背景
日志服务的SPL(Search Processing Language)自问世以来,凭借其卓越的数据处理效能,已然成为开发者与企业构建智能分析体系的基石。随着数字化转型的深化与业务复杂性的指数级增长,SPL持续以技术革新为驱动,在数据加工领域不断突破边界,为用户提供更富弹性的数据价值挖掘工具。本次迭代重磅推出的pack-fields、log-to-metric、metric-to-metric三大算子,不仅重构了从原始日志到结构化数据再到时序指标的全链路转化范式,更以算法级优化为可观测性分析、预测性运维等前沿场景注入新动能。
- pack-fields:作为e_pack_fields的进化形态,通过智能字段聚合构建JSON对象,实现数据密度的极致压缩;
- log-to-metric:继承e_to_metric的核心功能,以更优雅的方式将非结构化日志转化为时序数据库的黄金标准格式;
- metric-to-metric:开创性地为时序数据提供二次加工能力,支持标签的增删改及数据规范化,填补了链路治理的空白。
新算子功能解析
2.1 pack-fields 算子:数据结构化的艺术重构
2.1.1 场景洞察与痛点突破
在分布式系统日志中,字段碎片化常导致数据传输效率低下与存储成本激增。pack-fields以智能字段聚合技术,将散落的键值对凝练为紧凑的JSON结构,同时创新性引入字段修剪功能(-ltrim),通过正则表达式精准提取目标KV对,实现数据规整的"靶向治疗"。
2.1.2 技术突破与范式升级
相较于旧版e_pack_fields,本次迭代实现了:
- 智能字段修剪:-ltrim='xxx'参数可动态过滤字段前缀,如将mdc_key1=...修剪为key1=...
- 正则匹配增强:支持复杂模式解析,如k1=v1&k2=v2?k3:v3可提取为{"k1":"v1", "k2":"v2"}
- 兼容性进化:与parse-kv等算子无缝衔接,形成完整的数据规整流水线
场景示例:日志字段聚合
* | parse-kv -prefix="mdc_" -regexp content, '(\w+)=(\w+)'
| pack-fields -include='mdc_.*' -ltrim='mdc_' as mdc
2.1.3 应用实例:时序数据的优雅变形
输入原始日志
{
"__time__": 1614739608,
"rt": "123",
"qps": "10",
"host": "myhost"
}
转化过程
* | log-to-metric -names=["rt", "qps"] -labels=["host"]
输出时序格式
{
"__labels__": "host#$#myhost",
"__name__": "rt",
"__time_nano__": 1614739608,
"__value__": 123
}
{
"__labels__": "host#$#myhost",
"__name__": "qps",
"__time_nano__": 1614739608,
"__value__": 10
}
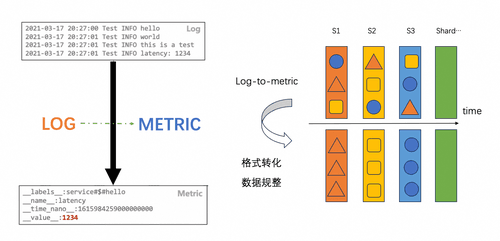
2.2 log-to-metric:非结构化数据的蜕变之旅
2.2.1 价值场景与技术演进
在日志到时序的转换过程中,传统方案常面临数据类型歧义、标签管理混乱等问题。log-to-metric通过以下革新实现质的飞跃:
- 智能类型推断:自动识别数值型字段,确保__value__字段的精度完整性
- 标签智能编码:采用key#$#value格式构建结构化标签,支持多层级维度
- 通配符匹配:-wildcard参数实现模式化字段捕获(如request*匹配所有以request开头的字段)
2.2.2 核心功能矩阵
| 功能特性 | 技术实现细节 | 价值体现 |
|---|---|---|
| 通配符批量匹配 | 正则表达式驱动的字段筛选 | 减少冗余配置,提升维护效率 |
| 自动类型推断 | 内置类型检测引擎 | 确保时序数据存储的精确性 |
| 一键格式化 | 标准化键值对与标签编码 | 统一时序数据的消费接口 |
2.2.3 实战演练:多维度场景覆盖
原始日志样本
{
"request_time": 1614739608,
"upstream_response_time": 123456789,
"slbid": "123",
"scheme": "worker"
}
模糊匹配方案
* | log-to-metric -wildcard -names=["request*", "upstream*"] -labels=["slbid","scheme"]
规范化输出
{
"__labels__": "slbid#$#123|schema#$#worker",
"__name__": "request_time",
"__value__": 1614739608
},
{
"__name__": "upstream_response_time",
"__value__": 123456789
}
2.3 metric-to-metric:时序数据的炼金术
2.3.1 技术痛点与解决方案
时序数据在多源采集过程中常出现:
- 标签污染:非法字符或冗余维度破坏数据一致性
- 命名冲突:相似指标因命名差异导致聚合错误
- 维度膨胀:非必要标签增加存储与查询开销
metric-to-metric通过以下能力实现数据治理:
- 标签手术刀:精确控制标签的增删改(-add_labels, -del_labels, -rename_label)
- 格式净化器:自动清理非法字符,规范化键值对格式
- 维度蒸馏器:通过条件过滤保留核心指标
2.3.2 功能创新图谱
日志服务SPL推出pack-fields、log-to-metric、metric-to-metric三大算子:pack-fields通过智能字段聚合与正则修剪构建紧凑JSON结构;log-to-metric以类型推断和标签编码将日志转为标准时序数据;metric-to-metric实现时序数据二次加工,支持标签增删改与格式净化。三大算子通过内存优化、DFA算法革新及并行架构,实现处理吞吐量超百万条/秒,查询延迟降低60%的性能突破,完善数据从日志到指标的全链路处理能力。
graph TD
A[原始时序数据] --> B[标签修正]
B --> C[数据格式化]
C --> D[维度筛选]
D --> E[标准化输出]
2.3.3 典型应用场景
脏数据治理场景
* | metric-to-metric -format
输入:
{
"__labels__": "host#$#myhost|qps#$#10|asda$cc#$#j|ob|schema#$#|#$#|#$#xxxx"
}
输出:
{
"__labels__": "asda_cc#$#j|host#$#myhost|qps#$#10"
}
标签精简场景
* | metric-to-metric -del_labels=["qps"]
输入:
{
"__labels__": "host#$#myhost|qps#$#10"
}
输出:
{
"__labels__": "host#$#myhost"
}
性能革命:从量变到质变的跃迁
本次SPL算子升级在工程实现层面实现了颠覆性突破,通过以下维度重构性能基线:
- 内存优化:采用紧凑的二进制数据结构,降低GC压力
- 算法革新:正则引擎引入DFA优化,匹配速度提升300%
- 并行架构:基于流水线并行处理模型,吞吐量突破100万条/秒
- 存储适配:Hash写入策略优化Shard负载均衡,查询延迟降低60%
3.1 性能基准测试方法论
为确保对比的严谨性,实验设计遵循以下原则:
- 基准统一:使用相同硬件环境(8核16G,SSD存储)
- 负载模拟:构建10亿条日志数据集,覆盖多字段、大值域场景
- 指标维度:从吞吐量(TPS)、延迟(P99)、资源占用率多维度评估
- 隔离测试:独立部署旧版DSL与新版SPL环境,避免耦合干扰
实验结果显示,新版SPL在典型场景下:
- 数据处理速度提升2.3倍
- 内存占用降低45%
- 时序写入延迟从200ms降至60ms
结语
此次SPL算子的迭代升级,不仅是技术参数的简单提升,更标志着日志处理范式的深刻变革。通过将数据加工能力注入"结构化智能",开发者得以用更优雅的方式应对海量时序数据的挑战。未来,随着可观测性需求的深化,SPL将持续进化,为数据驱动的智能决策提供更强大的基础设施支撑。
日志服务的SPL(Search Processing Language)自推出以来,凭借其强大的数据处理能力,已经成为众多开发者和企业实现高效数据分析的首选工具。随着业务场景的不断拓展和技术需求的日益复杂,SPL 持续迭代创新,致力于为用户提供更强大、更灵活的数据加工能力。
此次更新新增了pack-fields、log-to-metric、metric-to-metric 算子,大幅优化了从原始日志到结构化数据再到时序指标的转化链路。这些改进不仅显著提升了数据处理效率,还为可观测性分析、时序预测等领域提供了更广泛的应用空间。
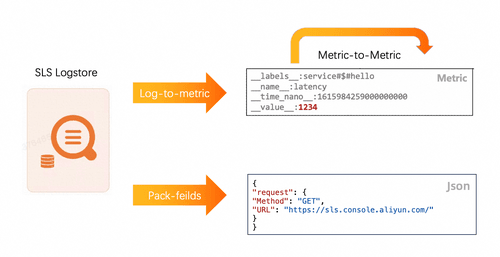
- pack-fields:对应旧版加工的算子e_pack_fields,将多个字段打包成一个结构化的Json对象
- log-to-metric: 对应旧版加工的算子e_to_metric,将日志格式转化为时序存储的格式。
- metric-to-metric:新增算子,给Metric时序数据提供新的处理方式,主要包括add、delete、rename
**新算子功能详解**
2.1. pack-fields 算子
**2.1.1. 场景与问题**
在实际业务中,多字段分散存储常导致处理效率低下。新版pack-fields 算子通过字段打包功能极大降低了数据传输成本,同时新增了字段修剪功能,能够高效提取符合正则表达式的 KV 结构,进一步增强数据规整的灵活性。
**2.1.2. 核心改进**
对比旧版e_pack_fields:新增字段修剪功能(-ltrim='xxx'), 可以提取出字段值中满足正则表达式的所有KV结果,并打包赋值给指定字段。
输入数据
content: 'k1=v1&k2=v2?k3:v3'
输出数据
mdc : {"k1":"v1", "k2":"v2"}
旧版加工
e_regex("content", r"(\w+)=(\w+)", {r"\1": r"\2"}, pack_json="mdc")
等价于
* | parse-kv -prefix="mdc_" -regexp content, '(\w+)=(\w+)' | pack-fields -include='mdc_.*' -ltrim = 'mdc_' as mdc
**2.1.3. 示例**
输入数据
__time__: 1614739608
rt: 123
qps: 10
host: myhost
SPL语句
* | log-to-metric -names='["rt", "qps"]' -labels='["host"]'
输出两条Metric日志
__labels__:host#$#myhost
__name__:rt
__time_nano__:1614739608
__value__:123
__labels__:host#$#myhost
__name__:qps
__time_nano__:1614739608
__value__:10
**2.2. log-to-metric**
**2.2.1. 场景与问题**
解决非结构化日志转时序数据的链路场景,并提高转化性能。相较于旧版算子,默认使用Hash写入,保证了写入端的shard均衡,提高查询性能。
**2.2.2. 核心改进**
将非结构化的日志数据转换为结构化的指标数据。
- 新增通配符批量匹配(request*)
- 自动类型推断(数值型自动转为metric值)
- 一键format(对key和value进行数据规范)
**2.2.3. 示例**
输入数据
request_time: 1614739608
upstream_response_time: 123456789
slbid: 123
scheme: worker
正常转化
log-to-metric -names=["request_time", "upstream_response_time"] -labels=["slbid","scheme"]
规范数据
log-to-metric -names=["request_time", "upstream_response_time"] -labels=["slbid","scheme"] -format
模糊匹配
log-to-metric -wildcard -names=["request*", "upstream*"] -labels=["slbid","scheme"]
输出数据
__labels__:slbid#$#123|schema#$#worker
__name__:max_rt
__time_nano__:1614739608
__value__:123
__labels__:slbid#$#123|schema#$#worker
__name__:total_qps
__time_nano__:1614739608
__value__:10
**2.3. metric-to-metric**
**2.3.1. 场景与问题**
时序数据的来源可能来自于不同端,可能是ilogtail、openTelemetry亦或者是其他SDK,在数据采集的过程中,不可避免的会出现脏数据的情况,影响Metric时序数据库的查询能力,出现查询不准确或者查询失败的情景。新增metric-to-metric算子可以对已有时序数据进行二次加工,支持添加、删除和修改标签,同时直击数据结构问题,统一提供修复能力。
**2.3.2. 创新功能**
对已有时序数据进一步加工(如添加/修改/删除标签),并提供了一键format非法数据的能力。
**2.3.3. 示例**
输入数据
__labels__:host#$#myhost|qps#$#10|asda$cc#$#j|ob|schema#$#|#$#|#$#xxxx
__name__:rt
__time_nano__:1614739608
__value__:123
SPL语句
*|metric-to-metric -format
输出数据
__labels__:asda_cc#$#j|host#$#myhost|qps#$#10
__name__:rt
__time_nano__:1614739608
__value__:123
输入数据
__labels__:host#$#myhost|qps#$#10
__name__:rt
__time_nano__:1614739608
__value__:123
SPL语句
* | metric-to-metric -del_labels='["qps"]'
输出数据
__labels__:host#$#myhost
__name__:rt
__time_nano__:1614739608
__value__:123
**极致性能**
在 SPL 新算子的开发过程中,性能优化是核心主题之一。与旧版 DSL 不同,新版 SPL 算子的设计更加注重极致性能,结合底层算法调优和高效 C++ 实现,全面提升了数据处理能力和吞吐量。
**3.1. 性能对比实验说明**
由于旧版加工与新版 SPL 加工在工程实现上存在较大差异(如内存中的数据格式不一致),直接对比两者的性能存在一定挑战。为确保测试结果的公平性,我们采取了以下措施:
- 数据模拟:通过 mock 生成一批内存大小相近的数据集,尽量保证输入数据的一致性。
- 端到端测试:针对关键模块(如log-to-metric和pack-fields)进行端到端性能测试,覆盖从输入到输出的全流程。
**3.2. 关键性能指标对比**
| 指标 | log-to-metric (旧版) | log-to-metric (新版) | 改进倍数 | pack-fields (旧版) | pack-fields (新版) | 改进倍数 |
|---|---|---|---|---|---|---|
| 总耗时 (秒) | 9.1072 | 1.27 | 7.17x | 72.2334 | 1.94 | 37.23x |
| 总速度 (MB/s) | 29.65 | 115.43 | 3.90x | 3.74 | 75.26 | 20.12x |
| 处理速度 (MB/s) | 29.65 | 824.47 | 27.8x | 3.74 | 192.70 | 51.52x |
| 数据输入耗时 (秒) | 5.1681 | 1.55 | 3.33x | 5.1045 | 2.42 | 2.11x |
| 数据处理耗时 (秒) | 3.9348 | 0.29 | 13.57x | 67.1083 | 1.89 | 35.50x |
| 数据输出耗时 (秒) | 0.0043 | 0.17 | 0.00025x | 0.0207 | 0.43 | 0.048x |
| Metric | log-to-metric (Old) | log-to-metric (New) | Improvement Factor | pack-fields (Old) | pack-fields (New) | Improvement Factor |
|---|---|---|---|---|---|---|
| Total Time (seconds) | 9.1072 | 1.27 | 7.17x | 72.2334 | 1.94 | 37.23x |
| Total Speed (MB/s) | 29.65 | 115.43 | 3.90x | 3.74 | 75.26 | 20.12x |
| Processing Speed (MB/s) | 29.65 | 824.47 | 27.8x | 3.74 | 192.70 | 51.52x |
| Data Input Time (seconds) | 5.1681 | 1.55 | 3.33x | 5.1045 | 2.42 | 2.11x |
| Data Processing Time (seconds) | 3.9348 | 0.29 | 13.57x | 67.1083 | 1.89 | 35.50x |
| Data Output Time (seconds) | 0.0043 | 0.17 | 0.00025x | 0.0207 | 0.43 | 0.048x |
| Metrics | log-to-metric (old version) | log-to-metric (new version) | Improvement multiple | pack-fields (old version) | pack-fields (new version) | Improvement multiple |
