**UModel进阶-图查询:探索实体关系的强大工具**
**当可观测数据遇上“关系图谱”**
**从“孤立的实体”到“连接的网络”**
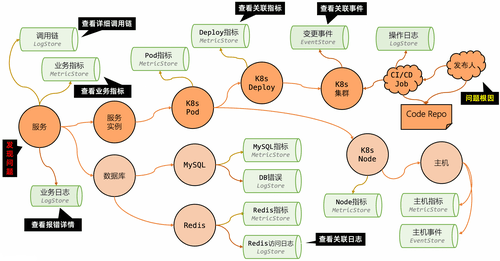
在现代云原生架构的宏大叙事中,我们习惯于将系统中的每个组件——服务、容器、中间件、基础设施,视为独立的“实体”进行监控和管理。我们为它们配置仪表盘,设置告警,追踪它们的性能指标。然而,这种“个体视角”存在一个根本性的盲点:它忽略了系统最本质的特征——连接(Connection)。任何一个实体都不是孤立存在的,它们通过调用、依赖、包含等关系,构成了一张复杂巨大、动态变化的“关系图谱”。
传统的监控和查询工具,无论是基于SQL还是SPL,其核心都是处理二维的、表格化的数据。它们擅长回答关于“个体”的问题(“这个Pod的CPU使用率是多少?”),但在回答关于“关系”的问题时却显得力不从心。当面对“这个服务的故障会影响哪些下游业务?”或“要访问到核心数据库,需要经过哪些中间服务?”这类问题时,传统工具往往需要复杂的JOIN操作、多步查询,甚至需要工程师结合线下架构图进行“人脑拼凑”。这种方式不仅效率低下,而且在关系复杂、层级深的情况下几乎无法完成。我们拥有了所有“点”的数据,却失去了一张看清“线”的地图。
**我们的思路:融合图查询**
面对这一挑战,我们的解决思路是:将“图”(Graph)作为可观测数据模型的重要组成。我们认为,系统的真实形态本就是一张图,那么对它的查询和分析,也应该使用最符合其本质的方式——图查询。
为了实现这一点,我们在UModel体系的核心构建了EntityStore。它采用了创新的双存储架构,同时维护了__entity__日志库(存储实体的详细属性)和__topo__日志库(存储实体间的拓扑关系)。这相当于我们为整个可观测系统建立了一个实时更新的、可查询的数字孪生图谱。
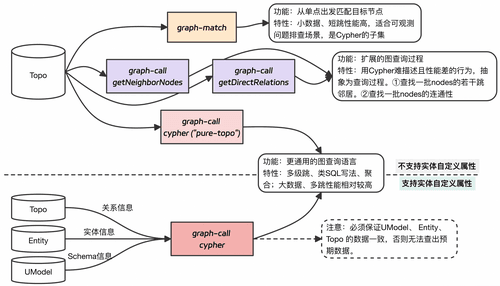
基于这个图谱,我们提供了从易到难、层层递进的三种图查询能力,以满足不同用户的需求:
- graph-match:为最常见的路径查询场景设计,语法直观,让用户能像描述一句话一样(“A经过B调用了C”)来快速查找特定链路。
- graph-call:封装了最高频的图算法(如邻居查找、直接关系查询),通过函数式接口提供,用户只需关心意图(“找A的3跳邻居”)而无需关心实现细节。
- Cypher:引入业界标准的图查询语言,提供最完整、最强大的图查询能力,支持任意复杂的模式匹配、多级跳跃、聚合分析,是处理复杂图问题的终极武器。
这一整套解决方案,旨在将强大的图分析能力,以一种低门槛、工程化的方式,提供给每一位运维和开发工程师。
**核心价值:解锁系统洞察的新维度**
引入图查询能力,不仅仅是增加了一种新的查询语法,更是为系统洞察解锁了一个全新的维度。
- 全局化的故障影响分析(爆炸半径分析):当故障发生时,可以通过一次查询,快速确定该故障点向下游辐射的所有可能路径和受影响的业务范围,为故障处理的优先级排序和决策提供实时数据支持。
- 端到端的根因溯源:与影响分析相反,当某个底层服务出现问题时,可以向上游回溯,快速定位是哪个业务或变更触发了异常,实现精准的根因定位。
- 架构健康度与合规性审计:可以通过图查询来验证线上系统的实际架构是否与设计相符。例如,查询是否存在“跨网络域的非法调用”,或者“某个核心数据服务是否被非授权的应用依赖”,从而实现架构的持续治理。
- 安全与权限链路分析:在安全审计中,可以追踪从用户到具体资源的完整访问路径,确保每一层权限授予都符合安全规范,防止潜在的数据泄露风险。
总而言之,图查询能力将我们对系统的认知从“点的集合”提升到了“结构化的网络”,使得我们能够基于系统组件之间的真实关系进行提问和分析,从而获得前所未有的深度洞察力。它是一把钥匙,开启了在复杂系统中进行高效故障排查、架构治理和安全审计的大门。
**图查询相关概念**
**相关概念**
| 概念 | 定义 | 类比 | 示例 |
|---|---|---|---|
| UModel | 完整的知识图谱系统 | 整个数据库Schema | 包含所有APM、K8s、云资源的完整建模体系 |
| EntitySet | 知识图谱中的实体类型定义 | 数据库中的表结构定义 | apm.service(APM服务类型定义) |
| Entity | 具体的实体实例 | 数据库中的具体记录 | user-service-v1.2.3(具体的服务实例) |
| EntitySetLink | 实体之间的关系定义 | 图数据库中的关系类型定义 | service\_runs\_on\_pod(服务运行在Pod上) |
| EntityRelations | 实体之间的关系实例 | 图数据库中的关系实例 | user-service -> web-pod-123(服务运行在Pod上) |
协作关系:
UModel (知识图谱)
├── EntitySet: apm.service (类型定义)
│ ├── Entity: user-service (实例1)
│ ├── Entity: payment-service (实例2)
│ └── Entity: order-service (实例3)
├── EntitySet: k8s.pod (类型定义)
│ ├── Entity: web-pod-123 (实例1)
│ └── Entity: api-pod-456 (实例2)
└── EntitySetLink: service_runs_on_pod (关系定义)
├── Relation: user-service -> web-pod-123
└── Relation: payment-service -> api-pod-456
EntityStore 借助于 SLS LogStore 资源实现数据写入、消费等功能,在创建 EntityStore 时,会同步创建以下 LogStore 资产:
- ${workspace}__entity : 用于写入实体数据
- ${workspace}__topo : 用于写入关系数据
本文介绍的图查询用法,是针对于写入${workspace}__topo的关系数据的查询。支持多跳关系路径分析、实体邻接关系分析、自定义拓扑模式识别等能力。
