**从“天书”到源码:HarmonyOS NEXT 崩溃堆栈解析实战指南**
**背景介绍**
随着原生鸿蒙操作系统(HarmonyOS Next)的正式发布,华为全面转向全栈自研的纯鸿蒙架构,彻底去除对Android开源项目(AOSP)的依赖,构建了统一内核与运行时环境,以 ArkTS 作为主要开发语言,并基于方舟编译器(Ark Compiler)和分布式架构打造智能生态。这一技术演进在提升系统性能与安全性的同时,对应用稳定性监控提出全新挑战。
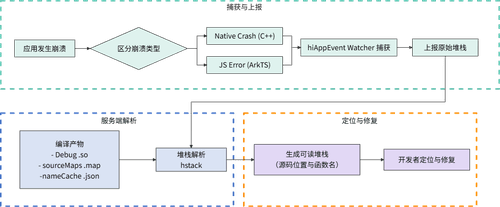
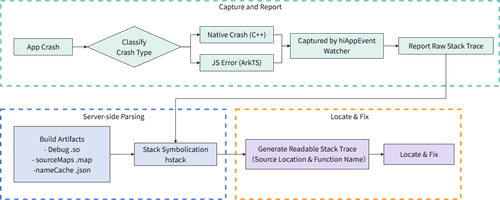
本文将深入剖析 HarmonyOS Next 的异常处理机制,结合工程实践,系统性介绍从崩溃捕获、上下文采集分析、符号化还原的全链路解决方案,助力开发者构建高可用、易维护的鸿蒙原生应用。针对 HarmonyOS 的应用开发场景,系统级崩溃事件可分为两个技术层级进行分类和处理:
- Native 层崩溃(NativeCrash)
当应用程序调用 C/C++ 编写的底层原生代码时,若未正确处理以下系统信号:SIGSEGV(非法内存访问),SIGABRT(主动异常终止),SIGFPE(浮点运算错误),SIGILL(非法指令),SIGBUS(总线错误)等。系统将自动生成 NativeCrash 事件。此类崩溃通常涉及内存管理问题(如空指针解引用、数组越界)、资源竞争条件或硬件异常,需要通过核心转储(Core Dump)分析和调试符号映射进行根因定位。 - JavaScript/ArkTS 层崩溃(JsError)
在应用逻辑层使用 JavaScript 或 ArkTS 开发时,若未捕获以下运行时异常:未定义变量访问(ReferenceError),类型转换错误(TypeError),语法错误(SyntaxError),异常断言失败(AssertionError)等。系统会记录 JsError 事件。这类错误可通过浏览器开发者工具(DevTools)的控制台日志、Promise 链错误传播追踪及 try/catch 块捕获进行调试。
通过建立完整的崩溃监控-分析-修复闭环,可有效提升应用稳定性指标,降低用户流失率。本文主要讲解从埋点监控到分析异常的完整链路的具体方案与原理。
**模拟异常**
场景1: 首先我们模拟一个 CPP 类型的崩溃。UI 界面构造一个按钮,点击触发 CPP 崩溃。
ItemButton({ btnName: "CPP_CRASH", fonSize: 12 })
.width('30%')
.onClick(() => {
libentry.createCppCrash()
})
CPP 崩溃构造如下
// 构造 CPP CRASH
static napi_value CreateCppCrash(napi_env env, napi_callback_info info) {
throw std::runtime_error("This is a CPP CRASH");
}
点击触发 CPP 崩溃之后,APP 崩溃。在 DevEco Studio 的 FaultLog 中可以获取到异常堆栈。
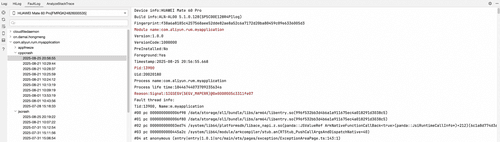
场景2:模拟一个 JsError 崩溃。UI 界面构造一个按钮,点击触发 JS Crash。
// 创建异常
ItemButton({ btnName: "JS_CRASH", fonSize: 12 })
.width('30%')
.onClick(() => {
throw new Error('发生了一个错误');
})
同样地,在 DevEco Studio 的 FaultLog 中可以获取到异常堆栈。
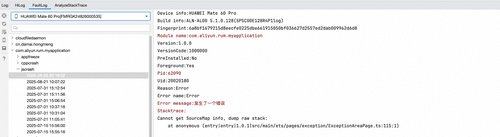
对于开发者来说,发布到线上的应用,在应用发生崩溃的时候,将崩溃的细节以及堆栈数据上报,并且进行有效堆栈解析至关重要,接下来文章即将介绍一种较为有效的异常分析实践方案。
**基于 hiAppEvent 埋点监控方案**
基于 hiAppEvent 系统能力,可以进行异常识别与采集。
- 首先尽早注册 Watcher,在应用的启动逻辑中(例如 EntryAbility.ets 的 onCreate 方法里),第一时间添加 Watcher,确保能捕获到所有类型的崩溃。
- 核心逻辑在 onReceive 回调:这是我们处理和上报崩溃数据的入口。当应用崩溃(或在下次启动时),系统会调用这个函数,并将所有崩溃信息作为参数传入。
import { hiAppEvent, hilog } from '@kit.PerformanceAnalysisKit';
// ...