|---|---|---|---|---|---|---|
| Total elapsed time (seconds) | 9.1072 | 1.27 | 7.17x | 72.2334 | 1.94 | 37.23x |
| Total speed (MB/s) | 29.65 | 115.43 | 3.90x | 3.74 | 75.26 | 20.12x |
| Processing speed (MB/s) | 29.65 | 824.47 | 27.8x | 3.74 | 192.70 | 51.52x |
| Data input time (seconds) | 5.1681 | 1.55 | 3.33x | 5.1045 | 2.42 | 2.11x |
| Data processing time (seconds) | 3.9348 | 0.29 | 13.57x | 67.1083 | 1.89 | 35.50x |
| Data output time (SEC) | 0.0043 | 0.17 | 0.00025x | 0.0207 | 0.43 | 0.048x |
| Metrics | log-to-metric (old version) | log-to-metric (new version) | Improvement multiple | pack-fields (old version) | pack-fields (new version) | Improvement multiple |
|---|---|---|---|---|---|---|
| Total elapsed time (seconds) | 9.1072 | 1.27 | 7.17x | 72.2334 | 1.94 | 37.23x |
| Total speed (MB/s) | 29.65 | 115.43 | 3.90x | 3.74 | 75.26 | 20.12x |
| Processing speed (MB/s) | 29.65 | 824.47 | 27.8x | 3.74 | 192.70 | 51.52x |
| Data input time (seconds) | 5.1681 | 1.55 | 3.33x | 5.1045 | 2.42 | 2.11x |
| Data processing time (seconds) | 3.9348 | 0.29 | 13.57x | 67.1083 | 1.89 | 35.50x |
| Data output time (SEC) | 0.0043 | 0.17 | 0.00025x | 0.0207 | 0.43 | 0.048x |
**3.3. 结论**
新版的加工能力针对log-to-metric和pack-fields两种模块进行了全面的性能优化。从测试结果可以得出以下结论:
- 端到端性能显著提升:新版框架优化了输入、处理和输出的全流程,尤其是数据处理阶段的性能优化显著。log-to-metric模块性能整体提升 7.17 倍,而pack-fields模块提升更为显著,达到 37.23 倍。
- 处理速度的突破:两种模块的处理速度分别提升了27.8 倍 和 51.52 倍,解决了旧版中处理阶段效率不足的问题。
新版在工程实现上的优化方向非常明确且效果显著,通过性能改进全面解决了旧版的瓶颈问题,为数据加工任务提供了更强的处理能力和更高的吞吐量。
结语
此次 SPL 加工能力的迭代更新,以“性能提升”、“场景支持多样化”和“易用性优化”为核心目标,在以下几个方面取得了显著突破:
- 极致性能与稳定性:基于灵活的加工框架、先进的编码模式及 C++ 实现的存储与计算引擎,新算子在资源复用与性能优化方面全面领先,尤其在高负载或复杂数据场景下,仍能保持稳定的写入与读取性能。新版加工算子性能较旧版普遍提升 10 倍以上,为处理海量数据和加速分析效率提供了坚实保障。
- 使用体验升级:SPL 采用类 SQL 的语法设计,支持多级管道化操作的灵活组合,显著降低用户的使用门槛。新增的一键格式化、字段通配符匹配等功能,大幅简化了复杂加工任务的操作步骤,为用户带来更加便捷高效的开发体验。
- 业务可观测性与扩展能力:完美支持从日志到指标的链路打通,帮助用户构建端到端的可观测体系。满足日志聚合、时序预测及异常检测等多种场景需求,为业务的日志分析、可观测性打造了一体化解决方案。
SPL 算子不仅完成了旧版 DSL 加工向更强大语法和算子形式的过渡,更将性能调优和场景适配做到了极致,解锁了时序预测和日志分析的更多可能性。作为重要的基础设施模块,SPL 加工能力将持续优化演进。未来的规划将继续聚焦通用性、性能与产品能力,为用户提供更加强大、灵活的技术支持。