1. 客户场景与需求
很多客户已经在 AWS 侧用 OpenSearch 承载日志检索与分析,但在“成本可控 + 使用更省心 + 与周边系统打通”这三点上,会逐步遇到瓶颈。
1.1 计费复杂:最佳性价比组合需反复校准使用 OpenSearch Serverless时,成本通常拆成多项(口径比“按写入量计费”更复杂):
- Indexing OCU-hours:写入与索引计算资源(按小时计费)
- Search OCU-hours:查询与聚合计算资源(按小时计费,且与查询并发/扫描量/聚合复杂度相关)
- Managed storage(GB-month):数据在 S3 的托管存储(按月计费)
在日志这类高写入场景里,OCU 是“固定资源单元”(CPU/内存/本地存储)而不是“吞吐单位”,单个 OCU 实际能承载的写入吞吐需要压测校准;为了满足峰值写入与查询目标,往往需要预留更多 OCU,导致成本估算与调优成本更高。
对比之下,SLS 的核心费用口径更接近“写入量 → 费用”的线性关系(按写入 GB 计费),更容易做预算与治理。
1.2 隐性成本:生态对接不顺滑 + 持续治理投入
即便选择 Serverless 形态,生产可观测链路仍会带来一部分“看不见的运维/工程成本”:
- 与大数据系统打通:离线/实时计算、数据湖/对象存储、BI/报表等场景往往需要“投递、开放访问、跨账号权限与审计”能力。SLS 侧提供了直接投递与开放访问的方法,便于把日志数据投入后续治理与计算链路;而 OpenSearch 侧更常见的是通过额外管道/导出链路来对接,链路更长、权限与可靠性治理成本更高。
- OpenSearch 自身的持续治理:字段与 mapping 设计、索引/生命周期策略、查询与聚合优化、权限与多租户隔离、以及容量与成本的持续校准,仍需要长期投入;在写入峰值、字段膨胀或查询模式变化时,成本与性能往往需要反复压测与调整。
2. SLS 解决方案
2.1 从 OpenSearch 将数据导入 SLS
把 OpenSearch 里的数据“导入到 SLS 并能直接用于查询/告警/大盘”,听起来像一次搬运;但到了生产环境(历史索引大、增量不断、mapping 多样、线上查询不能受影响),导入链路必须同时做到:延迟可控、吞吐可控、失败可恢复、对源端影响可控。下面介绍一下opensearch数据导入的一些配置和设计。
2.1.1 导入能力与关键配置
- 导入模式:只导入历史数据(任务跑完自动结束)/ 自动导入新增数据(任务长期运行)
- 增量导入前提(原生支持):可配置时间字段(以及时间格式/时区)进行时间解析,用于增量边界计算与窗口推进
- 查询过滤:支持按 query 条件过滤导入范围(例如只导入某类业务/某些租户/某些环境)
- 写入处理器:支持在写入 SLS 前进一步做字段加工/清洗/脱敏/标签化(把“可观测口径”在接入时固化)
- 最大延迟时间:为应对源端写入/refresh 延迟导致的“迟到数据”,允许配置“最大延迟时间窗口”,把增量边界向过去回退,尽量降低遗漏概率
- 单次查询时间区间:允许用户自定义单次查询覆盖的时间范围(窗口长度),在实时性与源端压力之间做平衡
- 运行观测:导入配置/任务提供统计与报表,用于观测吞吐、延迟、失败与积压
参考:阿里云官方文档《导入 Elasticsearch 数据》:
2.1.2 导入过程遇到的挑战
- 挑战一:增量边界怎么推进,才能“既实时又尽量不漏”
- 增量导入本质是按时间窗口持续拉取,因此时间字段必须可配置、可解析、可对齐(格式/时区一致)。否则边界推进会不稳定,表现为“有时能追上、有时追不上”。
- 但即便时间字段没问题,源端仍可能存在 refresh/写入延迟:数据的时间戳已经落在窗口内,但当下查询不一定能立刻查到。此时“是否会漏”取决于源端在时间边界附近的可见性。
- 这类问题之所以难,不在于“能不能拉”,而在于要把边界条件想清楚并做出取舍:
- 用哪个时间字段做增量边界、时间格式/时区怎么解析(不一致会直接导致边界漂移)
- refresh/写入延迟带来的“迟到数据”如何处理(不处理就可能漏;处理得太激进又可能重复)
- 窗口拉多大、多久推进一次(窗口越大越压源端,窗口越小调度越频繁;两者都会影响实时性与稳定性)
- 挑战二:历史数据量大,任务要能切片、可恢复、可重跑
- 大量历史索引导入如果只靠“一次跑完”,失败后的恢复成本会非常高。
- 需要支持按索引/按时间片切分任务,并提供断点续传与重跑能力。
- 挑战三:对源端影响要可控
- 导入依赖查询与分页拉取,本质会消耗源端查询资源;并发过高或时间区间过大,会放大对源端的压力。
- 需要可配置的并发上限与速率限制,并配合合理的单次查询时间区间,避免影响线上读写。

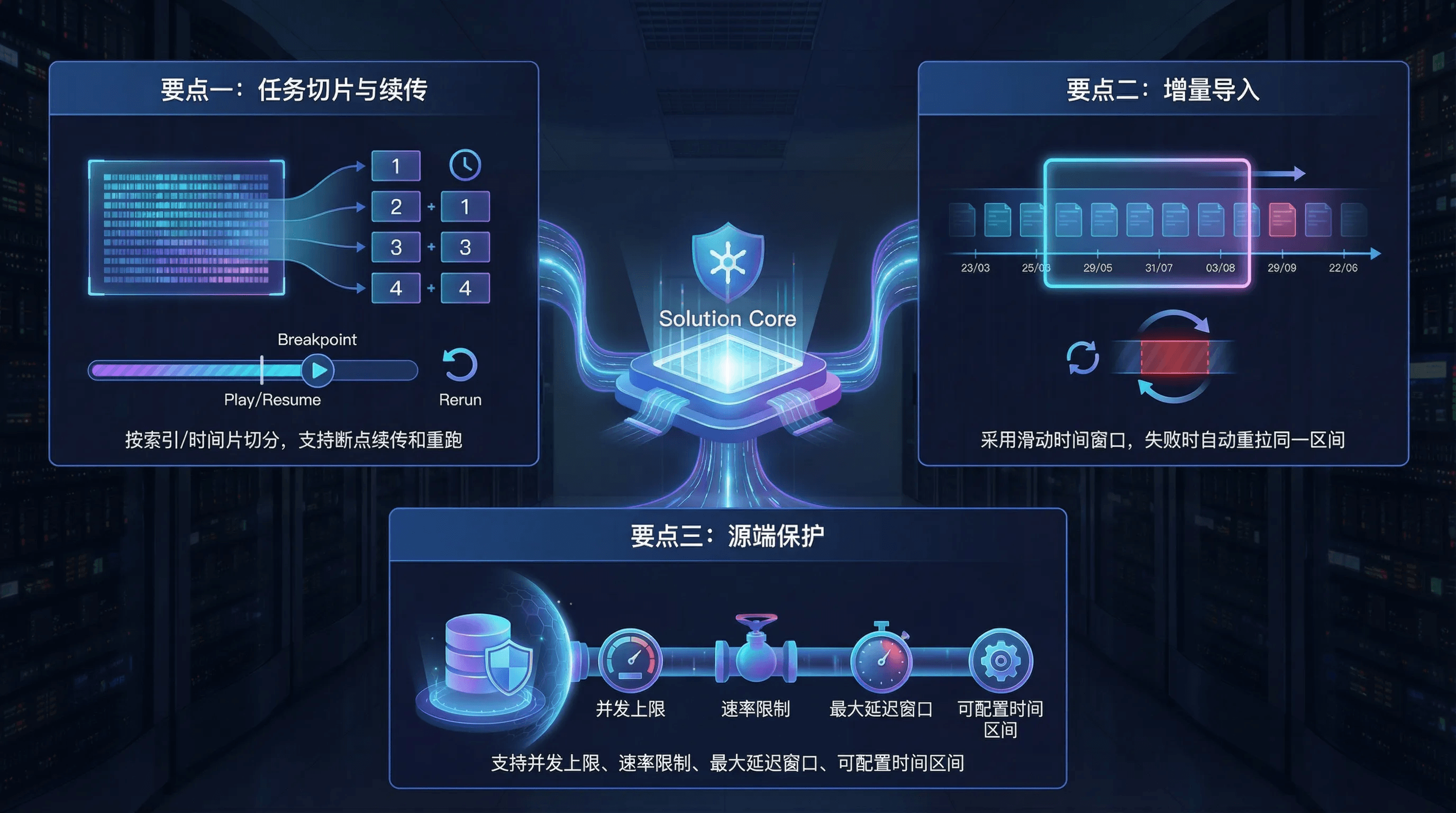
2.1.3 导入设计要点
- 要点一:任务切片(按索引/按时间片)+ 断点续传/重跑
- 历史数据导入支持按索引/按时间片切分任务,失败后可以从任务进度处恢复,或对指定时间片重跑补数。
- 要点二:增量导入用“滑动时间窗口”推进,失败自动重拉同一时间区间
- 系统按用户配置的“单次查询时间区间”拉取数据,并按固定步长向前平移窗口,实时性与源端压力都更可预测。
- 围绕“边界推进”这件事,我们把最关键的参数显式化(用户可按数据特性调优):
- 时间字段与解析规则:时间字段名、时间格式、时区;必要时可通过写入处理器统一 @timestamp、补齐时区、修正异常值
- 推进步长:窗口每次向前推进的幅度,决定“追实时”的速度与调度频率
- 这里不做幂等保证;“会不会丢数据”依赖 OpenSearch 的查询结果是否完整。
- 但可以保证:如果某个时间区间的结果在写入 SLS 过程中异常中断,下次会重新拉取同一时间区间的数据,尽量把“写入失败导致的缺口”补回来。
- 要点三:源端保护(并发上限、速率限制、最大延迟时间窗口、时间区间可配)
- 并发上限:可控的总并发,避免导入查询拖垮源端
- 速率限制:对查询/拉取侧做限速,避免占满源端线程池或拉爆网络
- 最大延迟时间窗口:当源端存在 refresh/写入延迟时,让增量边界回退,覆盖“迟到数据”,降低漏数风险(代价是可能重复)
- 单次查询时间区间:用户可按业务峰值与源端承载能力调节时间区间长度(区间越大,单次压力越大;区间越小,调度频率越高)
2.2 一站式数据分析
数据导入只是第一步,完整的可观测闭环还需要数据治理、交互式查询、可视化展示与智能告警。SLS 将这些能力整合在统一平台,以下介绍各环节的核心原理。
写入处理器:数据写入时处理
Elasticsearch/OpenSearch 支持 Ingest Pipeline,在 SLS 中提供了更高性能的实现。
数据写入 Logstore 前,可以使用写入处理器(IngestProcessor)在入库前对数据进行处理,例如数据过滤、字段提取、字段扩展、数据脱敏。如下图所示:
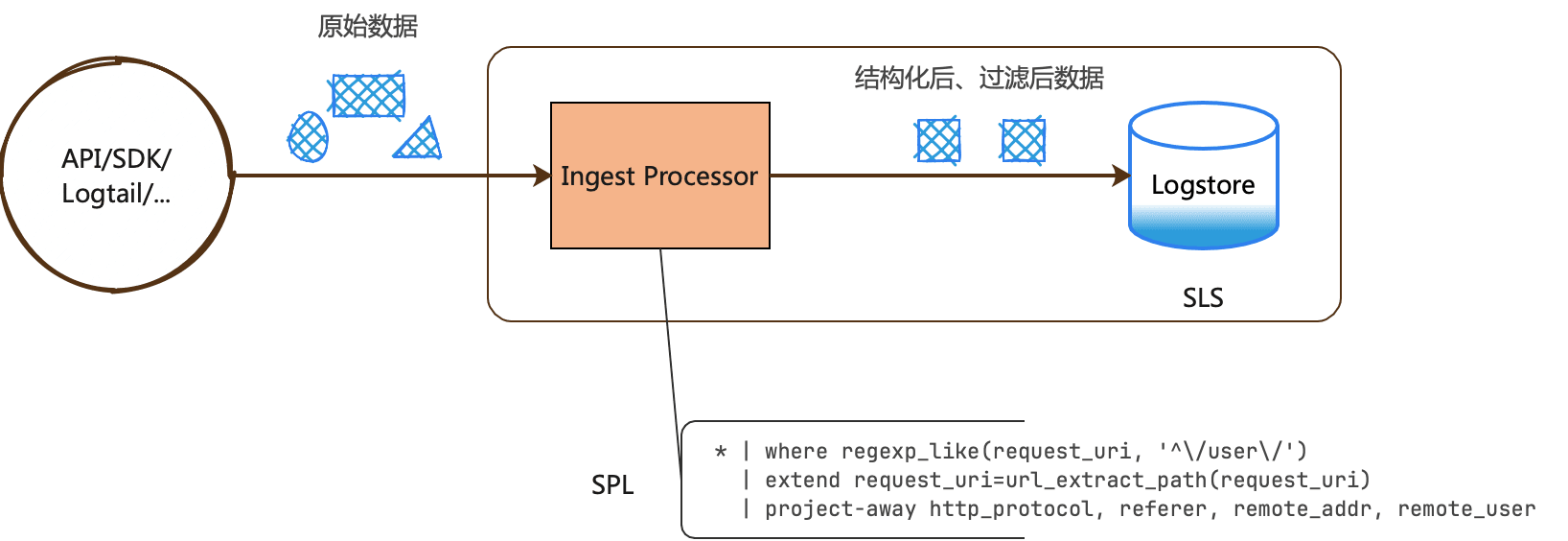
SLS 在日志 Pipeline 上以 SPL 引擎作为内核,包括列式计算、SIMD 加速、C++ 语言实现等优势。基于 SPL 引擎进行分布式架构,我们重新设计了弹性的机制,不止是通常意义上按实例(K8s Pod 或是 服务 CU)粒度的伸缩,是按照 DataBlock 粒度(MB 级别)快速弹性。
场景能力:
- 合规前置:在海外侧完成 IP → Geo 转换、信息脱敏等。
- 数据过滤:剔除无效数据,减少下游索引与存储开销。
- 结构化抽取:把原始字段加工为可分析的指标,解析嵌套 JSON 等,避免查询时重复计算。
查询分析:高性能引擎,兼容Elasticesearch/OpenSearch
SLS 提供高性能查询引擎,支持索引模式(秒级响应百亿级数据)与扫描模式(轻量级分析)。查询直接作用于索引,无需预建数据集或刷新延迟。针对超大规模数据分析场景,SLS 提供 SQL 独享版,包括 SQL 增强和 SQL 完全精确两种模式。

查询引擎与能力:
- 近百种分析函数:内置统计、聚合、字符串、时间、地理等函数,开箱即用。
- 跨库联合查询:通过 StoreView 支持跨 Project、跨 Logstore 的数据关联查询。
- SQL 独享版:大数据量场景下提供高精度分析能力,避免采样误差。
- 定时 SQL:支持定时执行 SQL 查询,用于报表生成与指标预计算。
兼容Elasticesearch/OpenSearch:
SLS提供的Elasticsearch兼容接口,其兼容机制是将Elasticsearch DSL查询翻译为日志服务的索引查询和SQL分析查询,并且按照Elasticsearch的API格式规范返回查询分析结果,从而实现Elasticsearch查询协议的兼容。

仪表盘:丰富可视化,无缝对接Kibana/Grafana
SLS 仪表盘是日志服务提供的数据可视化工具,将查询分析结果以图形化界面展示。仪表盘通常包含多个统计图表,汇总并呈现关键性能指标、重要数据和分析结果。
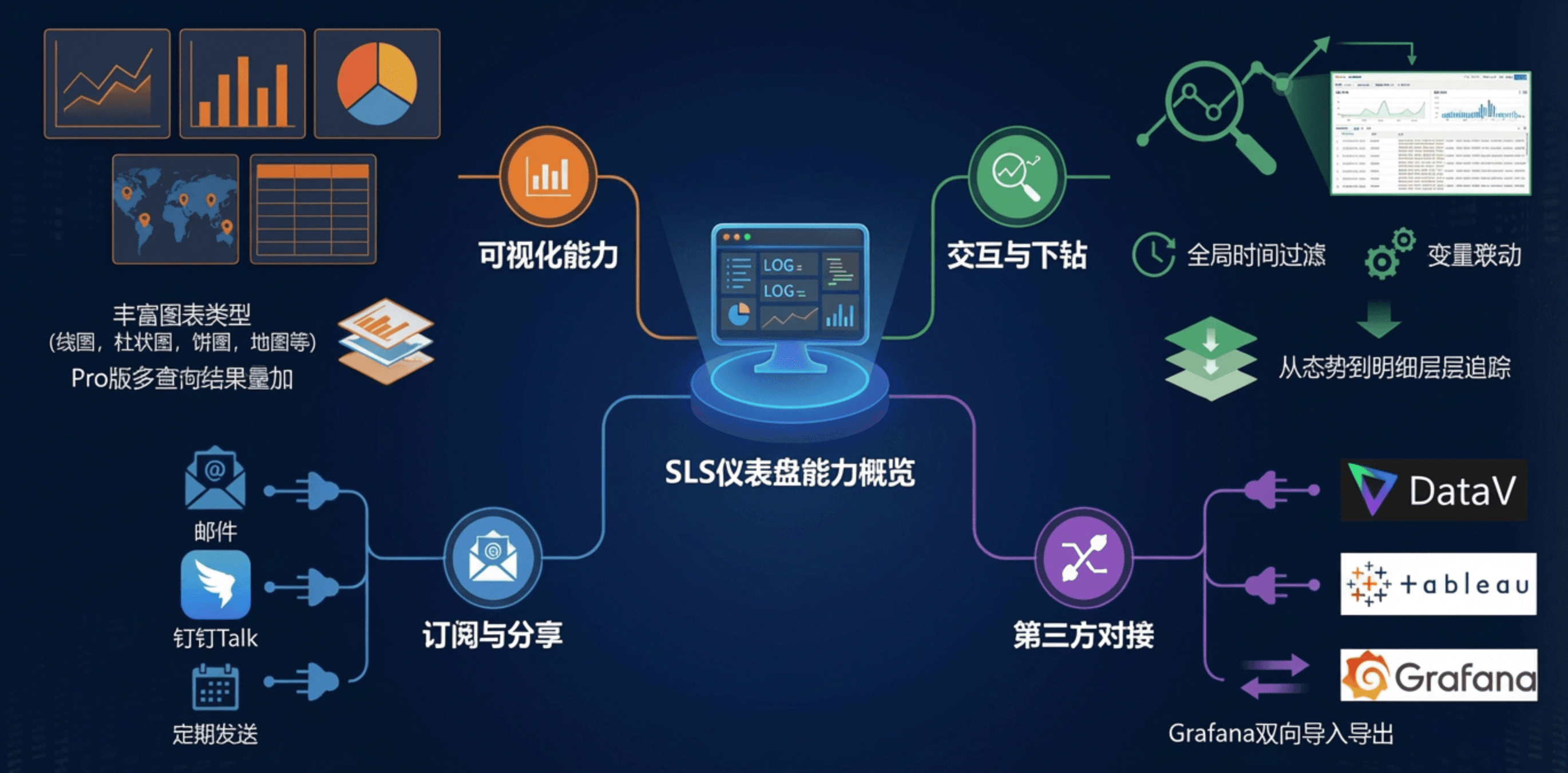
可视化能力:
- 丰富图表类型:支持表格、线图、柱状图、饼图、地图等多种统计图表,Pro 版本支持多查询结果叠加展示。
- 交互与下钻:支持全局时间过滤、变量联动、图表下钻,从态势到明细层层追踪。
- 订阅与分享:支持定期将仪表盘渲染为图片,通过邮件或钉钉群发送;支持控制台内嵌到第三方系统。
对接Kibana:
对于已经在Kibana上实现Elasticsearch日志可视化,需要将日志数据从Elasticsearch迁移到SLS的场景,可以使用SLS提供的Elasticsearch兼容接口,无需改动业务代码。

对接Grafana:
针对习惯使用Grafana分析Elasticsearch数据,需要将Elasticsearch数据迁移到SLS的场景,SLS提供兼容Elasticsearch的接口,便于他们使用Grafana的Elasticsearch数据源插件访问日志服务进行查询和分析。
2.3 运维简化,降低成本
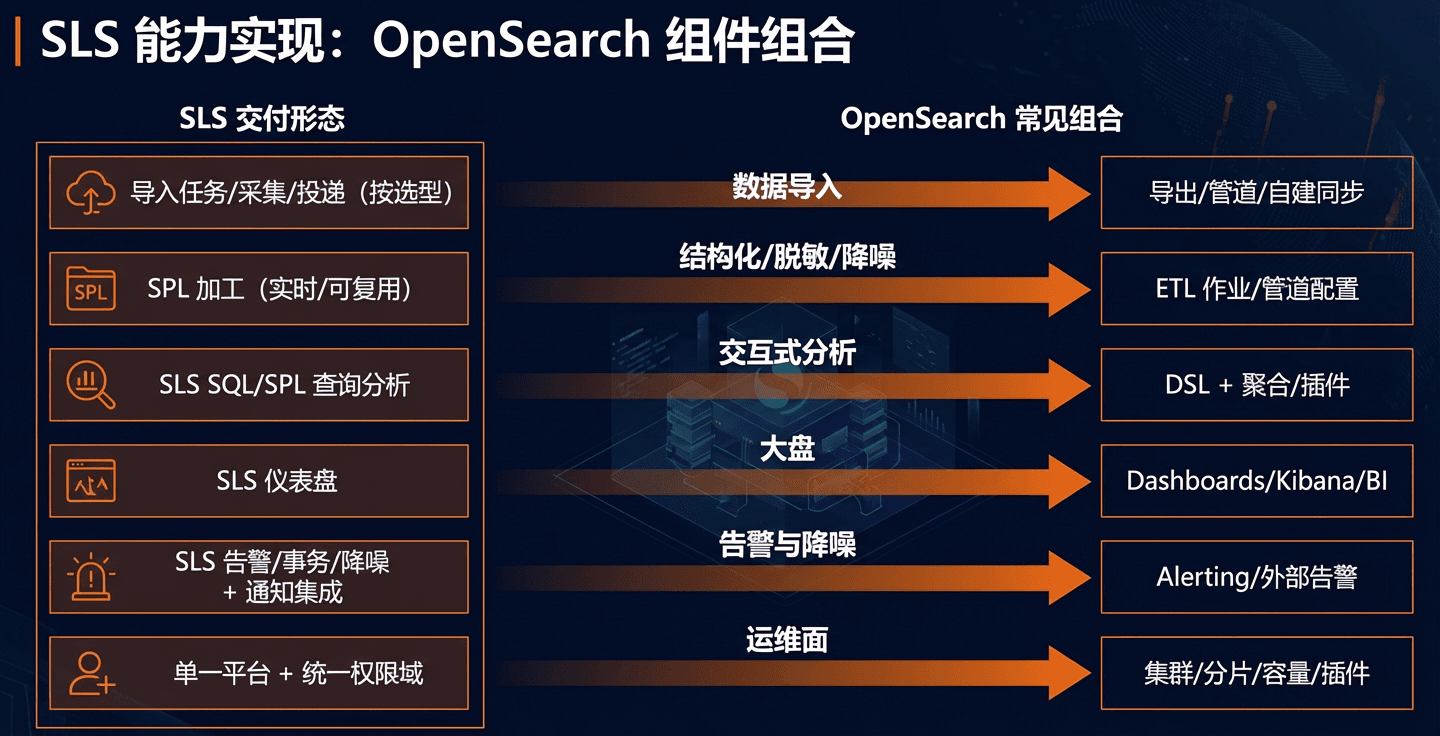
2.3.1 OpenSearch 侧常见拼装形态(为了实现同样闭环通常要哪些组件)
如果你选择 OpenSearch Serverless,可以把“集群/节点/分片”等运维显著简化。要实现与 SLS 类似的“导入 → 加工 → 查询 → 大盘 → 告警 → 处置/联动”闭环,可能需要使用以下 OpenSearch/AWS 已提供的托管能力进行组合:
- 索引与检索(OpenSearch Serverless):Time series collection(日志/可观测常用形态)
- 数据采集/投递(源 → OpenSearch):Kinesis Data Firehose / OpenSearch Ingestion(OSI)
- ETL/清洗(写入前处理):OSI pipeline(字段清洗/补全/脱敏/路由等);(可选)OpenSearch ingest pipeline(如适用)
- 查询分析(检索+聚合):OpenSearch Query DSL + Aggregations
- 可视化(大盘):OpenSearch Dashboards(Discover/Visualize/Dashboard)
- 告警与通知:Dashboards Alerting/Notifications → Webhook / SNS / Chatbot
- 处置与联动:SNS / EventBridge → Lambda / Runbook / 工单系统(把“闭环动作”外置到通用服务)
- 存储与归档:Serverless Managed storage(S3);按热数据窗口/访问老数据的延迟做权衡
- 权限与审计:IAM + 访问控制策略(按账号/租户模型落地)
组件多并不一定不好,但当诉求是“统一口径、分钟级闭环、低成本可控”,多组件意味着:
- 链路更长、故障面更大
- 计费更碎、归因更难
- 人力投入更高(长期治理)
2.3.2 SLS 一体化:替代关系如何写成“可交付清单”
在 SLS 内把“导入 + 加工 + 索引 + 查询 + 大盘 + 告警/事务”做成一个可复用的工程模板,用以简化运维降低成本。
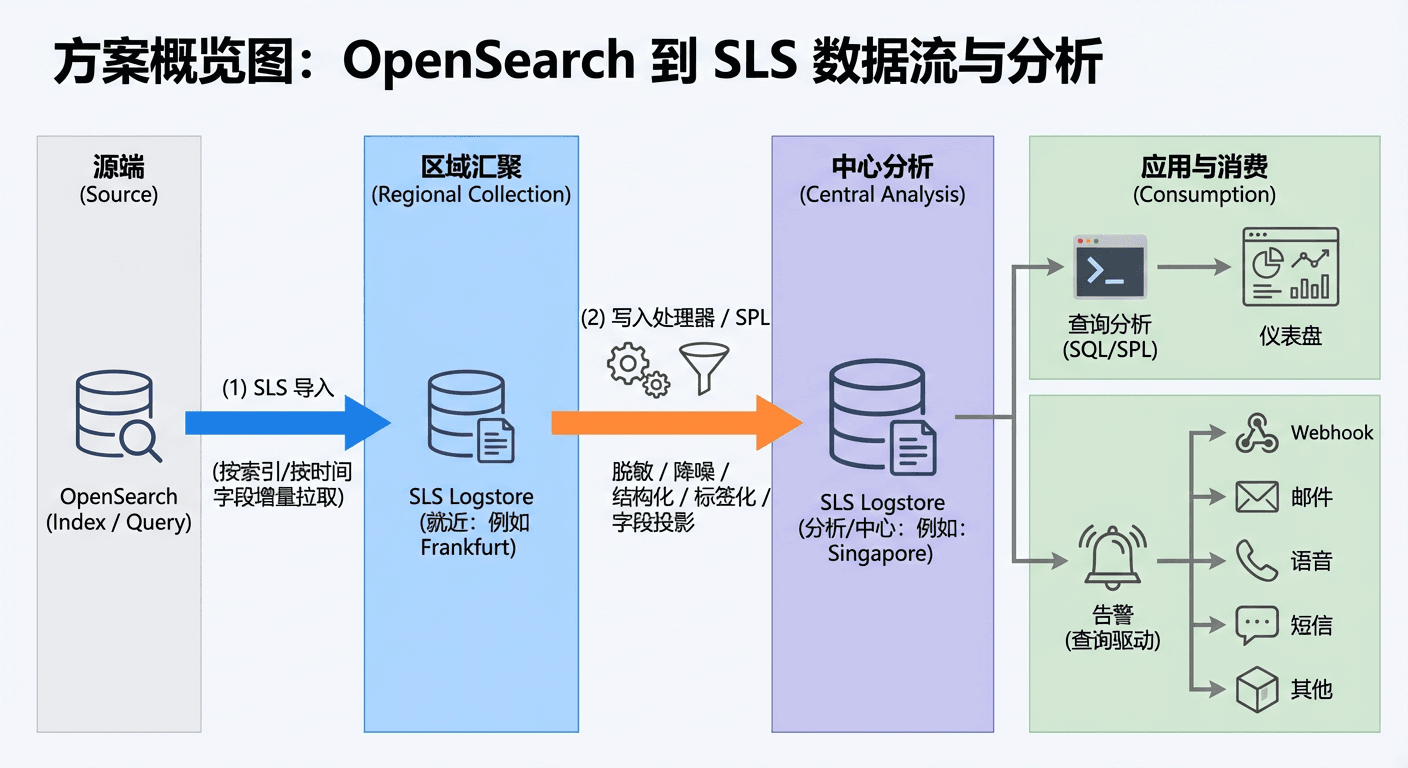
3. 多云环境下统一可观测性平台案例
背景与解决方案
以游戏出海企业为例,由于游戏业务对稳定性、已经网络的极至需求,往往会采用多云架构,在不同国家和地区采购不同云产商的资源,其中网络资源是重头,比如CDN、ALB。对应而言,网络监控就成为运维工作的重点,客户选择SLS做为运维的统一平台。以AWS WAF日志为例,客户通过Centralized Logging将AWS WAF访问日志接入AWS OpenSearch,再通过SLS的OpenSearch导入功能,最终将数据写入SLS实现网络监控。新架构的目标是实现:
- 统一查询分析:在新加坡中心 Logstore 汇聚黄金数据,提供亿级数据秒级交互式查询。另外,SLS兼容Elasticesearch/OpenSearch查询接口,最大程度保障Elasticsearch查询分析方案迁移的平滑度,降低将日志引擎从Elasticsearch切换为日志服务的使用难度。
- 统一可视化:一站式仪表盘,无需额外 BI 工具。无缝对接Kibana/Grafana,用户可以在Kibana/Grafana中查询和分析日志服务中的数据。
- 统一告警闭环:基于SLS查询分析的智能告警,支持降噪、分派与多渠道通知。
3.1 数据链路
以AWS WAF日志为例,客户的数据链路如下:
- 对AWS云产品的请求经过WAF Web ACL控制时记录访问日志
- 访问日志写入AWS OpenSearch
- SLS数据导入功能从OpenSearch同步数据至SLS Logstore
- 在Kibana/Grafana查询/分析存储在SLS的数据,实现数据迁移之后的无感切换
- SLS告警功能定时分析WAF访问日志,发现异常时通知至监控者

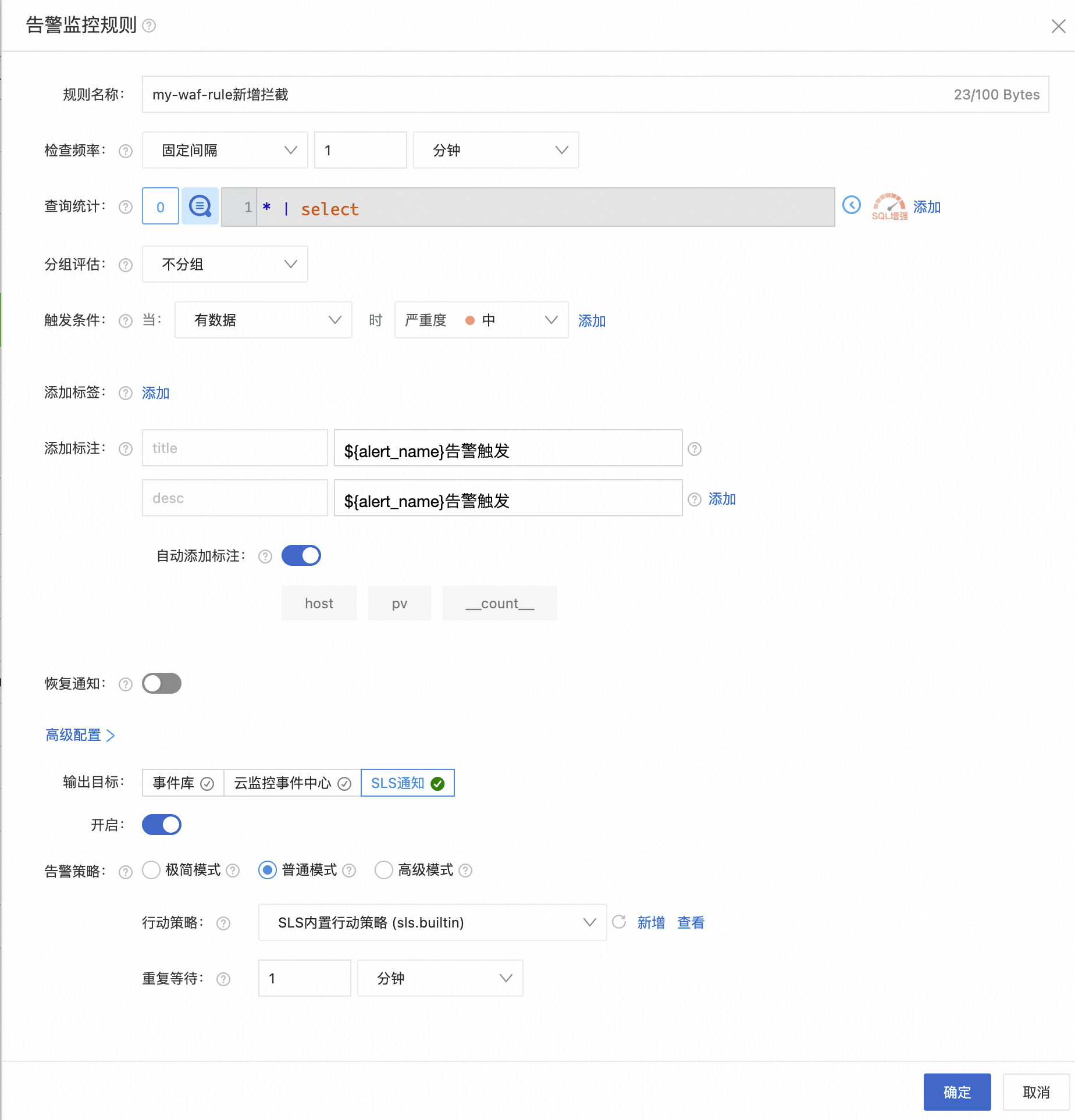
3.1.1 告警规则示例
**告警 1:特定**CloudFront **WAF规则出现拦截,快速发现CDN异常**
labels: my-waf-rule and action: BLOCK
| select
count(*) as pv,
json_extract(httpRequest, '$.host') as host
group by
host
order by
pv desc
**告警 2:特定**保护包(web ACL)非终止规则**触发,监控** SQL 注入和跨站脚本攻击(XSS)
nonTerminatingMatchingRules: monitor_xss
| select
distinct("httpRequest.host") as host
3.1.2 查询分析示例
**示例 1:使用**ES Lucene的语法,在Grafana中绘制QPS趋势曲线,访问存储在SLS的数据
**示例 2:分析Host被**保护包(web ACL)终止规则拦截的相关性
action: BLOCK | select
terminatingRuleId as rule,
"httpRequest.host" as host,
count(1) as count
group by
rule,
host
order by
count desc

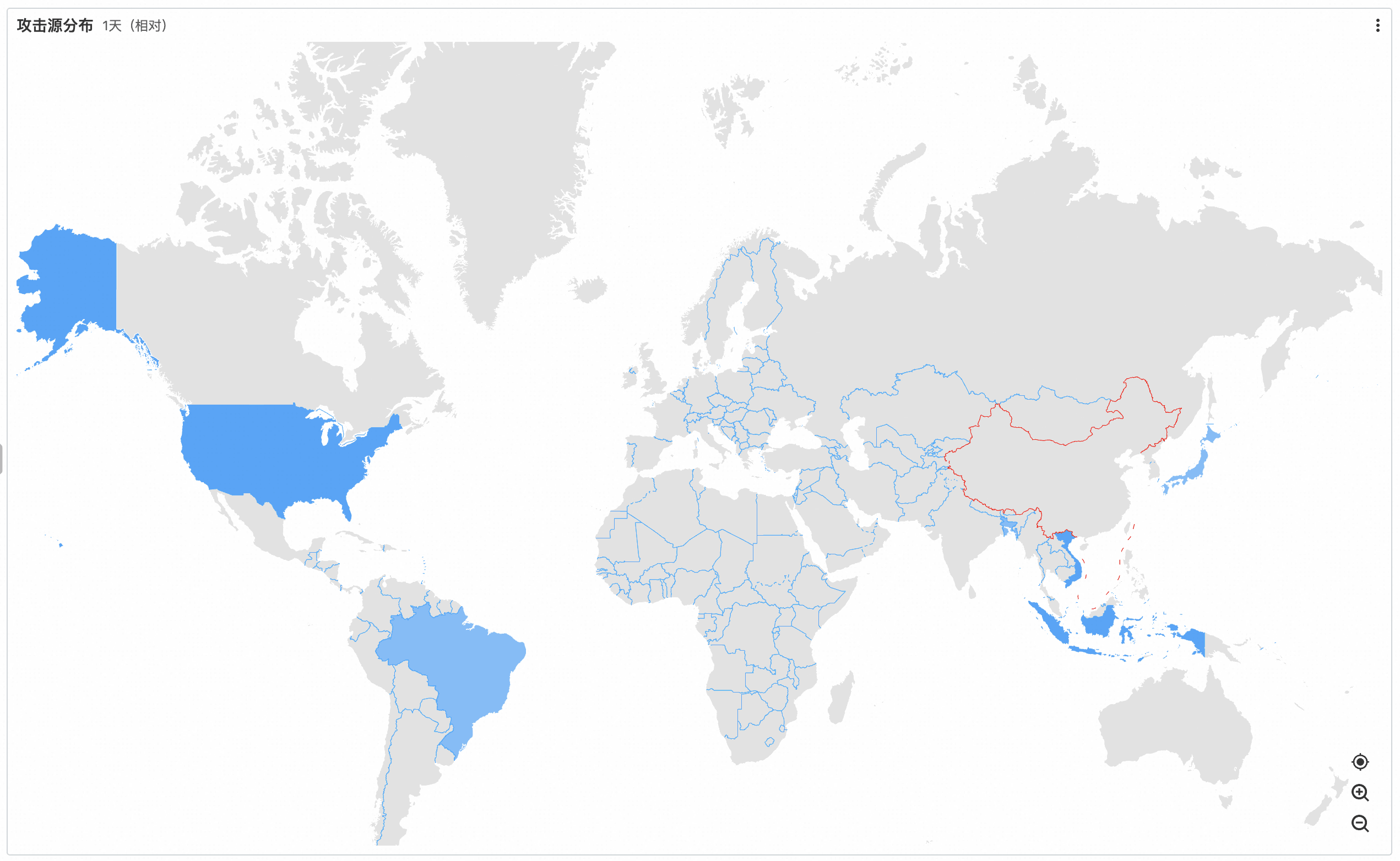
**示例 3:可疑攻击源地域分布**
action: BLOCK | select
COALESCE(
ip_to_country(clientIp),
ipv6_to_country(clientIp)
) as clientCountry,
COALESCE(ip_to_city(clientIp), ipv6_to_city(clientIp)) as clientCity,
count(1) as pv
from(
select
json_extract_scalar(httpRequest, '$.clientIp') as clientIp
FROM log
)
group by
clientCountry,
clientCity
having
clientCountry is not null
order by
pv desc
limit
10
3.2 成本对比(SLS vs OpenSearch)
本节以“能力对齐”的方式做端到端 TCO 对比,覆盖在同一平台完成数据导入、加工、存储与索引、查询分析、告警与可视化所需的主要成本项。对标侧选择 Amazon OpenSearch Serverless(Time series collection)作为参考,并将 OpenSearch → SLS 的网络出站费用单列纳入端到端口径。
3.2.1 口径与参数
- 数据量:1 TB/天;保留 30 天(按 30 天/月、730 小时/月折算)
- Region:US East (N. Virginia)
- OpenSearch → SLS 公网出站:按压缩后约为原始的 1/7 估算
- OpenSearch Serverless:不启用冗余活动副本(非冗余部署)
- OpenSearch Serverless 资源分配口径:热存储保留 1 天;更早数据转为归档数据;整体保留期到 30 天后删除(参考AWS Blogs)
**3.2.2 单价来源**
- SLS 定价:Alibaba Cloud Log Service Pricing
- OpenSearch(Serverless/OSI)定价主入口:Amazon OpenSearch Service Pricing
- OCU sizing 参考:Amazon OpenSearch Serverless – cost-effective search capabilities at any scale(AWS Blog)
- 存储估算口径参考:Calculating storage requirements(Developer Guide)
- AWS 公网出站定价(Data Transfer):Amazon EC2 On-Demand Pricing(Data Transfer)
**3.2.3 分项拆账(按月估算)**
基础换算
- 1 TB = 1,024 GB
- 日写入量:1 TB/天 = 10,24 GB/天
- 月写入量(raw_size):10,24 × 30 = 307,20 GB/月
SLS 侧
- 写入费用:1,024 × 0.061 × 30 = 1,873.92 USD/月
- 公网出站(OpenSearch → SLS):
- 出站体积(压缩后):1,024 ÷ 7 = 146.29 GB/天
- 月出站:146.29 × 30 = 4,388.57 GB/月
- 免费额度:前 100 GB/月 → 计费量:4,388.57 - 100 = 4,288.57 GB/月
- 分段计价(Data Transfer,示例按常见分段):
- First 10 TB:4,288.57 × 0.09 = 385.97 USD
- 出站合计:385.97 USD/月
OpenSearch Serverless 侧
- 计算(OCU-hours):
- OCU 单价:0.24 USD/OCU-hour(Indexing / Search 同价)
- Index_OCU / Search_OCU 取值与计算逻辑(示例口径):
- 热数据窗口:1 天
- 热数据量(GiB):1 TB/天 = 1,024 GiB/天
- 按 AWS Blog 的 time-series sizing 示例:1 TiB 热数据通常按 10 OCU 规划(基于 120 GiB/OCU 的估算取整方式,示例见AWS Blogs)
- Index_OCU = 10
- Search_OCU = 10
- 计算费用:(10 + 10) × 0.24 × 730 = 3,504.00 USD/月
- 存储(Managed storage,按 AWS Blog:time-series collection 仅保留最近 1 天在本地,其余数据存于 S3;对 S3 存储按 GB-month 计费):
- 存储费用:raw_size 30,720 × 0.024 = 737.28 USD/月
| 成本项 | 计算方式(示例) | 月费用(USD) |
|---|---|---|
| SLS 写入 | 1,024 × 0.061 × 30 | 1,873.92 |
| 公网出站(OpenSearch → SLS) | (1,024 ÷ 7)× 30,按 Data Transfer 分段计价 | 385.97 |
| SLS 合计 | 2,259.89 | |
| OpenSearch Serverless 计算 | (Index\_OCU 10 + Search\_OCU 10) × 0.24 × 730 | 3,504.00 |
| OpenSearch Serverless 存储 | raw\_size 30,720 × 0.024 | 737.28 |
| OpenSearch 合计 | 4,241.28 |
**3.2.4 费用汇总**
- SLS 端到端(月度):2,259.89 USD/月
- OpenSearch 端到端(月度):4,241.28 USD/月
- 月度节省:1,981.39 USD/月
- 成本降低:约 46.72%
说明:本节为便于对比,OpenSearch Serverless 按非冗余部署口径测算,成本更低但可用性会受影响。若按线上常见的冗余部署口径(AWS Blog冗余模式下 indexing/search 计算资源会 ×2,见:Amazon OpenSearch Serverless cost-effective search capabilities, at any scale),则对标侧月度成本约为 7,745.28 USD/月,此时 SLS 的端到端月度节省约为 5,485.39 USD/月,成本降低约 70.82%。
**3.2.5 结论**
OpenSearch → SLS 导入链路默认以 gzip 压缩传输,因此本文用“压缩后约为原始的 1/7”估算公网出站并纳入端到端口径。在此假设下:
- SLS 端到端月度 TCO ≈ 2,259.89 USD/月
- 对标侧按 OpenSearch Serverless(Time series collection,非冗余部署,热存 1 天)端到端口径估算 ≈ 4,241.28 USD/月(Serverless 计算 + Managed storage)
- 端到端月度节省 ≈ 1,981.39 USD/月,成本降低 ≈ 46.72%
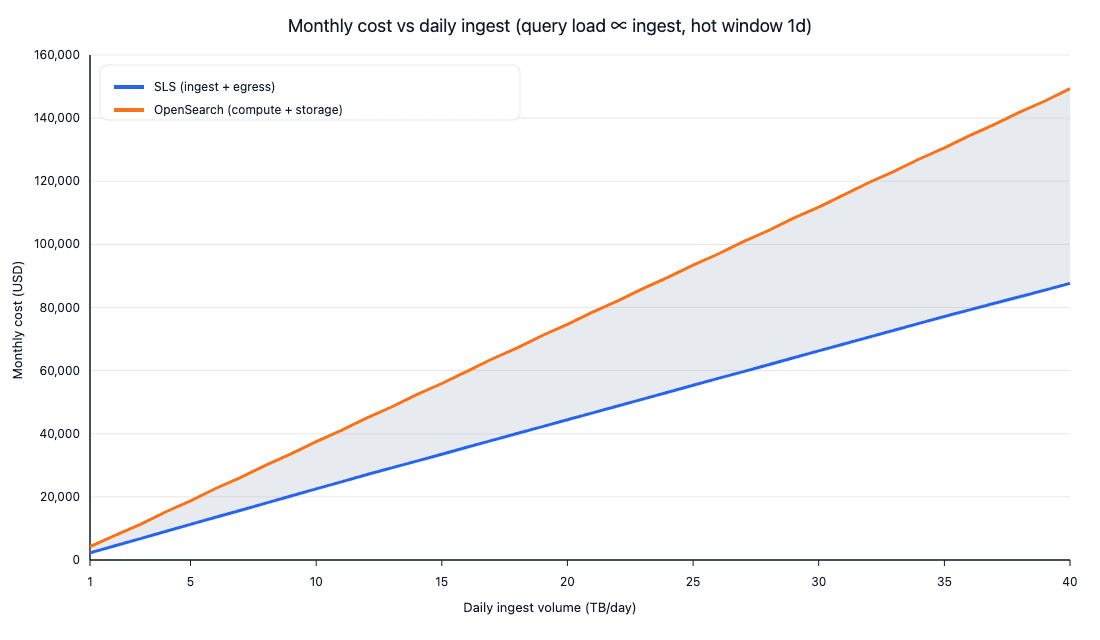
SLS vs OpenSearch(月度成本随日导入量增长对比)
注:随着日写入量从 1–40 TB/天增加,SLS 的月度端到端成本始终低于 OpenSearch Serverless,且两者的绝对成本差额随数据量扩大
除直接成本外,SLS 可在同一平台内完成导入、加工、查询、告警与可视化闭环,减少多组件拼装带来的运维与口径分裂成本。
4. 总结展望
SLS 在同一平台内覆盖 OpenSearch 在可观测场景的核心链路:数据导入、写入加工(SPL/写入处理器)、查询分析(SQL/SPL/ES 协议兼容)、仪表盘、告警与联动闭环。同时在本文 3.2 的口径下,SLS 端到端成本降低约 46.72%。
目前我们已经沉淀了丰富的迁移案例,为尽量不break用户使用习惯,迁移可以分两步走:
- 第一步(导入方案,先获得 SLS 的使用体验):通过 SLS 的 OpenSearch 数据导入能力,把历史 + 增量数据同步到 SLS,快速落地查询分析、仪表盘与告警联动,在不改业务读写链路的前提下先把可观测闭环跑起来。
- 第二步(ES 读写完全兼容方案,逐步替换):基于 SLS 的 Elasticsearch 兼容接口,逐步把应用侧的读写、以及 Kibana/Grafana 等生态访问迁移到 SLS,实现对 Elasticsearch/OpenSearch 协议的读写兼容与统一承载。