注意:本文介绍的图查询用法,系可观测2.0高阶PaaS API的底层查询,适合高度定制化自由查询模式的资深用户。若仅需简单的关联查找、查询信息等能力,推荐使用高阶PaaS API,接口更友好。
**总览**
**图查询基础概念**
在深入使用图查询之前,理解其基础概念至关重要。图查询的核心思想是将数据抽象为图(Graph)结构:实体是节点(Node),关系是边(Edge)。每个节点都有标签(Label)和属性(Properties),标签用于标识节点的类型,属性用于存储节点的详细信息。同样,每条边也有类型(Type)和属性,类型表示关系的类别,属性可以存储关系的额外信息。
**节点和边的描述语法**
在图查询中,使用特定的语法来描述节点和边:
- 节点:使用小括号()表示
- 边:使用中括号[]表示
- 描述格式:<变量名>:<标签> {属性键值对}
下面是一些基础语法示例:
// 任意节点
()
// 具有特定标签的节点
(:"apm@apm.service") // graph-match写法
(:apm@apm.service) // cypher写法
// 具有标签和属性的节点
(:"apm@apm.service" { __entity_type__: 'apm.service' })
// 命名变量的节点
(s:"apm@apm.service" { __entity_id__: '123456' })
// 任意边
[]
// 命名边
[edge]
// 具有类型的边
[e:calls { __type__: "calls" }]
语法差异说明:
- graph-match:在 SPL 上下文中,特殊字符需要双引号包裹
- Cypher:作为独立语法,标签使用反引号包裹
// graph-match语法
.topo | graph-match (s:"apm@apm.service" {__entity_id__: '123'})-[e]-(d)
project s, e, d
// Cypher语法(<code style="background:#f3f4f6;color:#db2777;padding:0.125rem 0.375rem;border-radius:0.25rem;font-size:0.875rem;font-family:ui-monospace,SFMono-Regular,Menlo,Monaco,Consolas,monospace">apm@apm.service</code> 反引号字符串格式,使用两个反引号包裹)
.topo | graph-call cypher( MATCH (s:apm@apm.service{\_\_entity\_id\_\_: '35af918180394ff853be6c9b458704ea'})-[e]-(d) RETURN s, e, d )
**路径语法与方向**
图查询路径使用ASCII字符描述关系方向:
| 路径表达式 | 方向说明 |
|---|---|
| (A)-[e]->(B) 或 (A)-->(B) | 从A到B的有向关系 |
| (A)<-[e]-(B) 或 (A)<--(B) | 从B到A的有向关系 |
| (A)-[e]-(B) 或 (A)--(B) | 双向关系,不限方向 |
**返回值结构**
在 EntityStore 的体系中,节点的标签格式为 domain@entity_type,例如 apm@apm.service 表示域为 apm、实体类型为 apm.service 的节点。这种标签设计不仅清晰地表示了节点的归属和类型,还支持基于域的快速过滤和查询。节点的属性包括了系统内置的属性(如 __entity_id__、__domain__、__entity_type__)以及用户在写入时自定义的属性(如 servicename、instanceid 等)。边的类型同样可以用字符串表示,比如 calls、runs_on、contains 等,每条边也会携带相应的属性信息。
**节点JSON格式**
{
"id": "apm@apm.service:347150ad7eaee43d2bd25d113f567569",
"label": "apm@apm.service",
"properties": {
"__domain__": "apm",
"__entity_type__": "apm.service",
"__entity_id__": "347150ad7eaee43d2bd25d113f567569",
"__label__": "apm@apm.service"
}
}
**边JSON格式**
{
"startNodeId": "apm@apm.service:347150ad7eaee43d2bd25d113f567569",
"endNodeId": "apm@apm.service.host:34f627359470c9d36da593708e9f2db7",
"type": "contains",
"properties": {
"__type__": "contains"
}
}
图查询的本质是模式匹配:用户描述一个图模式(Pattern),系统在图中查找所有符合该模式的子图。图模式可以用路径表达式来表示,最基础的路径表达式就是 (节点)-[边]->(节点),这表示从源节点通过一条边到达目标节点。路径表达式可以扩展为更复杂的模式,比如 (A)-[e1]->(B)-[e2]->(C) 表示从 A 经过 B 到达 C 的两跳路径,或者 (A)-[*1..3]->(B) 表示从 A 到 B 的可能的多跳路径。这种表达方式既直观又强大,能够描述从简单的一对一关系到复杂的多层级网络路径。
**graph-match:直观的路径查询**
graph-match 是图查询中最直观、最容易上手的功能。它的设计哲学是让用户能够用接近自然语言的方式描述查询意图,然后系统自动执行查询并返回结果。graph-match 的语法结构相对简单,主要由路径描述和结果投影两部分组成。
graph-match 的核心特点是必须从已知的起始点开始查询。起始点需要同时指定标签和 __entity_id__ 属性,这确保了查询能够快速定位到具体的实体。从技术实现的角度看,这种设计是有意为之:图的遍历通常是一个指数级复杂度的操作,如果允许从任意模式开始查询,可能会导致全图扫描,性能无法保证。而强制指定起始点后,系统可以基于该点进行有向遍历,将搜索空间限制在可控范围内。
路径描述的语法遵循直观的方向性表达。(A)-[e]->(B) 表示从 A 到 B 的有向边,(A)<-[e]-(B) 表示从 B 到 A 的有向边,(A)-[e]-(B) 表示双向边(不限制方向)。用户可以为路径中的每个节点和边命名变量,这些变量可以在后续的 project 语句中使用。路径可以连接多个节点和边,形成多跳路径,比如 (start)-[e1]->(mid)-[e2]->(end)。
project 语句用于指定返回的内容。用户可以直接返回节点或边的 JSON 对象,也可以使用点号语法提取特定的属性,如 "node.__entity_type__"、"edge.__type__ attribution。project 还支持重命名操作,让返回的字段具有更友好的名称。这种灵活的输出方式让 graph-match 既能满足快速探索的需求(返回完整对象),也能满足数据分析的需求(提取特定字段)。
**实际应用案例**
**全链路路径查询**
查找从特定操作开始的完整调用链路:
.topo |
graph-match (s:"apm@apm.operation" {__entity_id__: '925f76b2a7943e910187fd5961125288'})
<-[e1]-(v1)-[e2:calls]->(v2)-[e3]->(v3)
project s,
"e1.__type__",
"v1.__label__",
"e2.__type__",
"v2.__label__",
"e3.__type__",
"v3.__label__",
v3
返回结果:
- s: 起始操作节点
- e1.type: 第一段关系类型
- v1.label: 中间节点标签
- v2, v3: 后续节点信息
**邻居节点统计**
统计特定服务的邻居分布情况:
.topo |
graph-match (s:"apm@apm.service" {__entity_id__: '0e73700c768a8e662165a8d4d46cd286'})
-[e]-(d)
project eType="e.__type__", dLabel="d.__label__"
| stats cnt=count(1) by dLabel, eType
| sort cnt desc
| limit 20
**条件路径查询**
查找满足特定条件的路径终点:
.topo |
graph-match (s:"apm@apm.service.operation" {__entity_id__: '6f0bb4c892effff81538df574a5cfcd9'})
<-[e1]-(v1)-[e2:runs_on]->(v2)-[e3]->(v3)
project s,
"e1.__type__",
"v1.__label__",
"e2.__type__",
"v2.__label__",
"e3.__type__",
destId="v3.__entity_id__",
v3
| where destId='9a3ad23aa0826d643c7b2ab7c6897591'
| project s, v3
**Pod到Node的关系链**
追踪Pod的完整部署链:
.topo |
graph-match (pod:"k8s@k8s.pod" {__entity_id__: '347150ad7eaee43d2bd25d113f567569'})
<-[r1:contains]-(node:"k8s@k8s.node")
<-[r2:contains]-(cluster:"k8s@k8s.cluster")
project
pod,
node,
cluster,
"r1.__type__",
"r2.__type__"
**graph-match 限制**
尽管 graph-match 非常直观易用,但它也有一些限制:
| 限制类型 | 说明 | 解决方案 |
|---|---|---|
| 起始点限制 | 必须指定标签和entity\_id | 使用已知实体ID作为起点 |
| 中间节点限制 | 不能为中间节点指定属性 | 使用SPL进行后续过滤 |
| 不支持多级跳 | 不支持[\*2..3]语法 | 使用Cypher或分步查询 |
| 环路处理 | 边可重复使用,可能产生环 | 通过SPL去重或限制深度 |
**graph-call:函数式图操作**
graph-call 提供了一套函数式的图查询接口,这些函数封装了常见的图操作模式,让用户能够更高效地执行特定类型的查询。graph-call 的设计理念是提供声明式的函数接口,用户只需指定意图和参数,具体的遍历算法由系统优化执行。
getNeighborNodes 是最常用的 graph-call 函数,它用于获取指定节点的邻居节点。函数的签名是 getNeighborNodes(type, depth, nodeList),其中 type 参数控制遍历的类型,depth 参数控制遍历的深度,nodeList 参数指定起始节点列表。type 参数的取值包括:sequence(有向序列遍历,保持边的方向性)、sequence_in*(只返回指向起始节点的路径)、*sequence_out(只返回从起始节点出发的路径)、full(全方向遍历,不考虑边的方向)。这种类型划分让用户能够根据实际需求选择合适的遍历策略。
depth 参数控制遍历的深度,实际使用中建议不要设置过大,一般 3 到 5 层已经足够覆盖大多数场景。过深的遍历不仅会带来性能问题,返回的结果也可能因为关联关系过多而失去实际意义。nodeList 参数接受一个节点描述数组,每个节点描述遵循与 graph-match 相同的语法,需要指定标签和 __entity_id__。getNeighborNodes 会为每个起始节点分别执行遍历,然后合并结果返回。
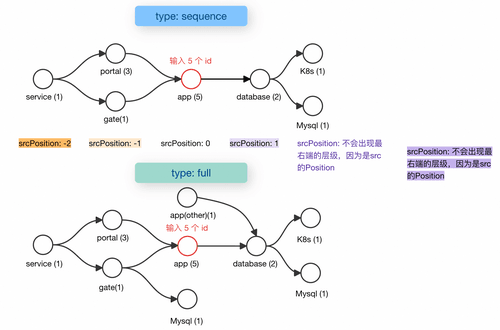
getNeighborNodes 的返回结果包含四个字段:srcNode(源节点 JSON)、destNode(目标节点 JSON)、relationType(关系类型)、srcPosition(源节点在路径中的位置,-1 表示直接邻居)。srcPosition 字段特别有用,它让用户能够区分直接关系和间接关系,在做统计分析时可以按位置分组,了解不同层级的关系分布。