let watcher: hiAppEvent.Watcher = {
name: "MyCrashWatcher",
appEventFilters: [ /* ... */ ],
onReceive: (domain: string, appEventGroups: Array<hiAppEvent.AppEventGroup>) => {
hilog.info(0x0000, 'MyCrashReporter', 'Crash event received!');
for (const eventGroup of appEventGroups) {
for (const eventInfo of eventGroup.appEventInfos) {
const crashReport = {
time: eventInfo.params['time'],
crash_type: eventInfo.params['crash_type'],
// ... 其他元数据
};
const logFilePath = eventInfo.params['external_log'] ? eventInfo.params['external_log'][0] : null;
uploadCrashReport(crashReport, logFilePath);
}
}
}
};
hiAppEvent.addWatcher(watcher);
- 实现 uploadCrashReport 函数:这个函数是你的自定义实现,它需要做两件事:
- 将 crashReport 这个 JSON 对象上报到你的服务器。
- 如果 logFilePath 存在(通常在 Native Crash 时),读取该路径下的日志文件内容,并将其作为文件流或文本内容,一并上报到服务器。
**获取编译产物,辅助异常解析**
进行鸿蒙端的异常解析需要传入必要的构建产物文件,分别为 ArkTS 调试产物 sourcemap,C++ 调试产物 debug so 文件,代码混淆产物 nameCache。与 iOS 和 Android 系统的符号表概念类似,这些编译产物存储了源代码中的变量、函数、类等符号及其相关信息,是内存地址与函数名、文件名、行号的映射表。
在还原异常堆栈的过程中,这些包含符号映射关系的编译产物是不可或缺的重要输入。在鸿蒙系统中,三种编译产物的获取方式分别如下:
- ArkTS 调试产物 souceMap 文件:release 模式编译产物,产物位置:{ProjectPath}/{ModuleName}/build/{product}/cache/default/default@CompileArkTS/esmodule/release/sourceMaps.map
- C++ 调试产物 so 文件:
- 在 release 编译时,需要保留 so 文件中的符号表、调试信息,需要在 build-profile.json5 的 buildOption/externalNativeOptions 中配置参数 "arguments": "-DCMAKE_BUILD_TYPE=RelWithDebInfo"
{
"apiType": "stageMode",
"buildOption": {
"externalNativeOptions": {
"path": "./src/main/cpp/CMakeLists.txt",
"arguments": "-DCMAKE_BUILD_TYPE=RelWithDebInfo",
"cppFlags": "",
}
},
...
