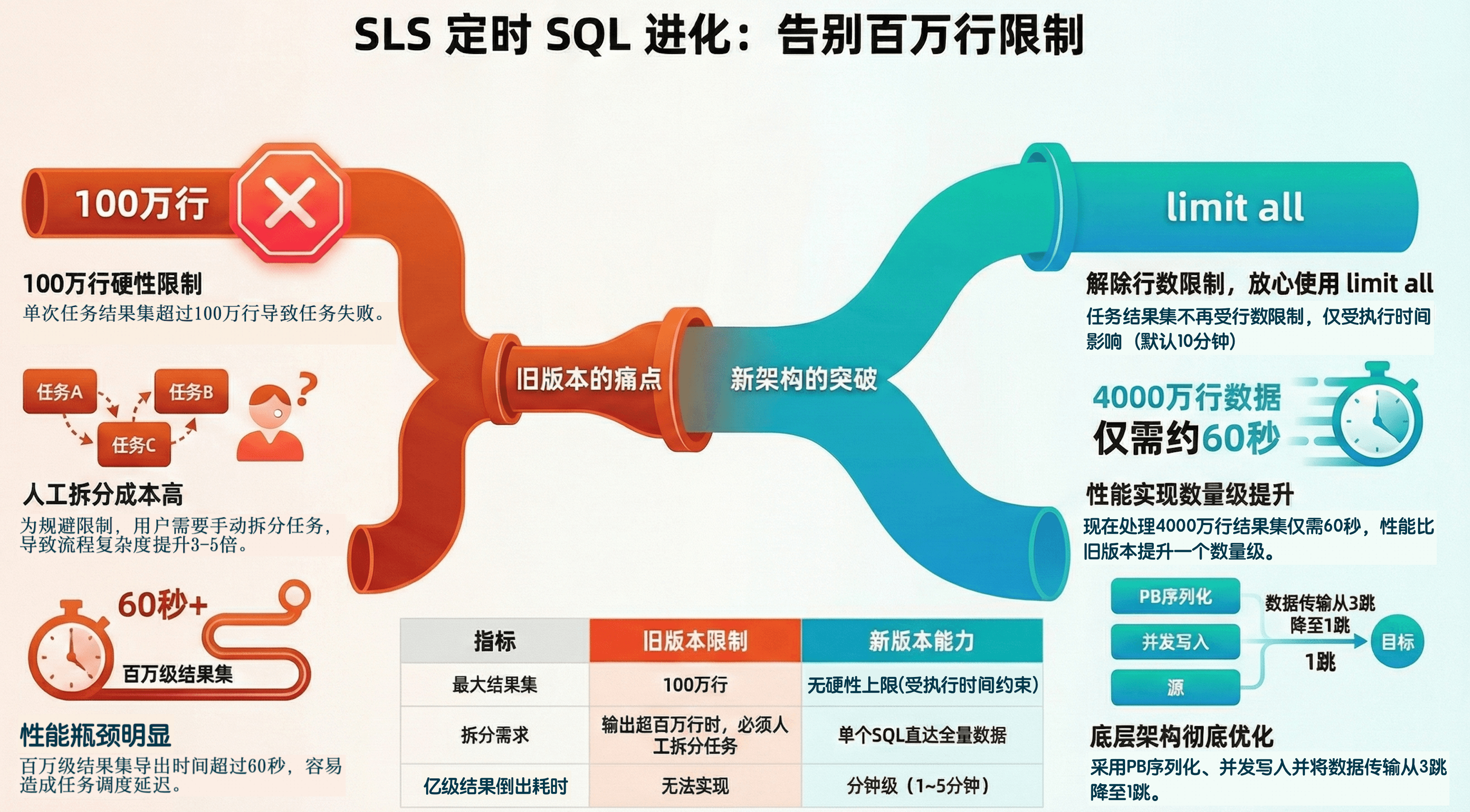
**引言**
日志服务提供定时SQL功能,用于定时分析数据、存储聚合数据、投影与过滤数据。但旧版本的定时SQL有个明显的限制,即定时SQL支持的最大输出行数为100万。对于分析和聚合降维场景,大部分情况下100万行的结果限制基本够用,但对于投影与过滤这类原始数据加工场景,则往往显得捉襟见肘了。
为了支持定时SQL支持更大数据行数的输出,SLS后端对整个定时SQL实现做了优化和重构,不仅加速了定时SQL的执行效率,还解决了100万数据量输出的限制问题。
**旧版本的痛点**
旧版本定时SQL存在一个关键的限制,即单次任务结果集不得超过100万行。这一限制对复杂分析场景造成显著影响:
- 数据完整性缺失
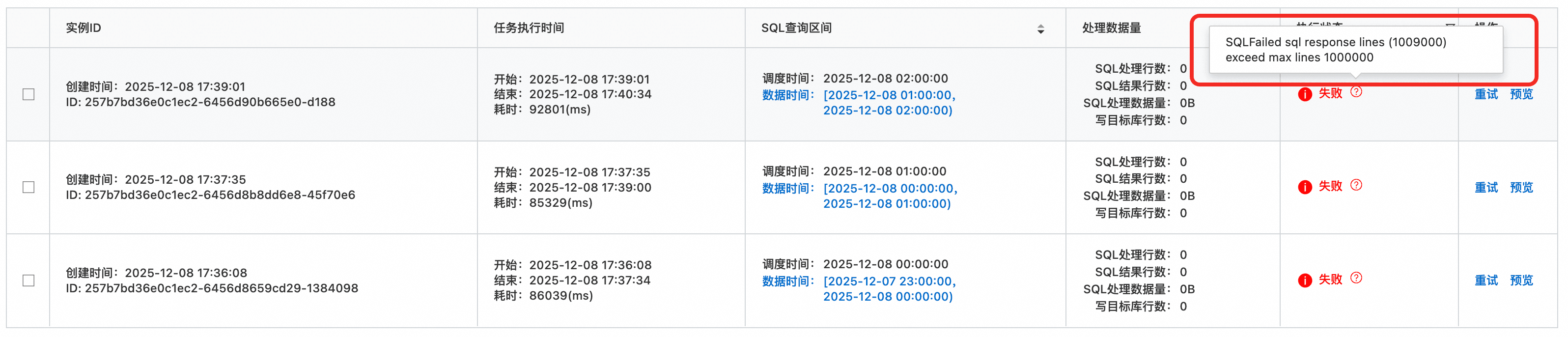
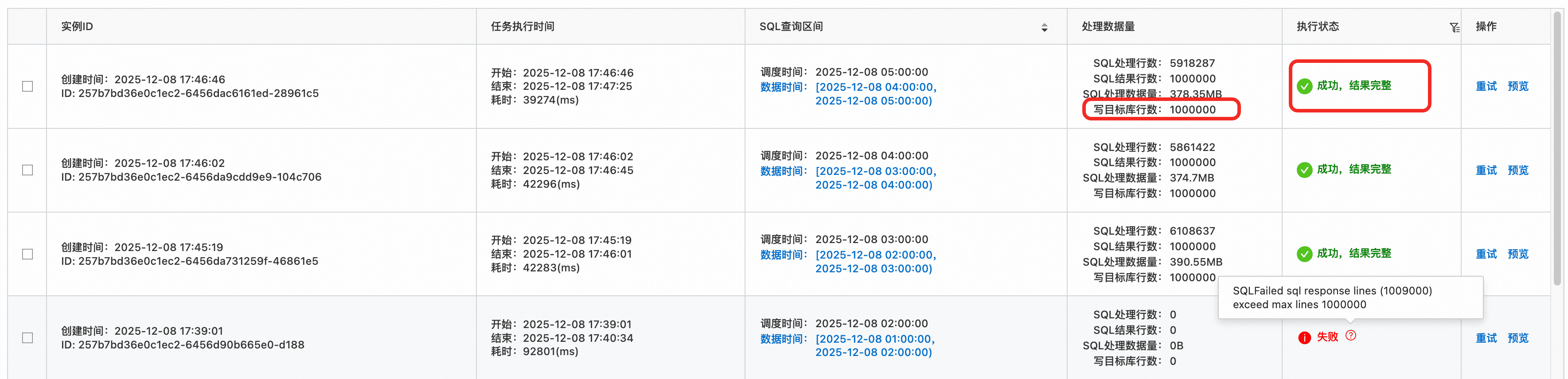
如果单次定时SQL的结果超过了100万(SQL中没有通过limit 1000000进行输出限制 而是采用了 limit all),则此次定时SQL执行将会失败。但如果SQL中显式定义了limit 1000000,则又可能导致定时SQL输出结果不完整。
比如下面的定时SQL尝试通过limit all返回完成结果,但因为输出数据行数超过了上限,导致任务失败。
select
vendor, itemId, count(*) as accessTimes
from log
group by vendor, itemId
limit all
为了绕过这个限制,他需要将SQL改为如下形式,即通过limit 1000000强制输出不超过100万:
select
vendor, itemId, count(*) as accessTimes
from log
group by vendor, itemId
limit 1000000
- 人工拆分成本高
为了规避100万行的输出限制,用户需手动拆分任务(如按照更细粒度的时间片来切分定时SQL任务),然后再按照需要的时间粒度来合并结果,导致流程复杂度提升3-5倍。
- 性能瓶颈明显
百万级结果集导出耗时超过60秒,容易导致定时SQL任务调度延迟和堆积,影响定时SQL结果的实时性。
**架构升级及效果**
SLS团队通过底层重构实现突破性提升,关键优化包括:
- 计算结果序列化时,从JSON切换为更高效的LogGroup PB(Protocol Buffers)格式
- 采用多协程并发的方式将结果写入到目标logstore
- 旧版本的定时SQL结果,在后端需要经过3跳内部节点的传输,每一跳都要经过json的序列化和反序列化。最新的实现将数据传输条数降低到一跳 且 采用压缩的PB格式进行传输。
- 取消百万行硬限制,任务结果集规模取决于执行时间(默认10分钟超时)
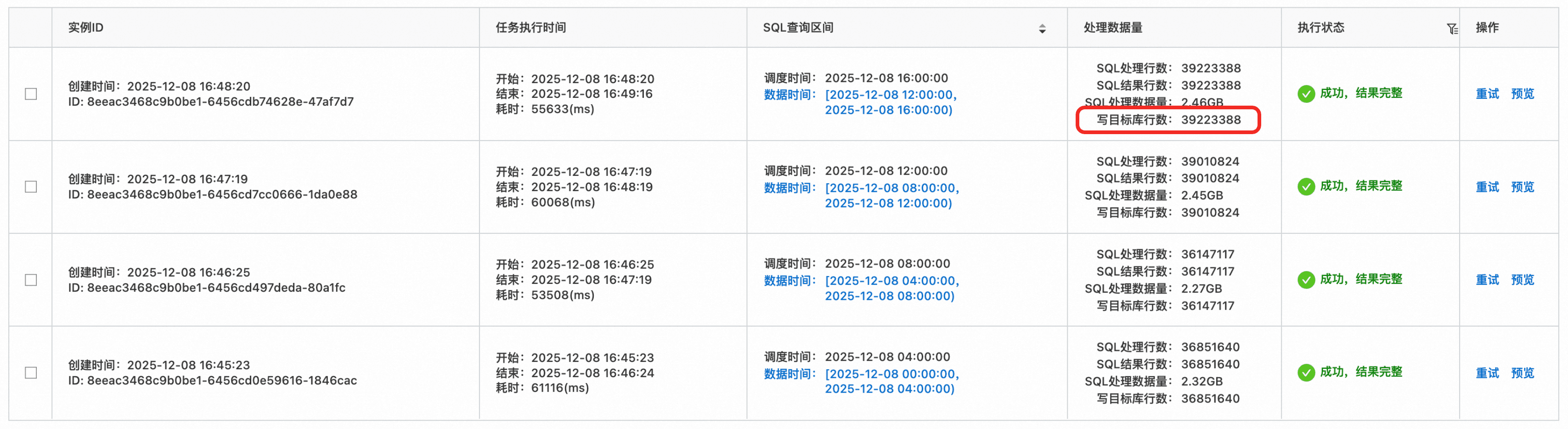
在新版本的定时SQL任务中,使用limit all不再会出现输出结果超过限制的报错。同时,和旧版本的执行结果耗时对比也可以发现,新版本的定时SQL性能也有了质的提升。之前100万结果输出需要将近40s,而现在4000万的结果输出也就60s左右,性能提升了一个数量级。
select
vendor, itemId, count(*) as accessTimes
from log
group by vendor, itemId
limit all
**新旧版本对比**
| 指标 | 旧版本限制 | 新版本能力 |
|---|---|---|
| 最大结果集 | 100万行 | 无硬性上限(受时间约束) |
| 亿级结果行导出耗时 | 不可实现(即使放开100万限制, 耗时也是小时级) | 分钟级(1~5分钟) |
| 拆分需求 | 输出超过100万行,必须人工拆分任务 | 单SQL直达全量数据 |
| 资源利用率 | 单节点读写计算后的数据 | 支持按需弹性扩容 |
**小结**
新版本定时SQL中,可以大胆使用limit all来返回全量的输出结果了。目前公有云region,定时SQL都已经升级到最新版本。这次升级,不只是一个功能的优化,更是一种对用户需求的回应,它让数据处理更高效和灵活。用户不必再纠结于,是选择定时SQL最多返回100万行结果,还是选择返回所有结果但却可能超过行数限制导致的失败。
千言万语不如一张图,我们将本次定时SQL的优化改造浓缩成了下图,希望能够让你更清楚的理解本次优化改造具体的内容。如果你也在用定时SQL,不妨升级体验一下这个“无惧大数据”输出的新特性吧!