getDirectRelations 函数用于批量查询节点之间的直接关系。与 getNeighborNodes 不同,getDirectRelations 只返回直接相连的关系,不进行多跳遍历。这个函数特别适合批量检查多个已知节点之间的关系,比如检查一组服务之间是否存在调用关系,或者检查一组资源之间的依赖关系。函数的参数是一个节点列表,返回结果是关系数组,每个关系包含完整的节点和边信息。
**实际应用案例**
**获取服务的完整邻居关系**
-- 获取服务的所有邻居(2跳内)
.topo | graph-call getNeighborNodes(
'full', 2,
[(:"apm@apm.service" {__entity_id__: '0e73700c768a8e662165a8d4d46cd286'})]
)
| stats cnt=count(1) by relationType
| sort cnt desc
**故障上游影响分析**
查找可能影响目标服务的上游服务:
.topo | graph-call getNeighborNodes(
'sequence_in', 3,
[(:"apm@apm.service" {__entity_id__: '0e73700c768a8e662165a8d4d46cd286'})]
)
| where relationType in ('calls', 'depends_on')
| extend impact_level = CASE
WHEN srcPosition = '-1' THEN 'direct'
WHEN srcPosition = '-2' THEN 'secondary'
ELSE 'indirect' END
| extend parsed_service_id = json_extract_scalar(srcNode, '$.id')
| project
upstream_service = parsed_service_id,
impact_level,
relation_type = relationType
| stats cnt=count(1) by impact_level, relation_type
**故障下游影响分析**
查找受目标服务故障影响的下游服务:
.topo | graph-call getNeighborNodes(
'sequence_out', 3,
[(:"apm@apm.service" {__entity_id__: 'failing-service-id'})]
)
| where relationType in ('calls', 'depends_on')
| extend affected_service = json_extract_scalar(destNode, '$.id')
| stats impact_count=count(1) by affected_service
| sort impact_count desc
| limit 20
**云资源依赖分析**
分析ECS实例的网络依赖:
.topo | graph-call getNeighborNodes(
'sequence_out', 2,
[(:"acs@acs.ecs.instance" {__entity_id__: 'i-bp1234567890'})]
)
| extend relation_category = CASE
WHEN relationType in ('belongs_to', 'runs_in') THEN 'infrastructure'
WHEN relationType in ('depends_on', 'uses') THEN 'dependency'
WHEN relationType in ('connects_to', 'accesses') THEN 'network'
ELSE 'other' END
| stats cnt=count(1) by relation_category
| sort cnt desc
| limit 0, 100
**批量查询节点间的直接关系**
.topo | graph-call getDirectRelations(
[
(:"app@app.service" {__entity_id__: '347150ad7eaee43d2bd25d113f567569'}),
(:"app@app.operation" {__entity_id__: '73ef19770998ff5d4c1bfd042bc00a0f'})
]
)
返回的关系示例:
{
"startNodeId": "app@app.service:347150ad7eaee43d2bd25d113f567569",
"endNodeId": "app@app.operation:73ef19770998ff5d4c1bfd042bc00a0f",
"type": "contains",
"properties": {"__type__": "contains"}
}
graph-call 的函数式设计带来的优势是查询意图清晰,系统能够针对特定模式进行优化。但这也意味着它只适合预定义的查询模式,对于需要自定义复杂路径模式的场景,还是需要使用 Cypher。在实际使用中,建议优先考虑 graph-call 的预定义函数,只有当预定义函数无法满足需求时,再考虑使用更灵活Cypher。
**Cypher:强大的声明式查询语言**
Cypher 是图数据库领域的标准查询语言,借鉴了 SQL 的易用性和声明式风格,同时针对图结构进行了专门优化。在 EntityStore 中,Cypher 提供了最强大和灵活的图查询能力,能够处理从简单的单节点查询到复杂的多级跳路径网络的各种场景。
Cypher 的语法遵循三段式结构:MATCH、WHERE、RETURN,这与 SQL 的 SELECT、WHERE、FROM 结构类似,但逻辑更符合图查询的思维模式。MATCH 子句用于描述图模式,WHERE 子句用于添加筛选条件,RETURN 子句用于指定返回的内容。这种结构化的语法让复杂的图查询也变得易于阅读和维护。
MATCH 子句的强大之处在于它支持的图模式描述。用户可以在 MATCH 中指定任意复杂的路径模式,包括多级跳、可选路径、路径变量等。多级跳的语法是 [*min..max],其中范围是左闭右开的,比如 [*2..3] 表示只查询 2 跳路径。这种语法设计让用户能够灵活地控制遍历深度,在精度和性能之间取得平衡。MATCH 还支持多个路径模式的组合,用户可以同时描述多个路径模式,系统会找到所有满足任一模式的子图。
WHERE 子句支持丰富的筛选条件。用户可以对节点的属性、边的属性进行各种条件判断,包括相等、包含、以某字符串开头或结尾、范围判断等。WHERE 子句还支持逻辑组合(AND、OR、NOT)和复杂的表达式。相比 graph-match,Cypher 的 WHERE 子句更加灵活,不仅可以在查询时进行筛选,还可以对中间节点进行条件限制,这对于复杂路径模式的查询特别有用。
RETURN 子句提供了灵活的输出控制。用户可以返回节点对象、边对象、路径对象,也可以提取特定的属性字段。RETURN 还支持聚合函数(如 count、sum、avg 等)和分组操作,这让 Cypher 不仅能够进行图遍历,还能够进行图分析。结合 SPL 的强大处理能力,Cypher + SPL 的组合能够完成从数据查询到分析计算的全流程。
**基础查询示例**
**单节点查询**
-- 查询特定类型的所有节点
.topo | graph-call cypher( MATCH (n {\_\_entity\_type\_\_:"apm.service"}) WHERE n.\_\_domain\_\_ STARTS WITH 'a' AND n.\_\_entity\_type\_\_ = "apm.service" RETURN n )
相比graph-match的优势:
- 支持WHERE子句进行复杂筛选
- MATCH可以只包含节点,无需指定关系
- 支持更多的属性查询(__entity_type__、__domain__等)
**关系查询**
-- 查询服务间调用关系
.topo | graph-call cypher( MATCH (src:apm@apm.service)-[e:calls]->(dest:apm@apm.service) WHERE src.cluster = 'production' AND dest.cluster = 'production' RETURN src.service, dest.service, e.\_\_type\_\_ )
**多级跳查询**
**基础多级跳语法**
-- 查找2-3跳的调用链路
.topo | graph-call cypher( MATCH (src {\_\_entity\_type\_\_:"acs.service"})-[e:calls\*2..4]->(dest) WHERE dest.\_\_domain\_\_ = 'acs' RETURN src, dest, dest.\_\_entity\_type\_\_ )
重要说明:
- 多级跳规则是左闭右开:*2..4表示查询2跳和3跳
- *1..3表示1跳或2跳,不包括3跳
**连通性分析**
-- 查找服务间的可达路径
.topo | graph-call cypher( MATCH (startNode:apm@apm.service {service: 'gateway'}) -[path:calls\*1..4]-> (endNode:apm@apm.service{service: 'database'}) RETURN startNode.service, length(path) as hop\_count, endNode.service )
**影响链分析**
-- 分析故障传播路径
.topo | graph-call cypher( MATCH (failed:apm@apm.test_service{status: 'error'}) -[impact:depends\_on\*1..3]-> (affected) WHERE affected.\_\_entity\_type\_\_ = 'apm.service' RETURN failed.service, length(impact) as impact\_distance, affected.service ORDER BY impact\_distance ASC )
**节点聚合统计**
-- 统计不同域的服务数量
.topo | graph-call cypher( MATCH (src {\_\_entity\_type\_\_:"apm.service"})-[e:calls\*2..3]->(dest) WHERE dest.\_\_domain\_\_ = 'apm' RETURN src, count(src) as connection\_count )
适用场景:
- 连通分量分析:识别图中的连通子图
- 中心度计算:找出网络中的关键节点
- 集群检测:发现紧密连接的节点群组
**路径模式查找**
-- 查找特定的拓扑模式
.topo | graph-call cypher( MATCH (src:acs@acs.vpc.vswitch)-[e1]->(n1)<-[e2]-(n2)-[e3]->(n3) WHERE NOT (src = n2 AND e1.\_\_type\_\_ = e2.\_\_type\_\_) AND n1.\_\_entity\_type\_\_ <> n3.\_\_entity\_type\_\_ AND NOT (src)<-[e1:calls]-(n1) RETURN src, e1.\_\_type\_\_, n1, e2.\_\_type\_\_, n2, e3.\_\_type\_\_, n3 )
适用场景:
- 安全审计:发现异常的网络连接模式
- 合规检查:验证网络架构的合规性
- 模式检测:识别特定的系统拓扑结构
Cypher 的一个重要特性是支持基于实体自定义属性的查询。在 graph-match 中,中间节点只能通过标签进行过滤,但在 Cypher 中,用户可以基于实体的任意自定义属性进行查询和筛选。这个特性让 Cypher 能够处理更加细粒度的查询需求,比如查找所有 CPU 使用率大于 80% 的实例,或者查找所有属于某个特定用户的资源。
**自定义属性查询示例**
基于实体自定义属性的查询是完整版 Cypher 的核心亮点。在标准查询中,虽然可以通过 Usearch 获取实体的详细信息,但在图遍历过程中使用实体属性进行筛选还是有限制的。完整版 Cypher 实现了真正的属性级查询,用户可以在 MATCH 或 WHERE 子句中直接使用实体的自定义属性,系统会自动从 EntityStore 中获取实体的详细信息,并基于这些信息进行过滤。这种设计让图查询不再只是基于拓扑结构的遍历,还能够基于实体的实际属性进行智能筛选,大大提升了查询的精确度。
多级路径输出是另一个重要特性。在传统的图查询中,多级跳查询通常只返回起点和终点,中间的路径信息可能会丢失。但在故障排查和影响分析场景中,了解完整的路径往往比只知道起点和终点更有价值。完整版 Cypher 支持返回路径对象,路径对象包含了路径中所有节点和边的信息,用户可以通过路径对象了解数据流转的完整链路。这个特性特别适用于分析故障传播路径、追踪数据流、理解系统架构等场景。
**基于实体自定义属性查询**
-- 使用实体的自定义属性进行查询 (仅为示例,实际属性kv以真实场景为准)
.topo | graph-call cypher( MATCH (n:acs@acs.alb.listener{listener\_id: 'lsn-rxp57\*\*\*\*\*'})-[e]->(d) WHERE d.vSwitchId CONTAINS 'vsw-bp1gvyids\*\*\*\*\*\*' AND d.user\_id IN ['1654\*\*\*\*\*\*\*', '2'] AND d.dns\_name ENDS WITH '.com' RETURN n, e, d )
**复杂的属性条件查询**
-- 复杂的属性条件查询 (仅为示例,实际属性kv以真实场景为准)
.topo | graph-call cypher( MATCH (instance:acs@acs.ecs.instance) WHERE instance.instance\_type STARTS WITH 'ecs.c6' AND instance.cpu\_cores >= 4 AND instance.memory\_gb >= 8 AND instance.status = 'Running' RETURN instance.instance\_id, instance.instance\_type, instance.cpu\_cores, instance.memory\_gb, instance.availability\_zone ORDER BY instance.cpu\_cores DESC, instance.memory\_gb DESC )
**多级路径输出**
**返回完整路径信息**
-- 返回多级跳的完整路径信息
.topo | graph-call cypher( MATCH (n:acs@acs.alb.listener)-[e:calls\*2..3]-() RETURN e )
路径结果格式:
- 返回路径中所有边的数组
- 每个边包含完整的起止节点和属性信息
- 支持路径长度和路径权重计算
**细粒度链路控制的连通性查找**
**跨网络层级的连接分析**
-- 查找ECS实例到负载均衡器的连接路径
.topo | graph-call cypher( MATCH (start\_node:acs@acs.ecs.instance) -[e\*2..3]- (mid\_node {listener\_name: 'entity-test-listener-zuozhi'}) -[e2\*1..2]- (end\_node:acs@acs.alb.loadbalancer) WHERE start\_node.\_\_entity\_id\_\_ <> mid\_node.\_\_entity\_id\_\_ AND start\_node.\_\_entity\_type\_\_ <> mid\_node.\_\_entity\_type\_\_ RETURN start\_node.instance\_name, e, mid\_node.\_\_entity\_type\_\_, e2, end\_node.instance\_name )
**服务网格连接分析**
-- 分析微服务网格中的流量路径
.topo | graph-call cypher( MATCH (client:apm@apm.service) -[request:calls]-> (gateway:apm@apm.gateway) -[route:routes\_to]-> (service:apm@apm.service) -[backend:calls]-> (database:middleware@database) WHERE client.environment = 'production' AND request.protocol = 'HTTP' AND route.load\_balancer\_type = 'round\_robin' RETURN client.service, gateway.gateway\_name, service.service, database.database\_name, request.request\_count, backend.connection\_pool\_size )
**级联故障分析**
-- 分析服务故障的级联影响
.topo | graph-call cypher( MATCH (failed\_service:apm@apm.service {service: 'load-generator'}) MATCH (failed\_service)-[cascade\_path\*1..4]->(affected\_service:apm@apm.service) RETURN failed\_service.service as root\_cause, length(cascade\_path) as impact\_depth, affected\_service.service as affected\_service, cascade\_path as dependency\_chain ORDER BY impact\_depth ASC )
**典型应用场景**
图查询在实际运维和分析场景中的应用非常广泛,以下列举几个典型的应用模式,帮助用户更好地理解如何将图查询能力应用到实际工作中。
**分析服务调用链**
-- 分析特定服务的调用模式
.topo |
graph-match (s:"apm@apm.service" {__entity_id__: 'abcdefg123123'})
-[e:calls]-(d:"apm@apm.service")
project
source_service="s.service",
target_service="d.service",
call_type="e.__type__"
| stats call_count=count(1) by source_service, target_service
| sort call_count desc
**权限链追踪**
在复杂的系统中,理解用户的权限是如何传递到资源的,对于安全审计和合规检查至关重要:
-- 追踪用户到资源的访问路径
.topo |
graph-match (user:"identity@user" {__entity_id__: 'user-123'})
-[auth:authenticated_to]->(app:"apm@apm.service")
-[access:accesses]->(resource:"acs@acs.rds.instance")
project
user_id="user.user_id",
app_name="app.service",
resource_id="resource.instance_id",
auth_method="auth.auth_method",
access_level="access.permission_level"
**数据完整性检查**
**检查数据完整性**
.topo | graph-call cypher( MATCH (n)-[e]->(m) RETURN count(DISTINCT n) as unique\_nodes, count(DISTINCT e) as unique\_edges, count(DISTINCT e.\_\_type\_\_) as edge\_types )
**识别悬挂关系**
-- 查找指向不存在实体的关系
.let topoData = .topo | graph-call cypher( MATCH ()-[e]->() RETURN e )
| extend startNodeId = json_extract_scalar(e, '$.startNodeId'), endNodeId = json_extract_scalar(e, '$.endNodeId'), relationType = json_extract_scalar(e, '$.type')
| project startNodeId, endNodeId, relationType;
--$topoData
.let entityData = .entity with(domain='*', type='*')
| project __entity_id__, __entity_type__, __domain__
| extend matchedId = concat(__domain__, '@', __entity_type__, ':', __entity_id__)
| join -kind='left' $topoData on matchedId = $topoData.endNodeId
| project matchedId, startNodeId, endNodeId, relationType
| extend status = COALESCE(startNodeId, '悬挂')
| where status = '悬挂';
$entityData
**数据完整性与查询模式选择**
在使用图查询时,数据完整性是一个需要特别关注的问题。EntityStore 的图查询能力依赖于三方面的数据:UModel(数据模型定义)、Entity(实体数据)、Topo(拓扑关系数据)。这三方面的数据完整性直接影响了查询的能力和结果。
**数据缺失场景分析**
| UModel | Entity | Topo | 查询表现 |
|---|---|---|---|
| ✅ | ✅ | ✅ | 正常情况,所有查询都可用 |
| ✅ | ✅ | ❌ | 无法进行图查询,VertexSet接口依赖topo数据 |
| ✅ | ❌ | ✅ | 关系正常,但节点信息为空 |
| ✅ | ❌ | ❌ | 完全无法查询,虽有Schema但无数据 |
| ❌ | ✅ | ✅ | 无法查询,pure-topo可正常工作 |
| ❌ | ✅ | ❌ | 完全无法查询 |
| ❌ | ❌ | ✅ | 无法查询,pure-topo可正常工作 |
| ❌ | ❌ | ❌ | 完全无法查询 |
**pure-topo 模式**
需要注意的是,完整版 Cypher 依赖于 UModel、Entity 和 Topo 三方面的数据都要完备。如果 Entity 数据不完整,虽然仍然可以进行拓扑查询,但无法使用自定义属性进行筛选。为了解决这个问题,系统提供了 pure-topo 模式:
-- 标准模式(需要完整数据)
.topo | graph-call cypher( MATCH (n:acs@acs.alb.listener{ListenerId: 'lsn-123'})-[e]->(d) WHERE d.vSwitchId CONTAINS 'vsw-456' RETURN n, e, d )
-- pure-topo模式(仅依赖关系数据)
.topo | graph-call cypher( MATCH (n:acs@acs.alb.listener)-[e]->(d) RETURN n, e, d , 'pure-topo')
pure-topo模式特点:
- 优势:不依赖Entity数据,查询速度更快
- 限制:无法使用实体的自定义属性进行筛选
- 适用:拓扑结构分析、关系验证等场景
**查询模式选择策略**
当三方面数据都完整时,用户可以使用完整版 Cypher 的所有功能,包括基于自定义属性的查询、多级路径输出等。当 Entity 数据不完整但 Topo 数据完整时,可以使用 pure-topo 模式进行查询,这种模式下查询速度会更快,但只能基于拓扑结构进行查询,无法使用实体属性进行筛选。当 Topo 数据不完整时,虽然 Entity 数据完整,也无法进行图查询,因为图查询的核心是关系,没有关系数据就无法构成图。
在实际使用中,用户应该根据数据的完整性情况选择合适的查询方式。如果数据完整性足够,优先使用完整版 Cypher,享受属性级查询的便利。如果性能是首要考虑,且只需要拓扑结构信息,可以使用 pure-topo 模式。如果需要进行数据完整性检查,可以先使用简单的查询测试数据的完整性,然后再执行复杂的查询。
**性能优化与最佳实践**
图查询虽然强大,但在大数据量的情况下,性能也可能成为瓶颈。合理的使用方法和优化策略能够显著提升查询性能,确保系统在高负载下也能稳定响应。
**查询结构优化**
**合理使用索引**
-- ❌ 优化前:全表扫描
.topo | graph-call cypher( MATCH (n) WHERE n.service = 'web-app' RETURN n )
-- ✅ 优化后:使用标签索引
.topo | graph-call cypher( MATCH (n:apm@apm.service{service: 'web-app'}) RETURN n )
**早期条件过滤**
-- ❌ 优化前:后期过滤
.topo | graph-call cypher( MATCH (start)-[\*1..5]->(endNode) WHERE start.environment = 'production' AND endNode.status = 'active' RETURN start, endNode )
-- ✅ 优化后:早期过滤
.topo | graph-call cypher( MATCH (start {environment: 'production'})-[\*1..5]->(endNode {status: 'active'}) RETURN start, endNode )
**查询范围控制**
查询范围的精确控制是最重要的优化策略:
- 时间范围优化:合理利用时间字段进行范围限制
- 限制遍历深度:深度超过5层会显著影响性能
- 精确起始点:使用具体的entity_id而非模糊匹配
- 合理选择遍历类型:根据实际需求选择sequence或full
**结果集控制**
**分页和限制**
-- 使用LIMIT控制结果数量
.topo | graph-call cypher( MATCH (service:apm@apm.service)-[calls:calls]->(target) WHERE calls.request\_count > 1000 RETURN service.service, target.service, calls.request\_count ORDER BY calls.request\_count DESC LIMIT 50 )
**结果采样**
-- 对大结果集进行采样
.topo | graph-call cypher( MATCH (n:apm@apm.service) RETURN n.service LIMIT 100 )
| extend seed = random()
| where seed < 0.1
**多级跳优化**
**控制跳跃深度**
-- 避免过深的遍历
.topo | graph-call cypher( MATCH (start)-[path\*1..3]->(endNode) WHERE length(path) <= 2 RETURN path )
**使用方向性优化**
-- 利用关系方向减少搜索空间
.topo | graph-call cypher( MATCH (start)-[calls:calls\*1..3]->(endNode) -- 明确方向 WHERE start.\_\_entity\_type\_\_ = 'apm.service' RETURN start, endNode )
**最佳实践建议**
- 使用 SPL 过滤:在图查询后及时过滤不需要的结果
- 分批处理:对于大型图查询,考虑分批处理
- 结果缓存:对于频繁查询的路径,考虑结果缓存
- 查询拆分:将复杂查询拆分为多个简单查询,然后使用 SPL 合并
**常见问题**
**边类型恰好与Cypher关键字重合**
.topo | graph-call cypher( MATCH (s)-[e:contains]->(d) WHERE s.\_\_domain\_\_ CONTAINS "apm" RETURN e )
contains 是 cypher 关键字,同时也是边类型,此时作为 Cypher 语法需要在边类型上面加入 back-tick 标识进行包裹,又因为在 SPL 上下文中,所以作为 SPL 语法需要变为双 back-tick 标识进行包裹。
**多级跳语法说明**
-- 查找2-3跳的调用链路
.topo | graph-call cypher( MATCH (src {\_\_entity\_type\_\_:"acs.service"})-[e:calls\*2..4]->(dest) WHERE dest.\_\_domain\_\_ = 'acs' RETURN src, dest, dest.\_\_entity\_type\_\_ )
重要说明:
- 多级跳规则是左闭右开:*2..4表示查询2跳和3跳
- *1..3表示1跳或2跳,不包括3跳
验证该结论:
.topo | graph-call cypher( MATCH (s)-[e\*1..3]->(d) RETURN length(e) as len , 'pure-topo')
| stats cnt=count(1) by len
| project len, cnt
**不支持简写Cypher关系**
✅ 支持的写法:
.topo | graph-call cypher( MATCH (s)-[]->(d) RETURN s , 'pure-topo')
❌ 不支持的写法:
.topo | graph-call cypher( MATCH (s)-->(d) RETURN s , 'pure-topo')