云拨测:当“正常变更”摧毁全球网络时,谁来守护你的的业务可用性?2025年11月18日,一场没有攻击、没有黑客、却让全球数百万网站陷入瘫痪的事故悄然发生——X厂商因一次看似微不足道的数据库权限变更,引发连锁反应,导致其全球边缘网络陷入间歇性瘫痪近4小时。数百万依赖其CDN、安全防护与Serverless服务的企业网站和服务出现大规模HTTP 5xx错误。用户看到的是冰冷的错误页面:“Sorry, we’re unable to complete your request. Error 5XX.”这场持续近4小时的严重中断,并非源于外部威胁,而是内部配置与自动化流程失控的结果。更令人警醒的是:
- 故障初期,团队误判为大规模DDoS攻击;
- 状态页面同时宕机,加剧了混乱和不确定性;
- 核心服务如CDN、Access、Workers KV相继失灵;
- 最终发现根源竟是一个翻倍膨胀的“特征文件”触发了内存限制。
这起事件揭示了一个残酷现实:现代IT服务中最危险的故障往往来自“正常的变更”所引发的“异常的后果”。同时,这不仅是一次技术失败,更是一面镜子,映照出当今企业数字化架构中一个致命盲区:我们太过信任服务商的自我报告,却忽视了从真实世界验证“服务是否真的可用”。
一、谁来发现“看不见”的网络故障?
在这次事件中,X厂商暴露出的问题也是企业也会经常遇到的:内部可观测性系统忙于记录未捕获异常,反而加剧CPU负载;控制台登录失败、状态页无法访问,使得运维人员难以获取真实情况;全局流量波动呈现周期性恢复与再崩溃(每5分钟一次),进一步干扰判断。那么对于使用其服务的企业来说,又该如何快速响应?假如只有传统的监控或者观测手段是否可以预防类似问题,让我们看看企业在面对此类上游故障时常见的监控体系及其局限性:
| 监控类型 | 能否发现问题? | 局限性 |
|---|---|---|
| 服务器监控(Infra) | 否 | 源站资源正常,问题出在边缘层 |
| 应用性能监控(APM) | 部分 | 只能记录已到达应用的请求,无法感知前端拦截 |
| 日志管理(Log) | 否 | 日志采集Agent可能也无法上报 |
| 服务商状态页(Status Page) | 否 | X厂商自身状态页也宕机 |
| Ping/Traceroute | 初步提示 | 仅能检测连通性,无法模拟HTTPS+业务逻辑 |
同时,本次事件中除了5xx错误,还出现了:响应延迟显著上升、登录认证失败、KV存储访问异常、防护规则误判等等典型的“软故障”(Soft Outage)——服务没完全死,但已不可用。 这意味着即使我们想查“是不是我出了问题”,我们也找不到可信信源。 结合上述表格,大家大概心里就有了答案:**必须跳出“依赖服务商自报状态”的被动模式,建立独立、客观、面向终端用户的验证机制。**当服务商都说不清发生了什么时,只有第三方主动探测能告诉我们:“你的服务,现在到底能不能用。”
而这正是**云拨测的核心价值所在——它不关心我们用了哪家CDN、哪个WAF,也不依赖任何内部日志或API,而是从真实用户视角出发,主动探测服务的真实可达性与性能表现。**云拨测通过跨ISP、跨地域、跨云厂商的分布式探测网络,构建了一套独立于任何单一基础设施之外的验证层,真正实现“上帝视角”监控。云拨测不仅能告诉我们“哪里坏了”,还能帮我们分析“为什么会坏”。
二、假如我们部署了云拨测:一场真实的“上帝视角”推演
让我们代入一个使用云拨测产品的客户视角,还原此次事件中的关键时间线:
| UTC时间 | 事件发展 | 若部署云拨测会发生什么? |
|---|---|---|
| 11:20 | X厂商网络开始丢弃流量,大量5xx错误爆发 | 云拨测节点全球告警: 分布在亚洲、欧美、非洲的多个探针同时检测到目标站点返回5xx或连接超时,立即触发多级告警(邮件/SMS/IM/ webhook)。 告警信息包含地理位置分布、响应码趋势、DNS解析状态等上下文。 |
| 11:25 | 内部误判为DDoS攻击,启动防御策略 | 云拨测排除攻击假象: 数据显示所有地区同步异常,且源IP无集中趋势,结合DNS正常、TCP握手失败等特点,初步判定非区域性攻击,而是上游网络问题。 |
| 11:30 | X厂商看板无法登录 | 独立验证通道仍在运行: 云拨测平台本身不依赖X厂商基础设施,仍可提供实时数据看板,帮助SRE团队远程决策。 |
| 12:00~14:30 | 特征文件反复生成,系统间歇性恢复 | 波动模式精准识别: 云拨测每分钟轮询机制清晰记录“通—断—通”循环,形成可视化波谷波峰图,提示“非持久性故障”,辅助定位是否为配置同步类问题。 |
| 14:30后 | 手动注入正常配置,逐步恢复 | 恢复验证自动化: 一旦拨测结果显示连续10次成功访问+响应时间回归基线,自动通知解除P1事件,避免人工遗漏。 |
从云拨测现有的真实拨测数据发现,在故障时间段有大量拨测目标为X厂商的任务开始失败。
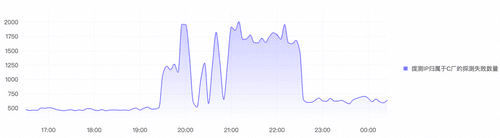
可以看到,若企业使用云拨测并开启多层探测,便可迅速得出结论:“并非源站问题,而是边缘代理层集体异常,建议切换备用CDN或检查WAF配置更新”。
三、重构可用性保障体系:从“救火式运维”到“预防型监控”
但在实际的业务生产过程中,再完善的内部流程也无法杜绝人为变更的风险。对于绝大多数企业而言,真正的答案不是等待服务商完美无缺,而是要把对业务可用性的掌控权,掌握在自己手中。除了服务可观测之外,借助外部验证来检测终端用户体验,独立验证全局可用性,形成有效的可用性保护网。很多人误以为“云拨测=定时访问网址”,但实际上,云拨测随着企业业务的不断演进,已进化为一套完善的的外部验证工具,其中包括:
| 探测类型 | 支持能力 | 应用场景 |
|---|---|---|
| HTTP(s)拨测 | 自定义Header、Cookie、Body、Expect Code | 模拟登录、API调用、支付流程 |
| DNS拨测 | 解析延迟、权威服务器响应、TTL验证 | 发现DNS劫持或缓存污染 |
| TCP/UDP拨测 | 端口可达性、握手耗时 | 数据库、游戏服务器、VoIP服务 |
| SSL/TLS拨测 | 证书有效期、加密套件、OCSP响应 | 提前预警证书过期 |
| Step-by-step Browser Check | 真实浏览器渲染,支持JavaScript执行 | SPA应用、单点登录、验证码绕行测试 |
| API事务拨测 | 多步骤API编排,变量提取与传递 | 模拟完整订单创建流程 |
借助不同类型从不同维度帮我们解决:
- DNS解析耗时突增->是否DNS异常?TTL设置不当??
- TLS握手失败->证书问题?SNI阻断?BGP劫持?
- HTTP状态码分布->是源站错误?还是边缘网关崩溃?
- 地域性差异->是否特定POP节点故障?
结语:每一次“我以为还好”,都是风险的积累
我们认为**最可怕的不是攻击,而是在不知情中失去了服务能力。**如果关注用户体验以及业务可用性,我们应立即评估以下问题:当厂商宣布故障时,我们是否有独立验证手段?我们的可观测能力是否覆盖了真实用户的访问路径?是否具备自动化切换或降级预案,并通过拨测验证其有效性?而云拨测的价值,正是在于它能在风暴来临前告诉我们:“风已经来了。”它不替代内部监控,也不挑战厂商权威,而是作为一个冷静、客观、永不疲倦的“数字哨兵”,站在互联网的各个角落,问出那个最基本的问题:“我现在还能被访问吗?”只要这个问题有答案,我们的业务就有底线保障。
永远不要相信“应该没问题”——要用证据证明“确实没问题”。 这就是云拨测存在的意义。
立即体验产品: