后,我们将复杂的过滤条件(比如like、正则匹配等)下推至存储层。采用两阶段执行,首先读取有过滤条件的列,执行表达式计算,过滤出有效行,然后再去读取满足条件的其他列,可以大幅避免无效IO。
2、完全精确
建设了更完善的隔离和流控体系,进一步提升了Qos保障,通过隔离的资源池为用户提供“完全精确”模式,确保能够读取用户指定时间范围内的全量数据,实现SQL分析完全精确。