**背景**
在数字化转型加速的今天,日志数据已成为企业运维、安全分析和业务决策的核心资产。然而,随着云计算、容器化和微服务架构的普及,传统日志采集 Agent 面临着前所未有的挑战:海量日志的实时采集需求、资源占用与成本控制的平衡难题。
iLogtail 作为阿里巴巴自主研发的高性能日志 Agent,凭借其稳定的性能和丰富的功能,长期服务于阿里云数百万用户,成为企业级日志管理系统的基石。它以低延迟、高吞吐和轻量级资源占用著称,尤其在大规模集群环境中表现卓越。然而,随着技术演进和用户需求升级,日志采集场景的复杂性与性能要求进一步提升,对工具的极致性能、灵活性和智能化提出了更高要求。
正是在这种背景下,LoongCollector 应运而生。作为 iLogtail 的下一代演进产品,它不仅继承了 iLogtail 的稳定性和可靠性,更通过全栈架构优化实现了性能的跨越式提升。
为了展现 LoongCollector 的卓越性能,本文通过纵向(LoongCollector 与 iLogtail 产品升级对比)和横向(LoongCollector 与其他开源日志采集 Agent 对比)两方面对比,深度测评不同采集 Agent 在常见的日志采集场景下的性能。
参与本次的横评的日志采集器如下,版本均采用本文撰写时的最新版本:
| 日志采集 Agent | 版本 | 仓库地址 |
|---|---|---|
| LoongCollector | 3.0.10 | |
| iLogtail | 2.1.7 | |
| FluentBit | 4.0.0 | |
| Vector | 0.45.0 | |
| Filebeat | 8.17.4 |

**纵向对比——LoongCollector 自我升级,超越巅峰 80%**
iLogtail 已经具备相当强的日志采集能力,而作为 iLogtail 的升级演进产品,LoongCollector 则不能逊色。我们首先对比一下 LoongCollector 与 iLogtail 的极限性能。
基于真实业务场景,我们设计了五种典型日志采集与解析场景(包括单行、多行、正则解析、Json 解析和分隔符解析),并在同等硬件环境下,实测对比两者的极限吞吐量表现。
**环境**
机器配置:阿里云 ECS 32C64G
操作系统:Ubuntu 22.02
网络:VPC 内网
**不同解析场景下的数据源**
注意:日志长度对性能测试的绝对数值影响很大,因此我们选取了两种不同长度的日志进行测试。
极简单行日志:长度为 128B
多行日志:长度为 512B,行首匹配长度为 1,每组多行日志包含了 23 行
复杂正则日志:长度为 534B,日志内容模拟真实的 Nginx 日志
203.0.113.45 - - [25/Jun/2024:23:59:59 +0000] "GET /wp-admin/admin-ajax.php?action=revslider_ajax_action&client_action=get_facebook HTTP/1.1" 200 1847 "https://www.google.com/search?q=free+piano+sheet+music+pdf+download+site%3Aexample.com&ref=lnms&sa=X&biw=1920&bih=1080" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)" rt=0.312 uct="0.001" uht="0.125" urt="0.311" sid=a1b2c3d4e5f6g7h8i9j0k1l2m3n4o5p6q7r8s9t0 uagent_hash=7d8f9a0b1c2d3e4f5a6b7c8d9e0f1a2b3c4d5e6f7 request_id=req-20240625-235959-001
正则表达式
^([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+[([^]]+)]\s+"([A-Z]+)\s+([^ ]+)\s+(HTTP/[0-9.]+)"\s+([0-9]{3})\s+([0-9-]+)\s+"([^"]*)"\s+"([^"]*)"\s+rt=([0-9.]+)\s+uct="([0-9.-]+)"\s+uht="([0-9.-]+)"\s+urt="([0-9.-]+)"\s+sid=(\S+)\s+uagent_hash=(\S+)\s+request_id=(\S+)
复杂 Json 日志:长度为 512B
{
"time":"2025-04-03 10:02:06.561793",
"level":"info",
"thread":"131172",
"file":"/root/server_stdout.go",
"line":"165",
