**SLS 全面兼容 PostgreSQL:标准协议 + 原生语法,零门槛玩转日志数据**
**背景:AI 应用爆发下的“数据隐忧”**
在 AI Agent 爆发的今天,开发者的首选栈是什么?是 LangChain 这样的代码框架,更是 Dify 这样发展迅猛的低代码开发平台。然而,随着你的 AI 应用从 Demo 走向生产,海量的运行时记录开始爆炸式增长。
你的 PostgreSQL 数据库还能撑得住吗?传统的做法是将业务数据和海量日志都塞进同一个 PG 实例。结果就是:磁盘空间告急、数据库性能抖动、备份恢复极慢。
SLS 推出新功能:全面兼容 PostgreSQL 协议、语法与系统表。这不仅仅是接口的开放,更是为 Dify、LangChain 等 AI 平台量身定制的“瘦身方案”。
SLS无缝融入 PostgreSQL 开源生态
面对海量 AI 日志带来的数据库“高血压”问题,SLS 给出的解法不是单纯的扩容,而是架构层面的结构性优化。下面这张图直观展示了使用SLS兼容PG协议的几大优势。
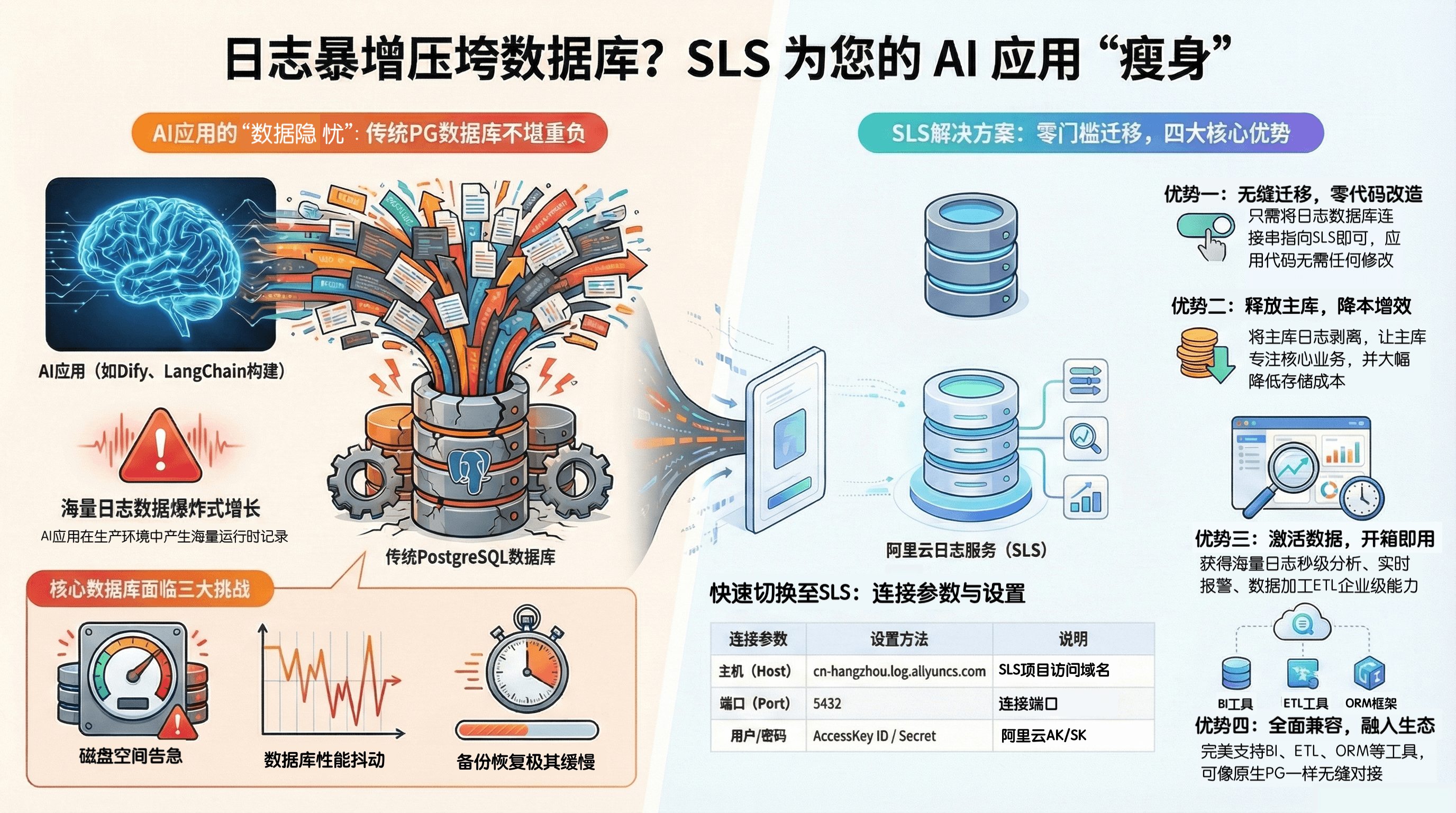
1. 双向奔赴:读写一体,全协议兼容
告别“写入用 SDK,查询用 SQL”的分裂体验。现在,SLS 支持通过标准的 PostgreSQL 协议进行双向交互。
- 标准写入 (Standard INSERT): 支持标准的 INSERT 语句。这意味着可以直接使用 Airbyte、Kettle等标准 ETL 工具,或者直接在代码中通过 INSERT 将数据写入 SLS,无需引入任何 SLS 专有 SDK。
- 实时查询 (Standard SELECT): 写入的数据秒级可见,随即可以通过标准 SELECT 语句进行检索。
- 真正的数据闭环: 从数据流入到数据流出,一条 PG 协议走到底。
2. Dify 最佳拍档:一键卸载日志,降本增效
这是本次升级率先落地并经过完整验证的实战场景。Dify 等AI开发平台支持通过配置将工作流运行记录写到PostgreSQL数据库。
- 无缝对接: 只需在 Dify 配置中,将工作流执行记录连接串指向 SLS,无需修改源码。
- 释放 PG 压力: 将高频写入、体量巨大的“运行时记录”从主 PG 实例剥离,通过 PG 协议直接写入 SLS。让昂贵的主库专注于核心业务元数据,IOPS 压力骤降。
- 极致成本: SLS 的冷热分层存储成本远低于高性能 RDS/PG 实例。用日志的价格存日志,不再用数据库的价格存日志。
- 激活数据价值: 接入 SLS 只是第一步。依托 SLS 强大的原生能力,可以直接享受海量日志秒级分析(如 Token 消耗趋势)、实时告警(如 API 错误率突增通知)以及数据加工 ETL(如清洗对话数据用于后续模型微调)。无需额外开发,瞬间拥有了企业级的运维监控与数据处理能力。
详细的技术细节和使用方法参考文章:《》
3. 元数据兼容:100% 支持 PG 系统表
这是实现企业级工具链无缝接入的基石。SLS 不仅支持标准 SQL 数据查询,更在内核层面完整实现了 PostgreSQL 的系统表接口。
- 系统表全覆盖: 完美支持访问 pg_class, pg_attribute, pg_namespace, pg_type, information_schema 等核心系统表。
- 无缝对接生态工具: 无论是复杂的 BI 软件(Tableau/PowerBI),还是严格的 ORM 框架(Hibernate/TypeORM),在启动时都会扫描数据库元数据。SLS 能完美响应这些请求,使各类工具将其视作标准 PostgreSQL 引擎并无缝运行,无需任何插件或修改。
4. 极简鉴权:完全复用 SLS 权限体系
安全与便捷兼得,无需维护两套账号,SLS 的 PG 兼容层天然打通了阿里云 RAM 权限体系。
- 零迁移成本: 直接使用已有的阿里云 AccessKey ID 作为数据库用户名,AccessKey Secret 作为数据库密码。
- 权限继承: 继承 RAM 策略。如果在 RAM 中限制了某个 AK 只能读取特定的 Logstore,那么当该用户通过 PG 协议连接时,依然受此策略限制。
如何使用
无需申请新实例,无需任何额外部署,现有的 SLS 实例已原生具备此能力。
- Host (连接地址): 保持不变(例如cn-hangzhou.log.aliyuncs.com)
- Port (端口): 将默认 HTTP 端口切换为 5432
- User/Password: 使用 AccessKey ID 和 Secret
就这么简单,日志服务瞬间变成了一个标准的 PostgreSQL 数据库。