**背景**
在前一篇文章《一次内存诊断,让资源利用率提升40%:揭秘隐式内存治理》[1]中,我们系统性地剖析了云原生环境中隐性内存开销的诊断方法,通过SysOM系统诊断实现了对节点/Pod级由文件缓存、共享内存等系统级内存资源异常消耗的精准定位。
然而,部分场景下内存异常仍可能源于应用进程本身的内存申请,但是对于应用内存泄漏问题,尽管是应用的开发者,也需要投入大量的精力去利用对应语言的内存分析工具去找出根因;以Java应用为例,当传统线下IDC集群中的Java应用完成云原生架构转型后,伴随容器化封装与资源配额管控的实施,用户普遍反馈Java应用Pod出现持续性内存超限及Kubernetes OOMKilled事件。这一系列现象主要集中在三个关键矛盾点:
- 容器内存监控与JVM堆内存的显著差异
Pod内存占用常超出JVM堆内存(含堆外内存)数倍,形成"消失的内存"谜团 - 容器化改造后的OS兼容性问题
同一业务系统在切换OS或容器化后,出现内存占用模式突变 - 工具链覆盖盲区
传统Java内存分析工具无法覆盖JNI内存、LIBC内存等非JVM内存区域
为此,云监控2.0[2]中的SysOM系统诊断对应用内存进一步深挖,结合应用和操作系统的角度实现对主机、容器运行时及具体的Java应用进程进行内存占用拆解,快速有效地识别出Java内存占用的元凶
Java内存全景分析
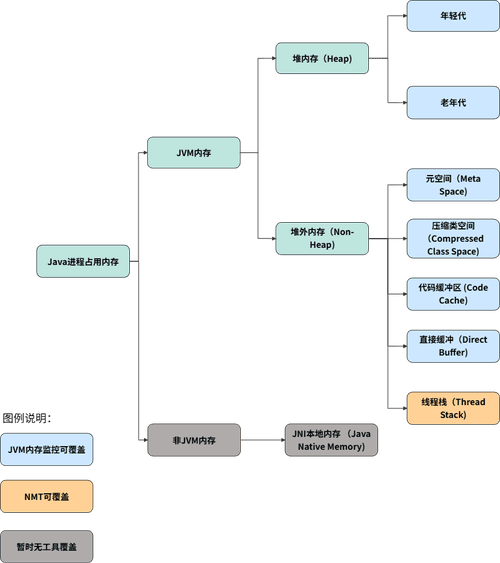
为了找出消失的内存,我们首先要了解Java进程的主要内存组成以及现有工具和监控主要覆盖的部分;如下图所示可分为:
JVM内存
- 堆内存:可通过-Xms/-Xmx参数控制,内存大小可通过memorymxbean等获取。
- 堆外内存:包括元空间、压缩类空间、代码缓冲区、直接缓冲、线程栈等内存组成;它们分别可以通过-XX:MaxMetaspaceSize(元空间)、-XX:CompressedClassSpaceSize (压缩类空间)、 -XX:ReservedCodeCacheSize( 代码缓冲区)、-XX:MaxDirectMemorySize (直接缓冲)、-Xss(线程栈)参数限制。
非JVM内存:
- **JNI本地内存:**即通过本地方法接口调用C、C++代码(原生库),并在这部分代码中调用C库(malloc)或系统调用(brk、mmap)直接分配的内存。
**Java常见“内存泄漏”**
JNI内存泄漏
经过上一章中对Java内内存全景的分析,其实已经可以揭开第一个容易造成内存黑洞的隐藏Boss-JNI内存,因为这部分内存暂时没有工具可以获取其占用大小。
通常来说,编写相关业务代码的同学会认为代码中没有使用本地方法直接调用C库,所以不会存在这些问题,但是代码中引用的各种包却有可能会使用到JNI内存,比如说经典的使用ZLIB 压缩库不当导致的JNI泄漏问题[3]
LIBC内存管理特性
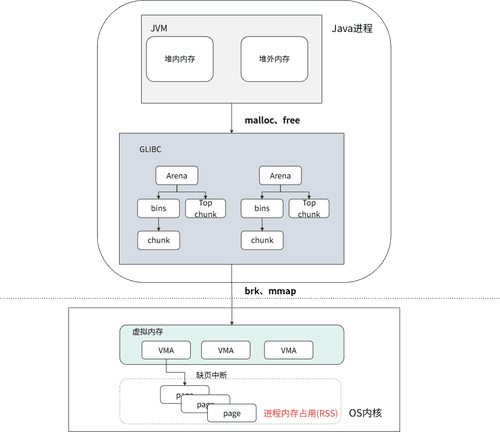
JVM向OS申请内存的中间,还存在着一层中间层-C库,JVM调用malloc、free申请/释放内存的过程中其实还要经过这一个二道贩子;以gibc中默认的内存分配器ptmalloc为例glibc的ptmalloc内存分配器存在以下特征:
- Arena机制:每个线程维护64M Arena,多线程场景下易产生内存碎片
- Top Chunk管理:内存空洞导致无法及时归还OS
- Bins缓存策略:JVM释放的内存暂存于bins中,造成统计偏差[4-5]
Linux透明大页(THP)影响
在OS层,Linux中的透明大页(Transparent Huge Page)机制也是造成JVM内存和实际内存差异的一大元凶。简单来说,THP机制就是OS会将4kb页变成2M的大页,从而减少TLB miss和缺页中断,提升应用性能,但是也带来了一些内存浪费。如应用申请了一段2M的虚拟内存,但实际只用了里面的4kb,但是由于THP机制,OS已经分配了一个2M的页了[6];
SysOM Java内存诊断实践:
下面将以汽车行业客户在从线下idc集群迁移至云上ACK集群时遇到的由于JNI内存泄漏导致Pod频繁OOM为例,介绍如何通过云监控2.0的SysOM系统诊断来一步步找出Java内存占用的元凶
诊断使用限制:
- 目前仅支持openJDK 1.8以上版本
- 使用JNI内存Profiling功能需要至操作系统控制台先对实例进行纳管[3],有一定的资源和性能开销(内存占用根据符号大小最高达300MB)
**C2 compiler JIT 内存膨胀案例**
案例背景
某汽车客户在ACK集群迁移过程中,多个Java服务Pod出现偶发性OOM。特征表现为:
- Pod内存接近限制时触发OOM
- JVM监控显示内存正常
- 无明显请求异常或流量波动
**排查过程:**
- 尝试在内存高水位时对Pod发起内存全景分析。
- 我们可以了解到当Pod中容器内存使用已经接近limit,从诊断结论和容器内存占用分析中,我们可以看到容器内存主要是由于Java进程内存占用导致
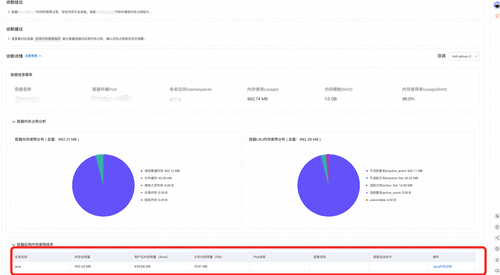
对Java进程发起内存分析,查看诊断报告。报告展示了Java进程所在Pod和容器的rss和WorkingSet(工作集)内存信息、进程Pid、JVM内存使用量(即JVM视角的内存使用量)、Java进程内存使用量(进程实际占用内存),进程匿名用量以及进程文件内存用量。
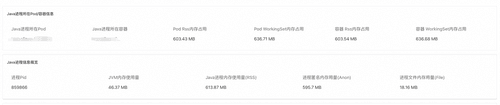
通过诊断结论和Java内存占用饼图我们可以发现,进程实际内存占用比JVM监控显示的内存占用大570M,全都由JNI内存所贡献[4]。
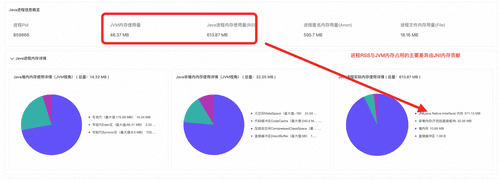
开启JNI(Java Native Interface)内存分配profiling,报告列出当前Java进程JNI内存分配调用火焰图,火焰图中为所有分配JNI内存的调用路径。(说明:由于是采样采集,火焰图中的内存大小不代表实际分配大小)。
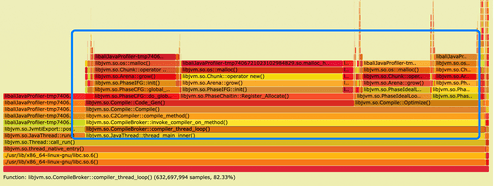
- 从内存分配火焰图中,我们可以看到主要的内存申请为C2 compiler正在进行代码JIT预热;
- 但是由于诊断的过程中没有发现pod有内存突增;所以我们进一步借助可以常态化运行的Java CPU热点追踪功能[5]尝试抓取内存升高时的进程热点,并通过热点对比[6]尝试对内存正常时的热点进行对比。
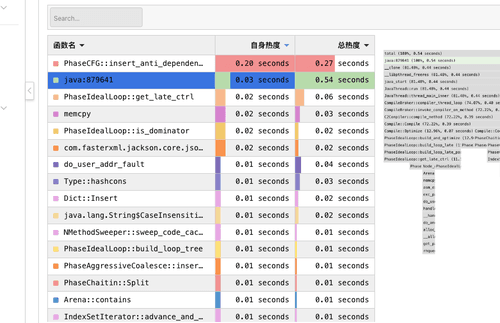
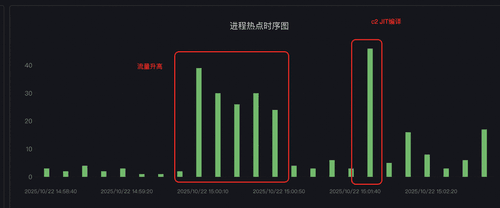
- 通过热点栈和热点分析对比,发现内存突增时间点的cpu栈也是c2 compiler的JIT栈,且c2 compiler热点前有部分业务流量突增,且业务代码使用了大量反射操作(反射操作会导致c2 compiler进行新的预热)。
**结论和解决方案:**
C2 compiler JIT过程申请JNI内存,且由于glibc内存空洞等原因导致申请内存放大且延时释放。
- 调整C2 compiler参数,让其编译策略更保守,可以尝试调整相关参数,观察内存消耗变化。
- 调整glibc环境变量MALLOC_TRIM_THRESHOLD_,让glibc及时将内存释放回操作系统。
总结
通过系统化的内存诊断方法,我们得以穿透JVM黑盒,揭示JNI、LIBC及OS层面的内存管理特性。阿里云操作系统控制台的内存全景分析功能,为容器化Java应用提供了从进程级到系统级的立体化诊断能力,帮助开发者精准定位内存异常根源,有效避免OOM事件的发生。
**相关链接**
【1】《一次内存诊断,让资源利用率提升 40%:揭秘隐式内存治理》
https://developer.aliyun.com/article/1690267
【2】云监控-ECS洞察-SysOM系统诊断
【3】操作系统控制台实例纳管
【4】操作系统控制台Java内存诊断
【5】操作系统控制台热点追踪
https://help.aliyun.com/zh/alinux/user-guide/process-hotspot-tracking
【6】操作系统控制台热点对比分析
https://help.aliyun.com/zh/alinux/user-guide/hot-spot-comparative-analysis