"msg":"ZQsC8JI2l9M6Zum1b09V8QZy7MBk8fI01kmg12XqfHXWxdD4SBYUdGKRH4iRCcjIVIOAXmv8I0TgQlJKtwYxAhJR9O2N1BEirA1v01IqWyGaVsxCxRjCpvhkWQ03wW3CnKUCLCndugLfWYsxiYMJs7YiqYhOlCglTj4XdUQqlOfZTrYdyFNX3fVQk9jwBAO5NEBUAo0VgL7rt86lENPr5wA1UQWNdj2id00ByhsBakCjyRP9tvxDVrTSEq5oEVowKYBYzcjJCK1q56MVDm1BhSfNGrLQifr3nYv5Z8yu1d8EAjK9iQGjVqLxz65IozXKyf40R2TZYR9TS2GAMxMyC7uIvZiMh0TRB4rQL4K4uFeOVkFMGrHG3a3"
}
复杂分隔符日志:长度为 512B
2025-04-03 10:02:06.561793|info|131172|/root/server_stdout.go|165|ZQsC8JI2l9M6Zum1b09V8QZy7MBk8fI01kmg12XqfHXWxdD4SBYUdGKRH4iRCcjIVIOAXmv8I0TgQlJKtwYxAhJR9O2N1BEirA1v01IqWyGaVsxCxRjCpvhkWQ03wW3CnKUCLCndugLfWYsxiYMJs7YiqYhOlCglTj4XdUQqlOfZTrYdyFNX3fVQk9jwBAO5NEBUAo0VgL7rt86lENPr5wA1UQWNdj2id00ByhsBakCjyRP9tvxDVrTSEq5oEVowKYBYzcjJCK1q56MVDm1BhSfNGrLQifr3nYv5Z8yu1d8EAjK9iQGjVqLxz65IozXKyf40R2TZYR9TS2GAMxMyC7uIvZiMh0TRB4rQL4K4uFeOVkFMGrHG3a3
**测试流程**
- 添加采集配置,采集日志文件到 SLS logstore 中(同地域,通过内网传输,避免网络导致的性能瓶颈)
- 启动日志生成进程,重复向日志文件中写入数据(最高写入流量 1100MB/s)
- SLS logstore 查询统计流量
- 计算采集一分钟之后的流量均值
除此之外,我们还对比了 LoongCollector 和 iLogtail 在不同日志量级下进行极简单行日志采集时的资源占用情况,测试流程如下:
- 添加采集配置,采集日志文件到 SLS logstore 中
- 调整不同的日志的生成速率,启动日志生成进程,重复向日志文件中写入数据
- SLS logstore 查询统计流量
- 稳定采集一分钟之后,计算两分钟内的 CPU 和内存使用均值
**测试结果**
**极限性能**
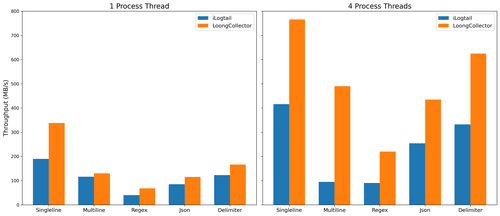
| LoongCollector | iLogtail | |||
|---|---|---|---|---|
| 处理线程数 | 1 | 4 | 1 | 4 |
| 单行 | 338MB/s +78% | 766MB/s +84% | 190MB/s | 416MB/s |
| 多行 | 130MB/s +12% | 490MB/s +416% | 116MB/s | 95MB/s |
| 正则解析 | 68MB/s +70% | 220MB/s +144% | 40MB/s | 90MB/s |
| Json 解析 | 115MB/s +35% | 435MB/s +71% | 85MB/s | 254MB/s |
| 分隔符解析 | 166MB/s +35% | 625MB/s +88% | 123MB/s | 332MB/s |
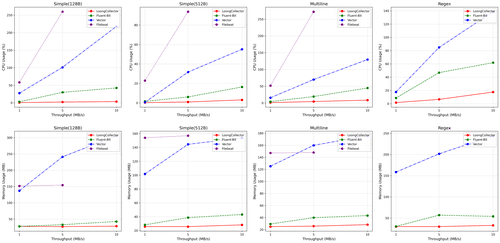
从表一中我们可以看到,LoongCollector 在五个常见的日志采集场景下的极致吞吐量都远远高于 iLogtail。尤其是在多线程的情况下,iLogtail 的性能随着处理线程数的增加,所带来的收益逐渐减少。而 LoongCollector 通过一系列优化,减少了多线程进行处理时的锁竞争问题,使得 LoongCollector 能够突破更高的吞吐量极限。
**资源占用**
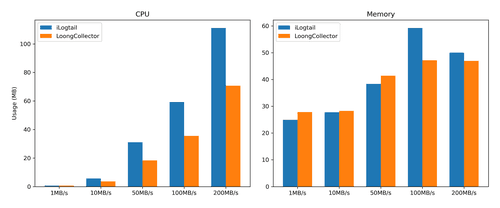
| LoongCollector (单核极限 338MB/s) | iLogtail (单核极限 190MB/s) | |||
|---|---|---|---|---|
| 流量 | CPU | 内存 | CPU | 内存 |
| 1MB/s | 0.70% -0% | 27.85 MB +12% | 0.70% | 24.93 MB |
| 10MB/s | 3.65% -35% | 28.28 MB +2% | 5.65% | 27.74 MB |
| 50MB/s | 18.34% -41% | 41.42 MB +8% | 31.04% | 38.35 MB |
| 100MB/s | 35.48% -43% | 47.18 MB -20% | 59.28% | 59.27 MB |
| 200MB/s | 70.72% | 46.98 MB | 111.19% 达到极限 190MB/s | 50.01 MB 达到极限 190MB/s |
| 400MB/s | 120.84% 达到极限 338MB/s | 35.13 MB 达到极限 338MB/s | 采集明显延迟 | 采集明显延迟 |
从表二中我们可以看到,LoongCollector 和 iLogtail 在不同日志量级下的变化。
在 CPU 方面,LoongCollector 通过使用更低的 CPU,却能够采集比 iLogtail 高一倍的日志流量,展现了强劲的性能优势。
在内存方面,LoongCollector 在低流量下的表现与 iLogtail 相比优势差距不大。这主要是由于 LoongCollector 内部新增一些非数据面,而与稳定性相关的功能,例如更健壮的自监控等等。但随着流量的升高,LoongCollector 的内存增长幅度远低于 iLogtail,体现了 LoongCollector 优秀的内存管理。
从趋势来看,我们可以明显发现 LoongCollector 的 CPU 使用率基本上随着流量呈线性增长,而 iLogtail 的 CPU 使用率则呈现了一定的膨胀。两者之间的差距越来越大。核心原因在于 LoongCollector 通过复用对象池、优化序列化等技术,尽可能减少了数据在 Pipeline 中的重复计算和复杂度。
**横向对比——LoongCollector 业界领先,10 倍吞吐,20%开销**
LoongCollector 与自身相比性能存在显著进步的同时,与其他开源 Agent 相比,也保持了持续的领先优势。为了验证 LoongCollector 的采集性能优势,我们选取了其他三种广泛使用的日志采集 Agent:FluentBit、Vector 和 Filebeat 进行端到端的对比。
为了对比的公平性,我们对实验进行了如下的几点设置:
- 为了验证端到端的采集性能,我们以完整的日志采集解决方案作为对比。
- 方案一:LoongCollector 采集日志到 SLS Logstore 中。
- 方案二:开源组件,其他开源采集 Agent 采集到 Kafka 中。
- 为了避免网络和存储端影响测试结果,所有 Agent 均通过 VPC 内网发送数据,存储分区数均提前扩容。
- 除了调整流控限制之外,所有 Agent 均采用默认的参数配置。
另外,测试流程与数据源与上一章相同,保证资源占用监控的公平性。
**测试结果**
**极限性能**
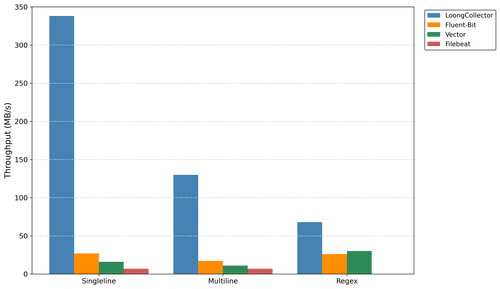
| LoongCollector | FluentBit | Vector | Filebeat | |
|---|---|---|---|---|
| 版本 | 3.0.10 | 4.0.0 | 0.45.0 | 8.17.4 |
| 单行 | 338MB/s | 27MB/s | 16MB/s | 7MB/s |
| 多行 | 130MB/s | 17MB/s | 15MB/s(默认参数使用 CPU 核数相同的处理线程) 11MB/s(公平情况下,单处理线程) | 7MB/s |
| 正则解析 | 68MB/s | 26MB/s | 74MB/s(默认参数使用 CPU 核数相同的处理线程) 30MB/s(公平情况下,单处理线程) | 不支持 |
- 性能优势:其他日志采集器,在默认配置时,性能均无法满足 50MB/s 的采集速度,与 LoongCollector 形成了显著的差距。
- 处理能力:大多数日志采集 Agent 都提供了一定的日志处理能力。但各方对于处理能力的思考有所不同。例如,Filebeat 在之前旧版本支持通过 grok 进行类似正则解析提取字段,但在新版本中移除了该插件。核心原因在于 Filebeat 在 ELK 体系中更加定位为单纯的采集器,处理能力则交给了下游的 Logstash 或者存储端。
**资源占用**
| 场景 | 流量 | LoongCollector | FluentBit | Vector | Filebeat |
|---|---|---|---|---|---|
| 极简单行 128B | 1MB/s | 0.70% 27.85 MB | 2.95% +321% 27.60 MB -1% | 27.51% +3830% 137.22 MB +393% | 58.23% +8219% 151.44 MB +444% |
| 5MB/s | 2.26% 26.91 MB | 29.95% +1225% 32.89 MB +22% | 101.28% +4381% 241.16 MB +796% | 259.82% +11396% 154.45 MB +474% | |
| 10MB/s | 3.65% 28.28 MB | 42.45% +1063% 42.69 MB +51% | 217.92% +5870% 306.00 MB +1003% | 性能不足 | |
| 极简单行 512B | 1MB/s | 0.35% 25.80 MB | 1.57% +349% 28.38 MB +10% | 0.61% +74% 101.77 MB +294% | 22.91% +6446% 153.99 MB +497% |
| 5MB/s | 0.96% 25.73 MB | 6.16% +542% 38.74 MB +51% | 31.69% +3201% 144.53 MB +462% | 93.73% +9664% 156.93 MB +510% | |
| 10MB/s | 3.13% 28.24 MB | 16.41% +424% 43.21 MB +53% | 55.12% +1661% 153.75 MB +444% | 性能不足 | |
| 极简多行 512B | 1MB/s | 1.22% 25.03 MB | 4.08% +234% 29.39 MB +17% | 15.63% +1181% 125.17 MB +400% | 51.64% +4133% 147.19 MB +488% |
| 5MB/s | 4.35% 25.82 MB | 19.19% +341% 39.89 MB +54% | 69.87% +1506% 159.85 MB +519% | 272.33% +6160% 148.03 MB +473% | |
| 10MB/s | 8.52% 28.30 MB | 44.69% +425% 43.35 MB +53% | 129.55% +1420% 175.80 MB +578% | 性能不足 | |
| 正则 512B | 1MB/s | 1.72% 29.81 MB | 8.61% +400% 30.37 MB +1.8% | 17.67% +927% 158.51 MB +431% | 不支持 |
| 5MB/s | 6.55% 29.93 MB | 46.90% +616% 56.95 MB +90% | 84.83% +1195% 201.57 MB +573% | 不支持 | |
| 10MB/s | 17.58% 32.77 MB | 61.86% +251% 53.92 MB +64% | 138.71% +689% 244.36 MB +645% | 不支持 |
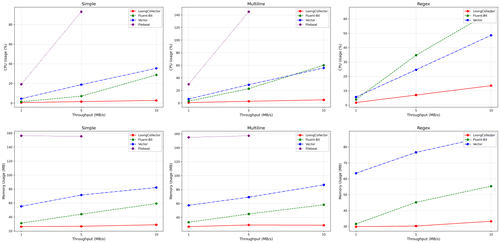
从测试结果中,我们可以看到 LoongCollector 在资源占用方面遥遥领先于其他采集 Agent,特别是随着日志流量的增大,这种领先优势更加明显。在这些结果中,我们还可以发现很多有意思的现象:
- 日志长度的影响:Vector 和 Filebeat 在采集 128B 极简单行日志时,表现反而不如多行日志。而所有 Agent 在采集 512B 的日志时性能都优于 128B,说明相同流量下,日志长度越短,数量越多,给采集带来的压力越大。但 LoongCollector 所出现的膨胀要远远低于其他采集 Agent。
- 编码限制:LoongCollector 使用 Protobuf 序列化数据发往 SLS,其余的采集 Agent 则采用了 plain 编码。从 CPU 层面来看,LoongCollector 在额外多了一次序列化的情况下,仍然能够保证明显的优势。
- 特殊情况:Vector 在进行正则解析,并发送数据至 Kafka 时,plain text 编码仅支持选取一个字段,无法表达正则解析后的多个字段。所以,在测试中使用了 JSON 编码,但导致了最终写入 Kafka 的流量膨胀了两倍。
**展望**
在日志采集领域,性能始终是衡量工具价值的核心标尺。通过与iLogtail的纵向对比,我们见证了LoongCollector在资源利用率、吞吐量和稳定性上的跨越式提升——它不仅继承了iLogtail的高效基因,更以更低的CPU占用和更高的日志处理并发能力,重新定义了日志采集的性能基准。而横向对比中,LoongCollector更以实测吞吐量超主流开源工具3倍以上的硬核数据,强势登顶日志采集性能榜单。
除此之外,LoongCollector 不仅仅一个日志采集 Agent,更是一个全面的可观测数据采集 Agent,支持 metric、trace 等多种数据类型,Prometheus、eBPF 等数据源。在这些方面,LoongCollector 相较于其他开源项目,也存在着一定的优势。
未来,LoongCollector将持续进化,以更强大的性能和更开放的生态,助力企业释放数据价值。