}
- 带debug信息的so数据,产物位置:{ProjectPath}/{ModuleName}/build/{product}/intermediates/libs
- 代码混淆产物 nameCache 文件:反混淆映射表,release模式编译产物,产物位置:{ProjectPath}/{ModuleName}/build/{product}/cache/default/default@CompileArkTS/esmodule/release/obfuscation
其中,C++的调试产物 so 文件,可以通过 build ID 做到与异常堆栈的一一匹配。Build ID 是编译时生成的一个哈希值,唯一标识了 so 文件的一次特定构建,在解析时,需要保证 debug so 文件与当前堆栈所需要的 .so 文件是完全一致的版本,如果版本不匹配,解析出的行号和函数名将是错误的。以当前场景的编译产物与堆栈为例,可以在存放 so 文件的目录下,执行 file 命令获取当前 so 文件的 BuildID,如图所示。

刚刚我们模拟的崩溃场景下,崩溃堆栈中如图所示
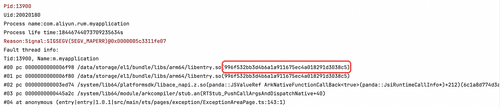
可以看到堆栈中的文件 UUID 信息和通过 shell 命令获取到的so文件的 UUID 是相对应的,代表可以进一步正确解析。
**异常堆栈解析原理浅析**
**要解析这些上报的原始堆栈,我们需要借助专业的工具。鸿蒙平台官方推荐的堆栈解析利器是 hstack,它是用于将release应用混淆后的crash堆栈解析为源码对应堆栈的工具,**支持Windows、Mac、Linux三个平台。hstack 在解析过程中,类似于一个“调度员” 的角色,底层依赖了 llvm-addr2line 和 sourceMap 以及反混淆解析。
**CPP 堆栈解析原理**
**解读堆栈**
首先观察上报来的 CPP 堆栈日志,每一行都包含了关键信息:
#00 pc 0000000000006f98 /data/storage/el1/bundle/libs/arm64/libentry.so(996f532bb3d4b6a1a911675ec4a018291d3038c5)
- #00: 堆栈帧序号。00 代表栈顶,是程序崩溃的直接位置。
- pc 0000000000006f98: 程序计数器地址 (Program Counter)。这是我们需要解析的关键信息,代表 CPU 在 libentry.so 这个库中执行到的指令的相对地址。
- /data/storage/el1/bundle/libs/arm64/libentry.so: 动态库路径。指明了崩溃发生在哪一个 .so 文件中。这是设备上运行时的路径。
- (996f532bb3d4b6a1a911675ec4a018291d3038c5): Build ID。正如前文提到的,这个 Build ID 用于与.so 文件一一匹配。
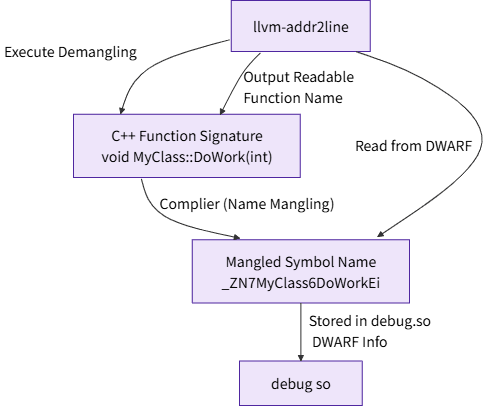
**llvm-addr2line 原理**
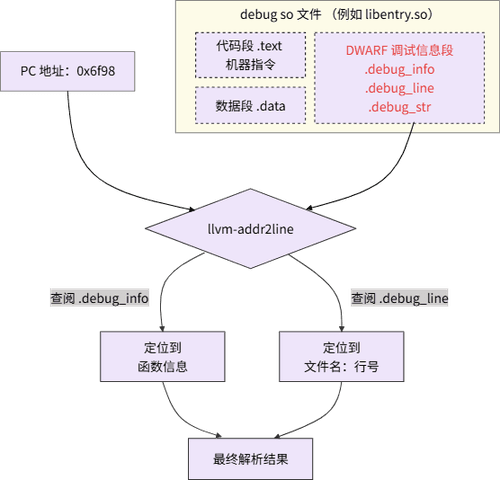
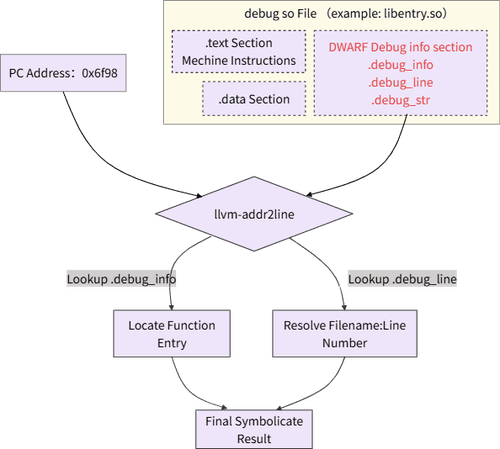
llvm-addr2line 是业内主流的 C++ 堆栈解析工具之一。现在我们深入 llvm-addr2line 内部,它的工作原理在鸿蒙场景下完全适用,核心依赖于编译产物 debug so 文件中包含的两样东西。
- DWARF 调试信息 (地址到源码的地图)
在 release 模式下打包的编译产物,通常为了减小体积而剥离掉调试信息,这时内部会缺少 DWARF 部分,llvm-addr2line 也就无法工作,hstack 解析会失败,所以前文提到,解析前需要开启调试信息选项,编译器就会生成一份详细的“地图”—— DWARF 信息,并将其打包进 debug so 文件中。
DWARF 信息中包含了:
- 每一条机器指令地址(如 0x6f98)对应的是哪个源文件 (.cpp) 的哪一行代码。
- 该地址属于哪个函数,函数的参数是什么。
- 复杂的内联函数调用关系等。
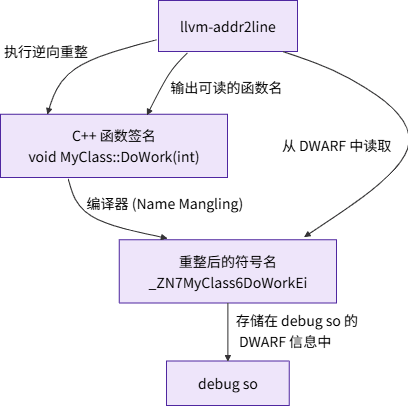
- C++ 符号逆向重整(Demangling)
为了支持函数重载等 C++ 特性,编译器会把我们写的函数名(如 OH_NativeXComponent_RegisterCallback)转换成一个唯一的、但不可读的符号名(如 _Z35OH_NativeXComponent_RegisterCallbackP18OH_NativeXComponentP29OH_NativeXComponent_Callback)。这个过程叫名称重整 (Name Mangling)。llvm-addr2line 在 DWARF 信息中找到的就是这个重整后的符号名。为了方便开发者阅读,它会执行一个逆向过程——逆向重整 (Demangling),将其还原为原始的 C++ 函数签名。
**Sourcemap 解析原理**
针对 ArkTS 语言发生的崩溃,Sourcemap 文件将难以阅读的机器码或字节码映射回开发者编写的、刻度的代码位置。sourceMap.map 文件是一个聚合式的 JSON 文件。我们来逐层拆解它的工作原理。
**文件 key**
当编译器处理 ArkTS 文件时,它会在最终生成的 .abc 字节码文件中,为这个源文件嵌入一个唯一的字符串标识符,这就是 Key,在 sourceMaps.map 文件中,用这个完全相同的 key 作为主键,存储与之对应的所有映射信息。当运行时发生异常,堆栈信息会直接抛出这个 key。解析工具拿到这个 key 后,就可以像查字典一样,在庞大的 sourceMaps.map 文件中,O(1) 复杂度内精确地找到对应的映射数据块,而无需遍历。
详细解读 key 的结构:entry|har1|1.0.0|src/main/ets/pages/w.ts
entry: 当前模块的名称 (来自 oh-package.json5 的 name)。
har1|1.0.0: 依赖包的名称和版本。这部分至关重要,它解决了依赖冲突和版本管理问题。即使你依赖了两个不同版本的同名 har 包,通过这个 key 也能精确区分崩溃发生在哪个版本的代码中。如果代码不属于依赖,这里会是模块自身的 name 和 version。
src/main/ets/pages/w.ts: 源码在工程中的相对路径。
**mappings 字符串**
mappings 字段是 Sourcemap V3 规范的核心。它是一长串看起来像乱码的字符串,例如如 "AAAA,IAAM,CAAC..."。它并不是乱码,而是使用一种叫 VLQ (Variable-length quantity) 的编码方式,对位置信息进行了极致的压缩。解析器会按特定规则解码这个字符串,从而得到一个从转换后代码(字节码)的行列号到源代码的行列号的完整映射表。
它的工作方式是“增量”记录:第一个映射点记录绝对位置。从第二个映射点开始,只记录与前一个点的差值。例如,如果两个映射点在源码中只隔了几列,那么 VLQ 编码可能只需要一两个字符就能表示这个“微小的变化”,极大地压缩了文件体积。

**sources 和 names**
sources: 这是一个数组,包含了该模块所有相关的源文件名列表。mappings 解码出的映射关系,会通过一个索引指向这个数组,从而知道对应的源文件是哪一个。
names: 这是一个数组,包含了代码中用到的变量名和属性名。如果代码经过了混淆(例如变量 myLongVariableName 被混淆成了 a),mappings 在记录位置的同时,也会记录一个指向 names 数组的索引。解析时,就可以通过这个索引找回原始的变量名 myLongVariableName。
**关联 nameCache 反混淆资源**
在大型项目中,代码混淆是常见的操作。混淆工具会生成一个 nameCache 文件,记录了混淆前后的变量名、函数名、属性名的对应关系。当 Sourcemap 解析需要还原被混淆的名称时,它需要知道当前解析的模块版本和其依赖的版本,以便找到正确版本的 nameCache 文件。
entry-package-info 字段和 package-info 字段的主要作用是关联反混淆的 nameCache 资源。在还原变量名时,解析器会利用 entry-package-info 和 package-info 字段,确保加载了正确版本的 nameCache 文件,实现精准反混淆。
**nameCache 反混淆解析原理**
我们可以将反混淆解析视为 Sourcemap 解析之后的第二阶段精加工。Sourcemap 解决了“在哪里”的问题(文件名和行号),而反混淆则解决了“是什么”的问题(函数和变量名)。
nameCache.json 是一个以原始文件路径作为主键的 JSON 对象。解析器在经过 Sourcemap 还原得到原始文件名后,就可以用这个文件名作为 key,直接找到对应的混淆信息。
nameCache.json 内部主要包含以下几种“密码本”:
IdentifierCache(标识符缓存):记录普通变量和部分函数名的混淆关系。
MemberMethodCache(成员方法缓存):专门记录类(Class)的成员方法的混淆关系。
PropertyCache(属性缓存):记录全局属性名的混淆关系。当开启属性混淆时,像 this.userName 这样的访问,userName 可能会被全局替换成一个更短的名字。
obfName(混淆文件名):记录原始文件名与混淆后文件名的映射。虽然 Sourcemap 也能处理文件名映射,但这里提供了一个更直接的查询方式。
entryPackageInfo(入口包信息):版本校验。确保当前使用的 nameCache.json 文件与发生崩溃的代码版本完全匹配。这是在自动化和持续集成环境中保证解析准确性的生命线。
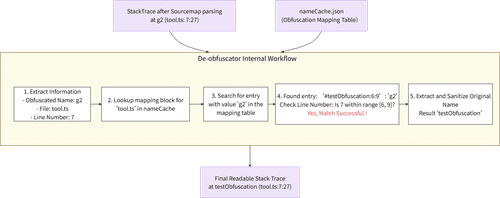
整体反混淆的过程如下:
**小结**
至此,我们完整地描绘了鸿蒙平台上从最底层的 Native 异常到最上层的 ArkTS 异常的全链路解析原理:
- Native 层 (C++):当崩溃发生在 .so 文件中,hstack 调用 llvm-addr2line,利用 debug so 中的 DWARF 信息,将机器指令地址(如 0x6f98)解析成 C++ 的文件名、行号和函数签名。
- ArkTS 层 (定位):当异常发生在 ArkTS 代码中,解析工具首先使用 sourceMaps.map 文件。通过堆栈中的唯一 key 定位到映射块,再解码 mappings 字符串,将 .abc 字节码的行列号还原为 ArkTS 源码的文件名和行列号。
- ArkTS 层 (命名):最后,解析工具加载 nameCache.json 反混淆文件。利用上一步得到的原始文件名和行号,在 IdentifierCache 等映射表中进行搜索和范围匹配,将混淆后的名称(如 g2)还原为开发者编写的、有意义的函数、变量或属性名。
**全文总结**
本文介绍了HarmonyOS应用崩溃监控方案:系统崩溃分为Native层(C/C++信号异常)和JS/ArkTS层(运行时异常)两类,通过hiAppEvent埋点实现监控。开发中可通过模拟按钮触发两种崩溃,利用DevEco Studio获取堆栈信息。监控方案核心是在应用启动时注册Watcher,通过onReceive回调采集崩溃类型、时间等关键数据,建立崩溃上报与分析闭环,最终实现应用稳定性提升和用户流失率降低。**搭建并维护这样一套完整的监控解析体系需要投入不少工程资源。对于希望开箱即用、聚焦业务开发的团队而言,市面上也已出现成熟的解决方案。例如,**阿里云 ARMS 用户体验监控鸿蒙 SDK,实现了无侵入式异常数据的采集、上报与解析,通过会话轨迹、页面关联,可以追踪异常发生的上下文,从而更快速地还原问题现场,定位具体发生异常的代码位置。可以参考接入文档体验使用。相关问题可以加入“RUM 用户体验监控支持群”(钉钉群号: 67370002064)进行咨询。
参考资料: