LLM应用观测简述
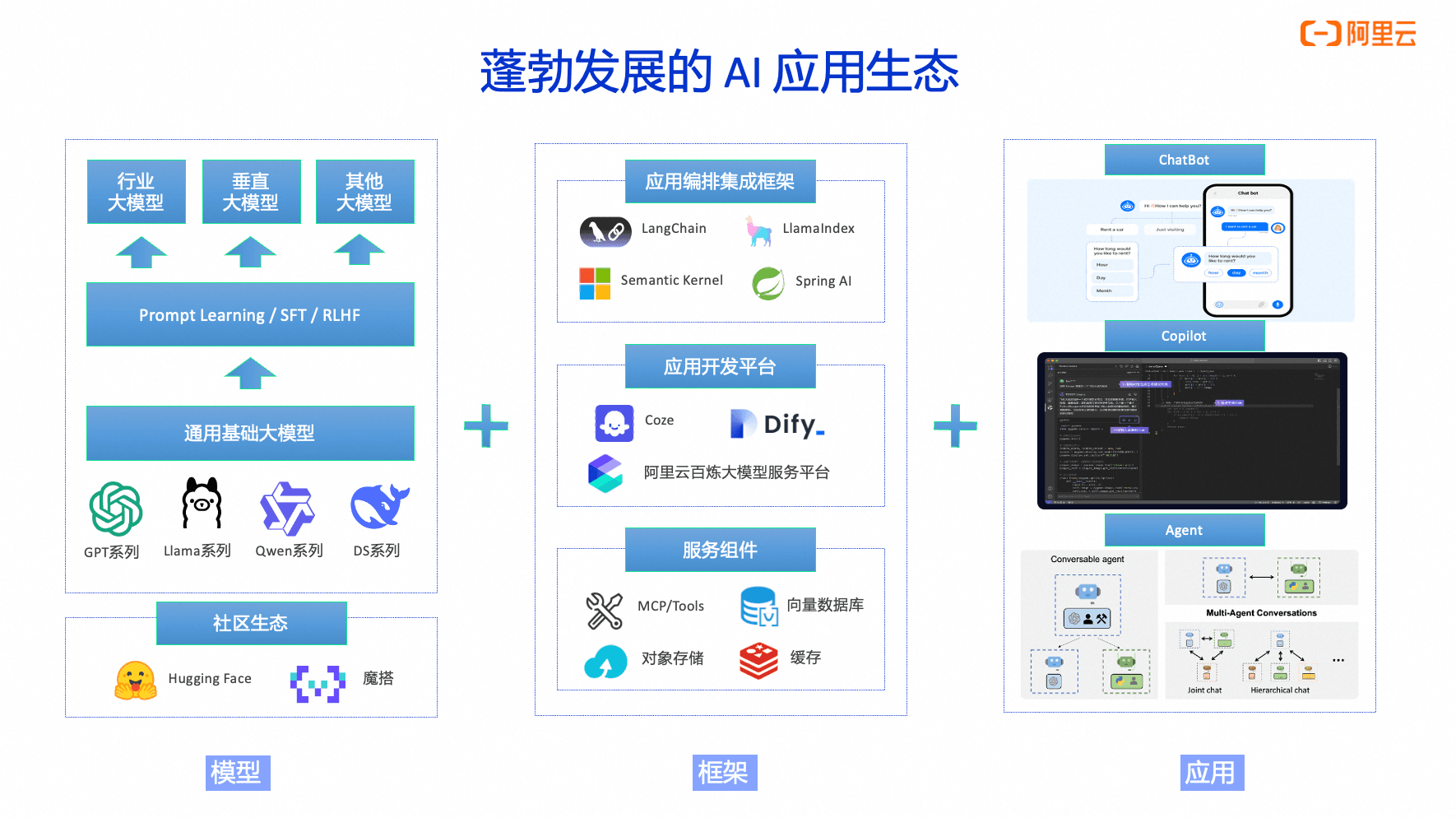
蓬勃发展的AI应用生态
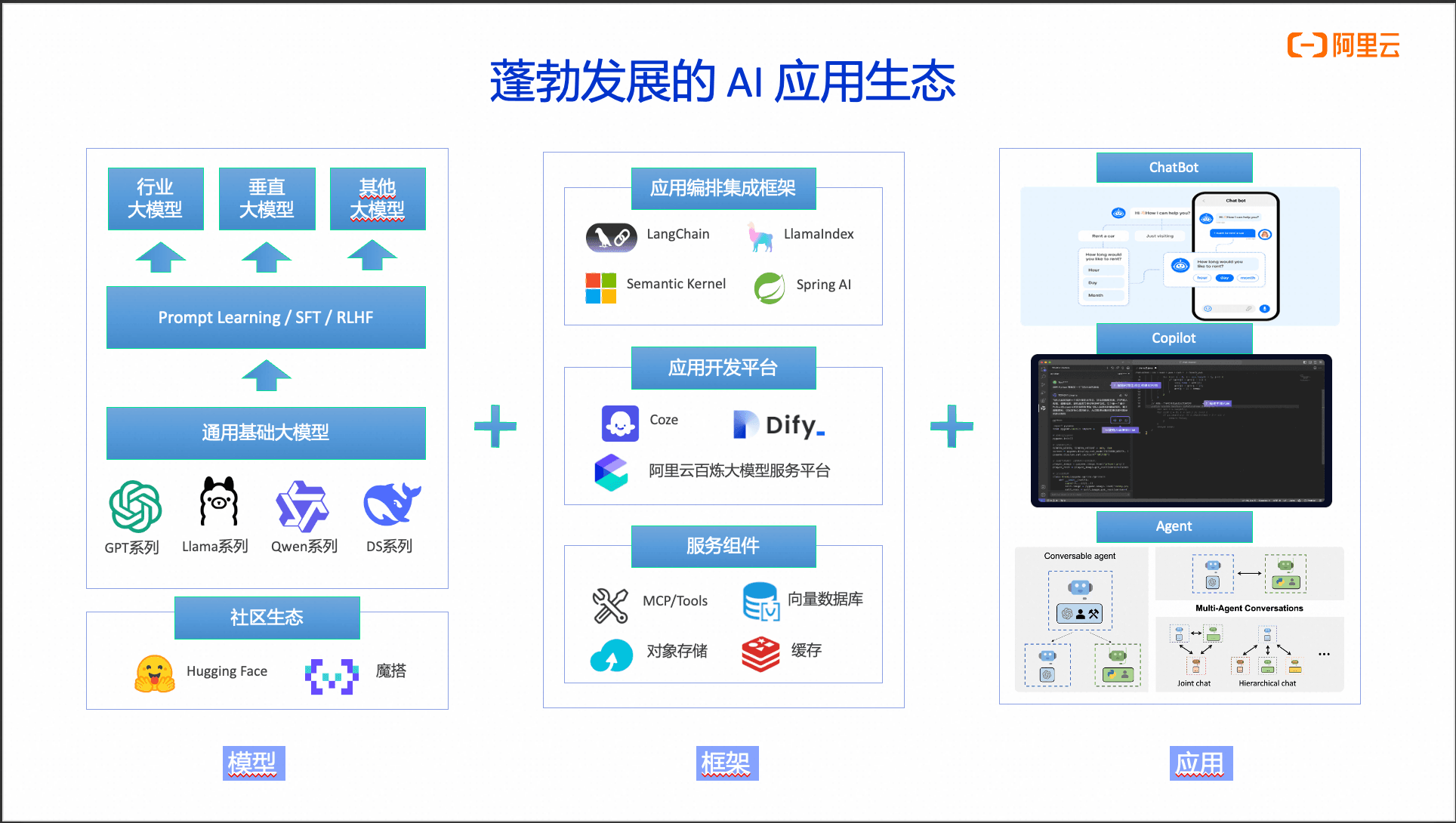
当前人工智能技术正以前所未有的速度重构产业格局,其应用生态体系已形成多维协同的演进态势,具体呈现以下三个维度的突破性发展:
一、基础模型技术实现跨越式发展
以DeepSeek、Qwen为代表的本土大模型在参数规模、推理能力及多模态处理等核心指标上持续突破,通过算法优化与算力升级,正在显著缩小与OpenAI、Anthropic(Claude)等国际头部模型的技术差距。值得关注的是,模型研发已从单纯追求性能指标转向垂直领域专业化发展,形成通用大模型与行业专用模型协同演进的双轨格局。
二、全栈开发框架构建技术底座
在技术实现层面,Python语言仍主导着AI开发生态,LangChain、LlamaIndex等高代码框架持续完善其链式处理与知识库管理能力。随着技术普惠化需求增长,跨语言开发体系加速成熟:Java生态中的Spring AI Alibaba等框架已实现与Python生态的核心功能对齐。与此同时,Dify、Coze等低代码开发平台通过可视化编排与模块化组件,为AI应用开发提供了轻量化解决方案。此类平台特别契合AI应用天然具备的轻量化架构特征,配合MLOps工具链、向量数据库等基础设施支撑体系,构建起完整的开发运维闭环。
三、应用场景呈现多元化发展态势
AI应用形态正经历从单一交互向智能体演化的范式转变:早期以客户服务为导向的聊天机器人已发展为涵盖代码辅助(如GitHub Copilot)、决策支持等复合功能的智能助手系统。当前,基于Agent架构的通用智能体正成为创新焦点,其自主决策、持续学习等能力在金融、医疗、制造等领域催生出诸多创新场景。据Gartner最新预测,到2025年超过70%的企业将部署至少一个智能体应用,标志着AI应用已从概念验证阶段迈入规模化落地新纪元。
AI原生应用的典型架构及可观测诉求
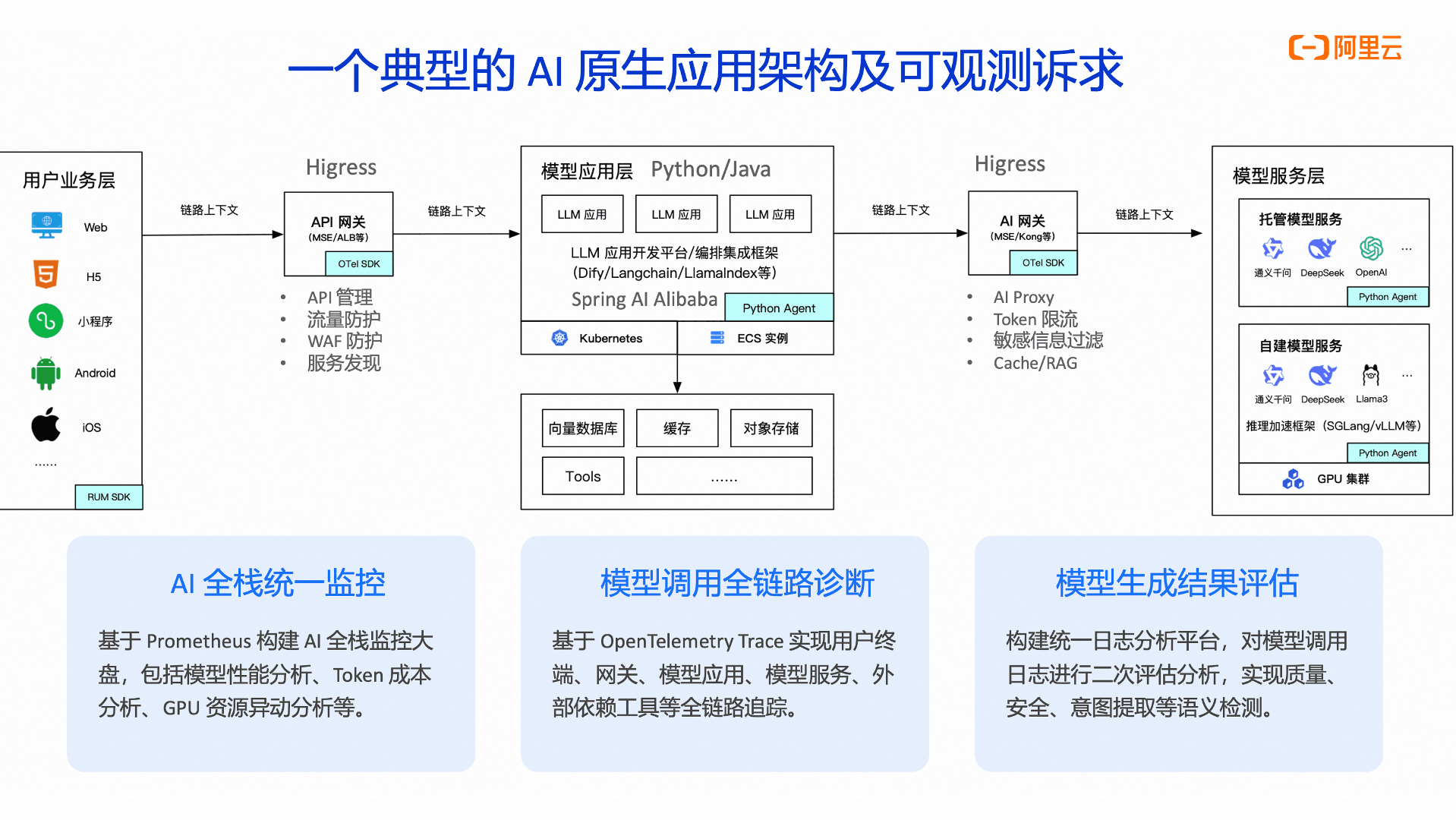
一个典型的AI原生应用的架构如上图所示,主要可以分为三个大板块,流量从用户业务侧流入,用户会从各种端上进行请求,包括浏览器,小程序,Android,IOS。所有流量通常会由一个统一的入口来代理,比如Higress网关,网关会在入口处统一做一些安全防护,流量控制等治理操作。之后经过网关过程的流量会被打到模型应用层,模型应用层中有各种编程语言使用各种编程框架(比如Dify,Langchain,Spring AI Alibaba等)编写的应用程序,这些程序会去调用不同的模型服务(比如托管或者自建的千问,DeepSeek等等)。从模型的高可用以及模型性能对比的层面,我们通常会部署多个模型,并且根据一定的策略在各种模型之间做切换,比如按照模型调用的成本,重要程度,流量策略等进行负载均衡,通常这里用户也会通过一个统一的代理,比如Higress AI网关来实现。
可以看到,整个AI原生应用的执行链路相当之长,在整个执行链路中任何一个节点出现问题都有可能导致业务的不可用。所以首先要解决的是一次调用到底经过了哪些组件,通过调用链把这些组件全部串联起来。要实现全链路的诊断,首先要把这些链路能打通,一个请求出现问题的时候,到底是哪个环节出问题了,是在AI 应用出问题了,还是这个模型内部推理出现了问题,我们需要能够快速定界。
其次,在这么一个复杂的分布式系统中,从单一的维度去观测会让用户置身于信息孤岛中,我们需要构建一个全栈的可观测数据的平台,它能够把所有的这些数据,不仅是链路,还包括指标,例如模型内部的一些 GPU 利用率,数据之间能够很好关联起来,通过关联分析能够去知道到底是应用层出问题,还是模型底层出问题了。
最后我们还需要通过一些模型日志,了解每次调用的输入输出是什么,并利用这些数据做一些评估和分析,来更加准确地验证与评估 AI 应用的质量。
可观测对LLM应用至关重要

LLM应用本身的复杂性引入了非常多的可观测相关的诉求,因此可观测对LLM应用而言是至关重要的,举个例子:Agent 在执行任务的过程中,通常会消耗大量的 token 和时间,在执行过程中的每一步都需要有详细的记录,这就需要完整的可观测能力,能够采集各个阶段的执行情况。包括对模型的调用,工具的使用情况,token 消耗等都有非常明确的需求。另一方面我们支持 MCP 的出现,一个 Agent 在执行的过程中往往需要跟模型进行多轮的交互,最终执行的结果的 token 消耗看起来不多,但往往中间过程实际的消耗大得惊人,甚至有可能陷入无休止的状态,也就是所谓的 MCP Token 黑洞问题。另外,每一次 AI Agent 的修改和发布上线,我们都需要对 Agent 执行的结果进行评估,这相当于对 AI Agent 进行“回归测试”。这些过程都需要大量的可观测数据。因此,从开发测试到运行和运维环节,可观测性都是非常重要的一环。
AI Agent 的复杂性、动态数据流的不确定性以及实时推理需求,使得传统监控手段难以满足需求。AI Agent 的架构和传统微服务有较大的差异,Agent,模型,中间件,牵一发而动全身,但可观测的思路是一致的,也就是我们需要进行全面的端到端的可观测性,包括从端侧,到 AI Agent,到模型内部,通过端到端的全链路可观测,实现 AI Agent 与模型交互过程的全覆盖。LoongSuite 作为开源的可观测性数据采集套件,为 AI Agent 的开发,调试和评估,提供了全方位的覆盖。
LoongSuite AI采集套件介绍
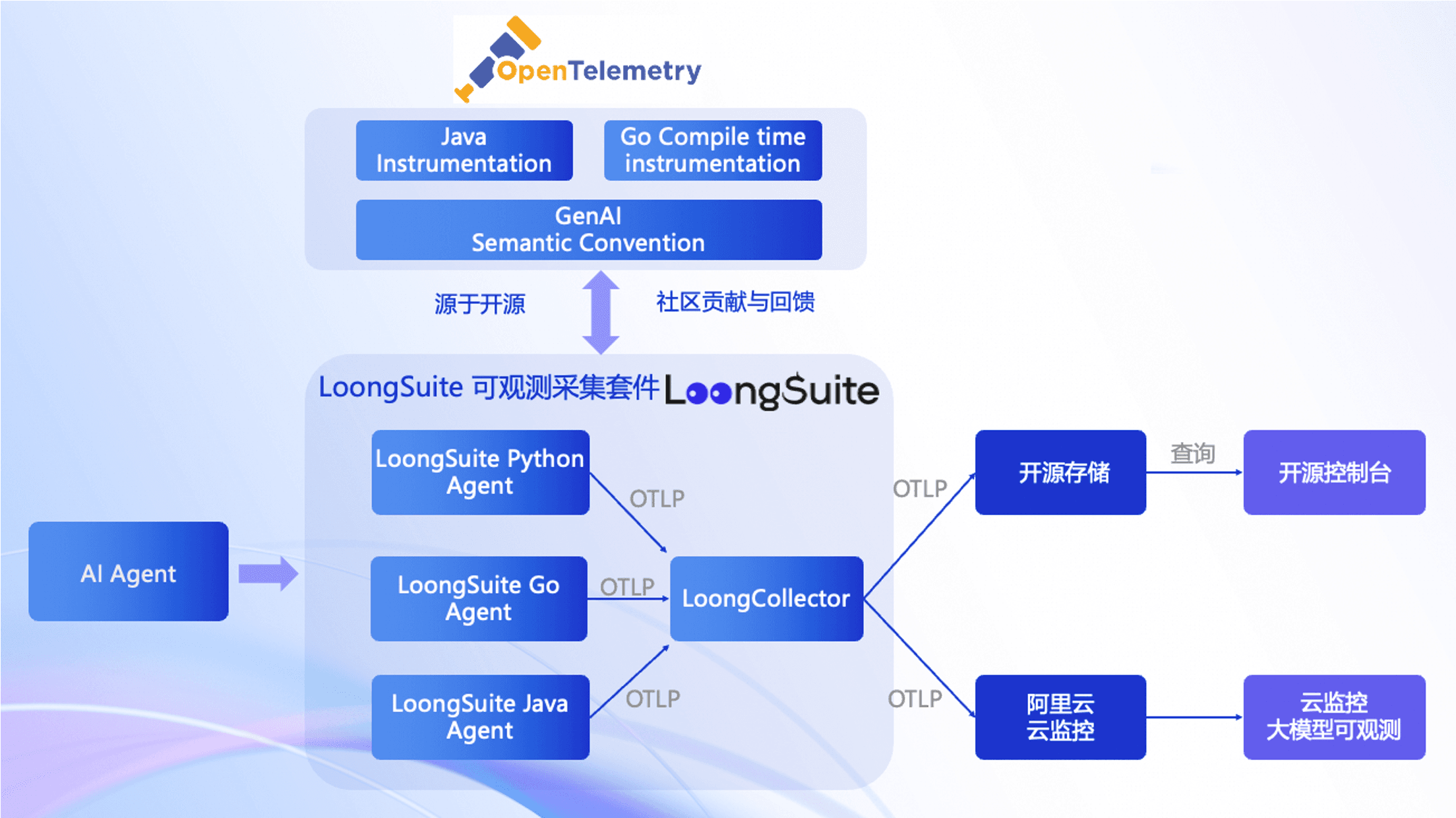
LoongSuite (/lʊŋ swiːt/)(音译 龙-sweet),作为下一代可观测性技术生态的核心载体,核心数据采集引擎实现了主机级探针与进程级插桩的有效结合,进程级探针实现应用内细粒度可观测数据采集,而主机探针则实现了高效灵活的数据处理和数据上报,以及通过 eBPF 等技术实现了进程外数据采集能力。
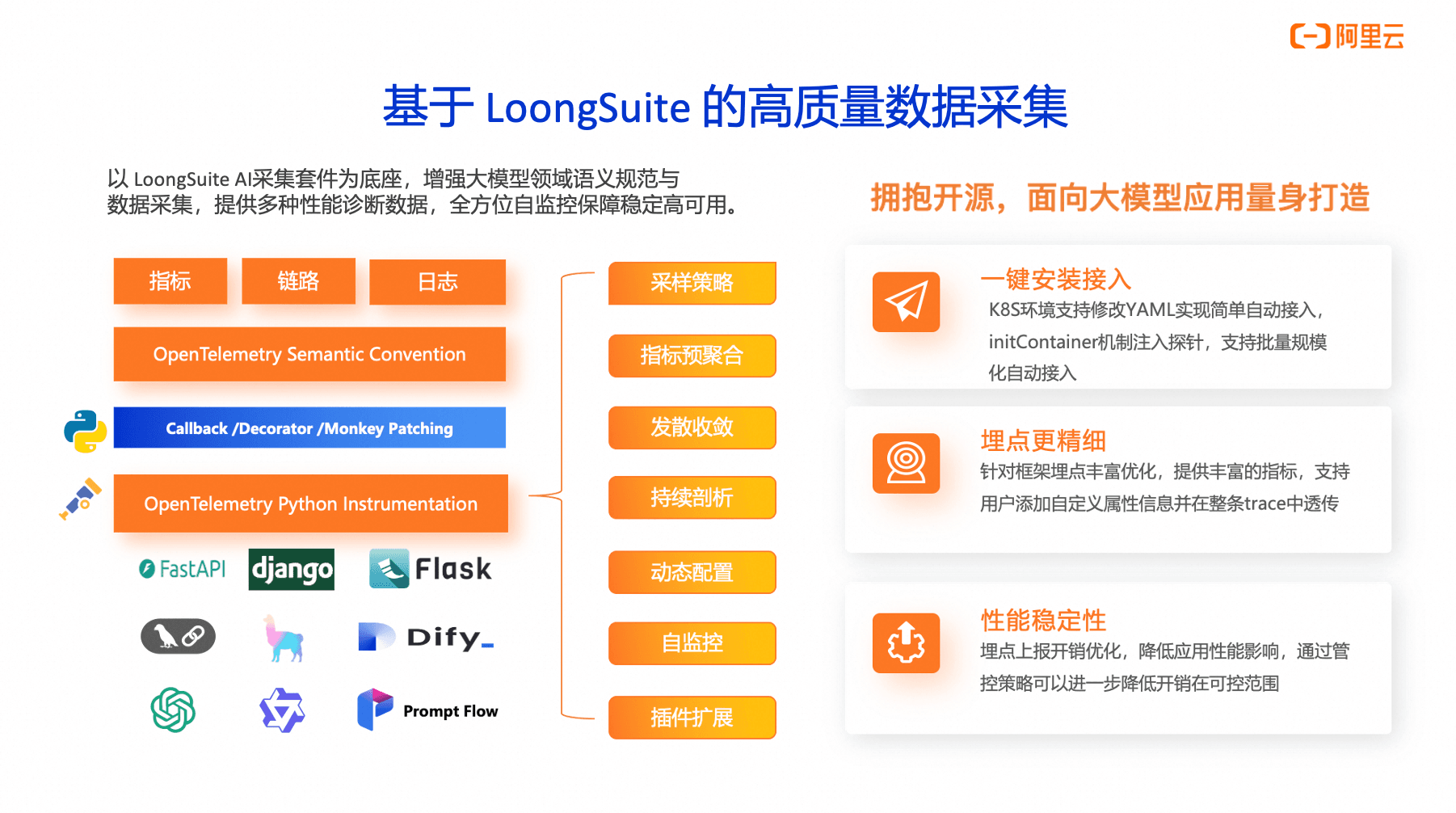
在进程级数据采集层面,LoongSuite 对 Java、Go、Python 等主流编程语言构建企业级观测能力。通过语言特性的深度适配,采集器能够自动捕获函数调用链路、参数传递路径及资源消耗,无需修改业务代码即可实现运行时状态的精准采集。这种无侵入式设计特别适用于动态更新频繁的技术环境,既保障观测数据的完整性,又避免对核心业务逻辑产生干扰。当面对复杂工作流时,系统可自动关联分布式追踪上下文,构建完整的执行路径拓扑。作为核心数据采集引擎,LoongCollector 实现多维度观测数据的统一处理,从原始数据采集到结构化转换,再到智能路由分发,整个流程通过模块化架构实现灵活编排。这种架构使观测数据既可对接开源分析平台实现自主治理,也可无缝衔接托管服务构建云原生观测体系。在技术生态构建方面,阿里云深度参与国际开源标准制定,其核心组件与 OpenTelemetry 等主流标准兼容。
LoongSuite AI采集套件无侵入埋点原理
LoongSuite Python Agent无侵入埋点原理
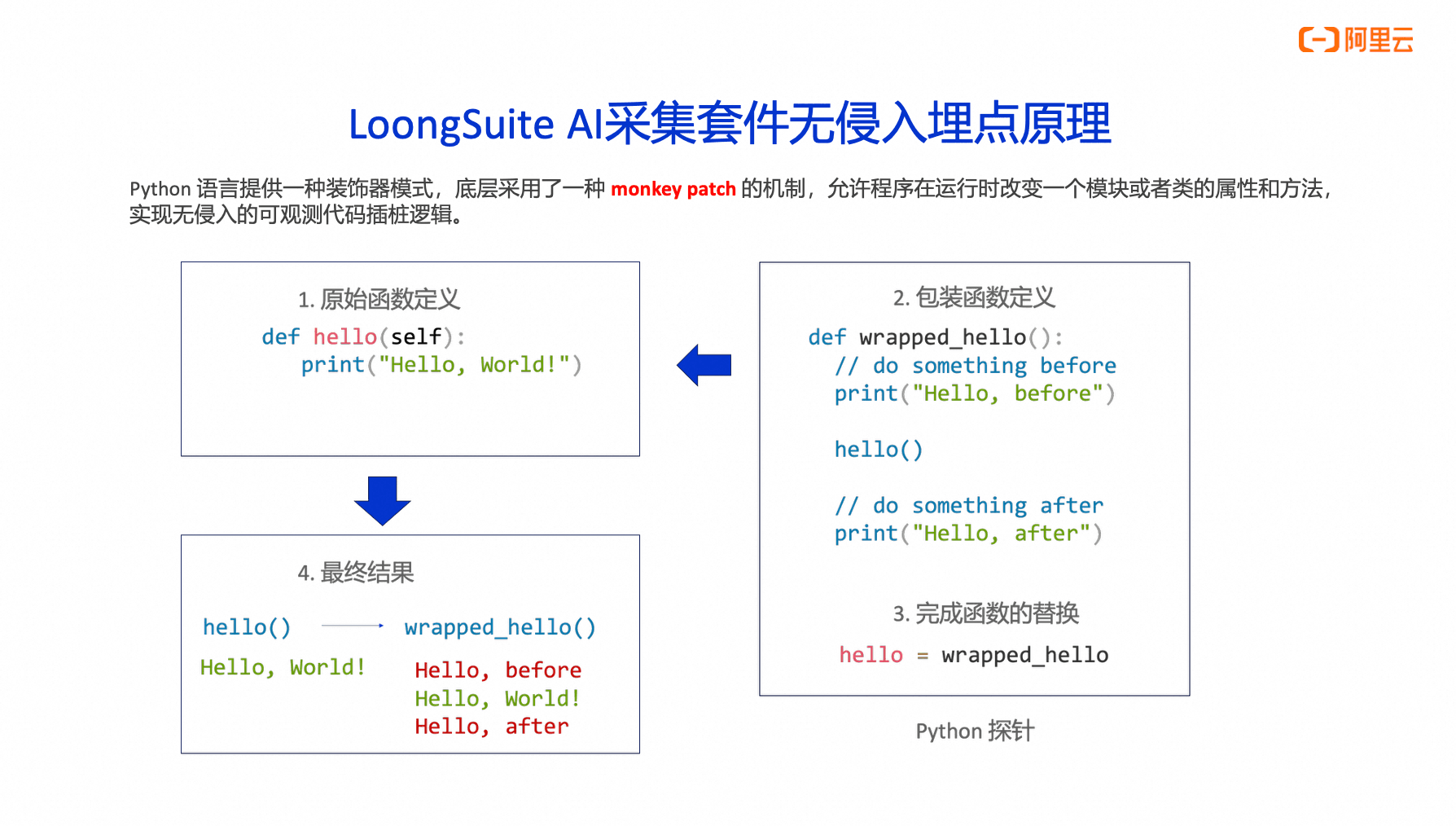
上面是一个 Python 程序的简单的 hello 方法。Python语言提供了一种叫monkey patch 的机制,允许我们的程序在运行的时候去动态地修改一个函数,包括它的属性和方法。所以我们只需要去在它的外层重新定义一个包装的方法,这个方法可以在原始方法执行前后做一些事情。这有点像我们在设计模式中见到过的装饰器模式。
这个 hello 就是原始的方法定义,Python 程序运行的初始化的阶段,可以把原来那个函数的类似于引用给替换掉。这样的话其实实际执行的就是替换后的包装方法。在包装后的方法里面,还会去调原来的那个方法。最后的结果,就像第 4 步看到的,可以实现在原始的方法的前后去插入一些我们想要的一些逻辑。然后通过这种方式,我们就能够实现在用户的代码不修改的情况下去采集各种数据。
LoongSuite Go Agent无侵入埋点原理
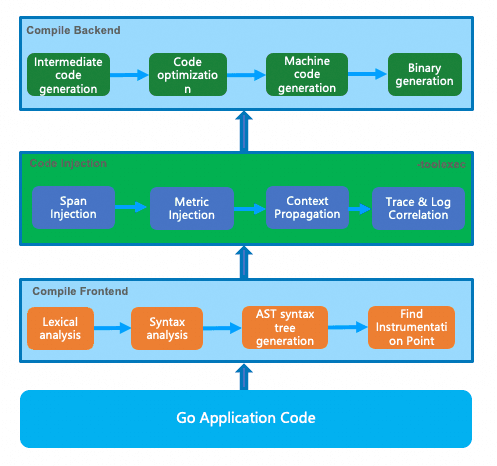
LoongSuite Go Agent 前身是 alibaba/opentelemetry-go-auto-instrumentation 项目,通过无侵入编译时插桩的技术,对 Go 语言应用提供无侵入的可观测数据采集能力,Go 应用的编译流程如下:
首先编译器前端会对源代码进行词法语法相关的分析,把源代码解析成为一棵抽象语法树,之后在编译器后端进行代码的优化和机器码的生成,从而编译出一个可执行的二进制文件。
不同于 Java 语言可以使用字节码增加技术实现动态的 Agent 挂载,Go 编译后的产物是一个可以直接运行的二进制文件,为了实现无侵入监控能力,通过 Go 提供的go toolexec的能力,我们可以轻松地在编译器的前端和后端之间插入一个中间层,在中间层对编译器前端生成的抽象语法树做任意的修改,从而在编译时完成监控埋点的注入:
通过 AST 语法树分析,查找到监控的埋点,根据提前定义好的埋点规则,在编译前插入需要的监控代码(如Span的创建、指标统计、上下文的透传等),这个方案不需要修改任何代码,只需要修改编译命令,同时由于经过了完整的 Go 编译流程,该方案自然地支持 Go 的所有运行场景,同时避免了一些不可预料的错误。
在 LoongSuite AI采集套件中提供了针对微服务应用完整的支持,包括常见的框架的埋点,如http、db、redis、mq等多个插件的支持,另一方面,针对各种语言编写的AI Agent,也已经提供了常见AI Agent 开发框架的支持,例如LangChain,MCP,Dify等,能快速查看到大模型调用的输入输出、耗时、消耗的Token数量等等,帮助用户通过这些数据能更好的优化 Prompt,提高大模型的访问效率,减少Token的消耗。
相比其他开源的探针,LoongSuite AI采集套件有着更丰富的埋点,更全面的特性支持以及语言支持,为智能化运维体系建设提供了坚实的数据底座。
LoongSuite AI采集套件Dify观测实践
Dify简介
Dify 是一款开源的大语言模型(LLM)应用开发平台,也是现阶段国内最火热的LLM应用开发平台之一。它融合了后端即服务(Backend as Service)和 LLMOps 的理念,使开发者可以快速搭建生产级的生成式 AI 应用。即使你是非技术人员,也能参与到 AI 应用的定义和数据运营过程中。由于 Dify 内置了构建 LLM 应用所需的关键技术栈,包括对数百个模型的支持、直观的 Prompt 编排界面、高质量的 RAG 引擎、稳健的 Agent 框架、灵活的工作流,并同时提供了一套易用的界面和 API。这为开发者节省了许多重复造轮子的时间,使其可以专注在创新和业务需求上。
Dify架构一览
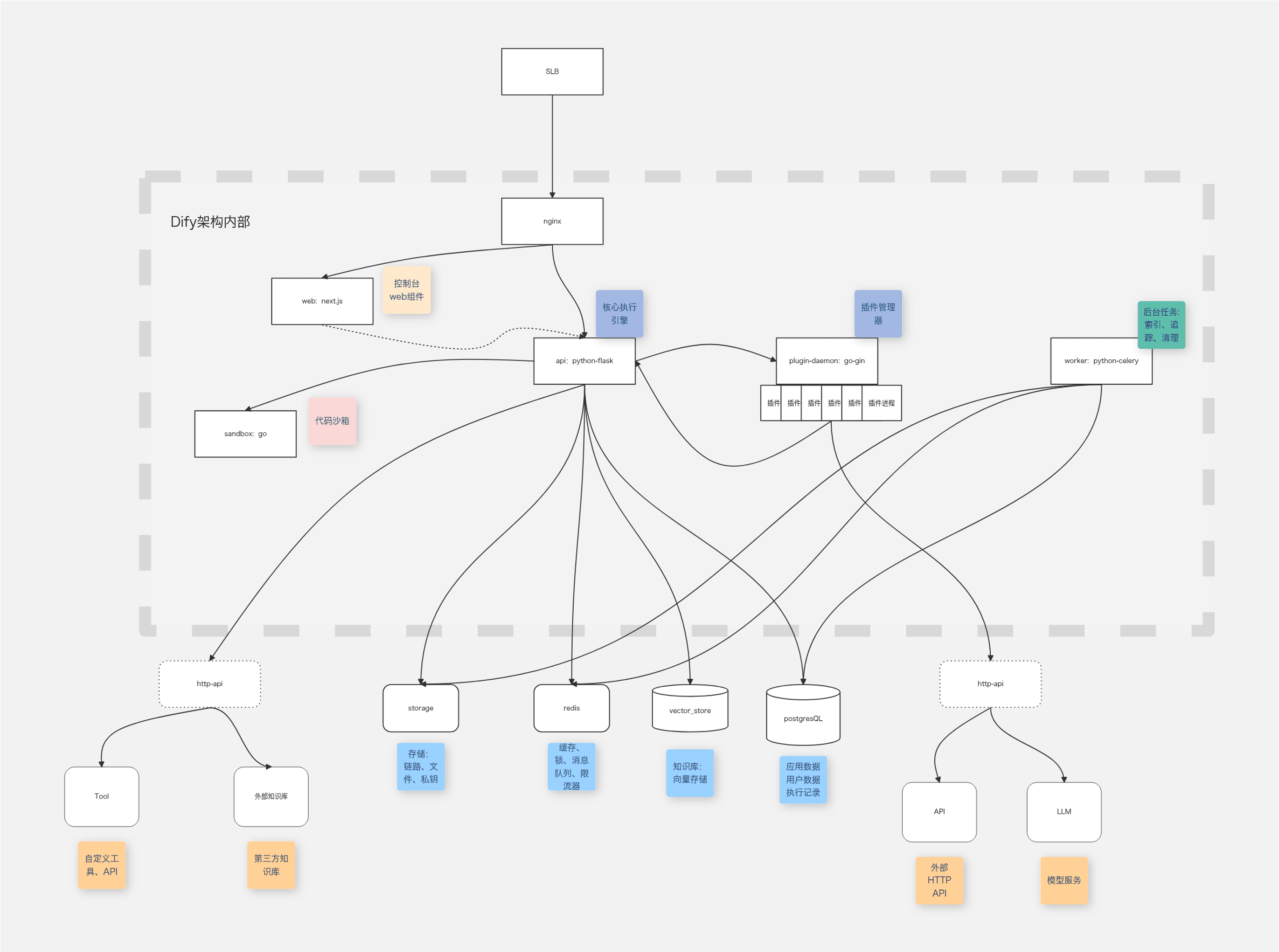
用户通过浏览器访问 Dify,本地的Nginx服务作为统一入口,接收所有HTTP请求。Nginx
根据请求路径将流量分别转发:静态页面和前端接口由 WebUI 前端服务提供,负责呈现管理控制台界面。后端 API请求由DifyAPI 服务(Flask应用)处理,包括应用配置、聊天会话、数据管理等所有业务接口。Dify API 服务在生命周期内会与多个内部组件交互:
- PostgreSQL 数据库:保存持久化的数据,如应用配置、对话记录、多租户信息等。API
通过SQLAlchemy访问数据库。 - Redis 缓存/队列:承担双重角色,一方面缓存临时数据和会话状态,提高读写性能;另一方面作为
Celery的消息队列,存放异步任务(比如
embedding,可观测数据上传)。 - 对象存储:用于保存上传的文件、知识库文档、以及保存密钥所需的证书等内容。可以是
local file system,阿里云oss等。
在 1.0版本后,最显著的变化是引入了插件架构,dify-plugin-daemon的功能有:
1、负责根据参数启动、管理plugin生命周期,负责对启动插件的调用(包括对大模型的调用,使用SSE协议),是一个有状态服务。
2、负责所有插件的输入输出。
2、可以动态的加载plugin、可以本地、远程连接plugin(可以调试)。
3、可以反向调用Dify内部服务,
包括模型(Models)和工具(Tools)都被迁移至插件体系,并新增了代理策略(Agent Strategies)、扩展(Extensions)和捆绑包(Bundles)等插件类型。这种架构使得模型和工具与核心平台解耦,实现了独立的开发和维护 。同时,Dify推出了插件市场(Dify Marketplace),方便用户发现和管理各种插件。
Dify观测实战
注:本节中的实战内容部分能力在LoongSuite开源版本还未完全就绪,这里主要使用LoongSuite的商业化版本进行演示,后续演示包含的能力将会陆续开源,敬请期待。
一键拉起Dify套件
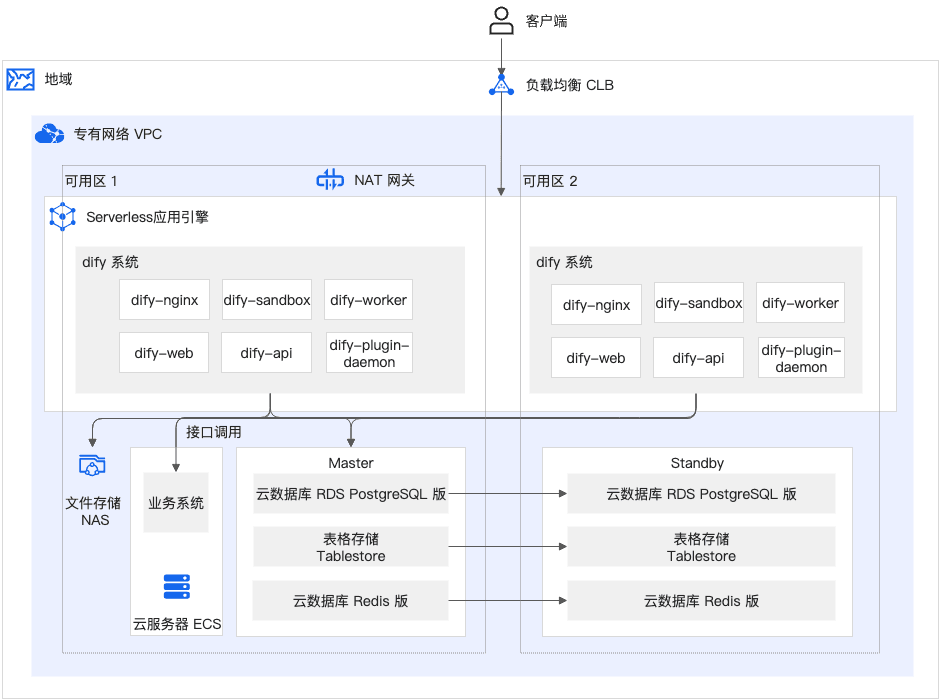
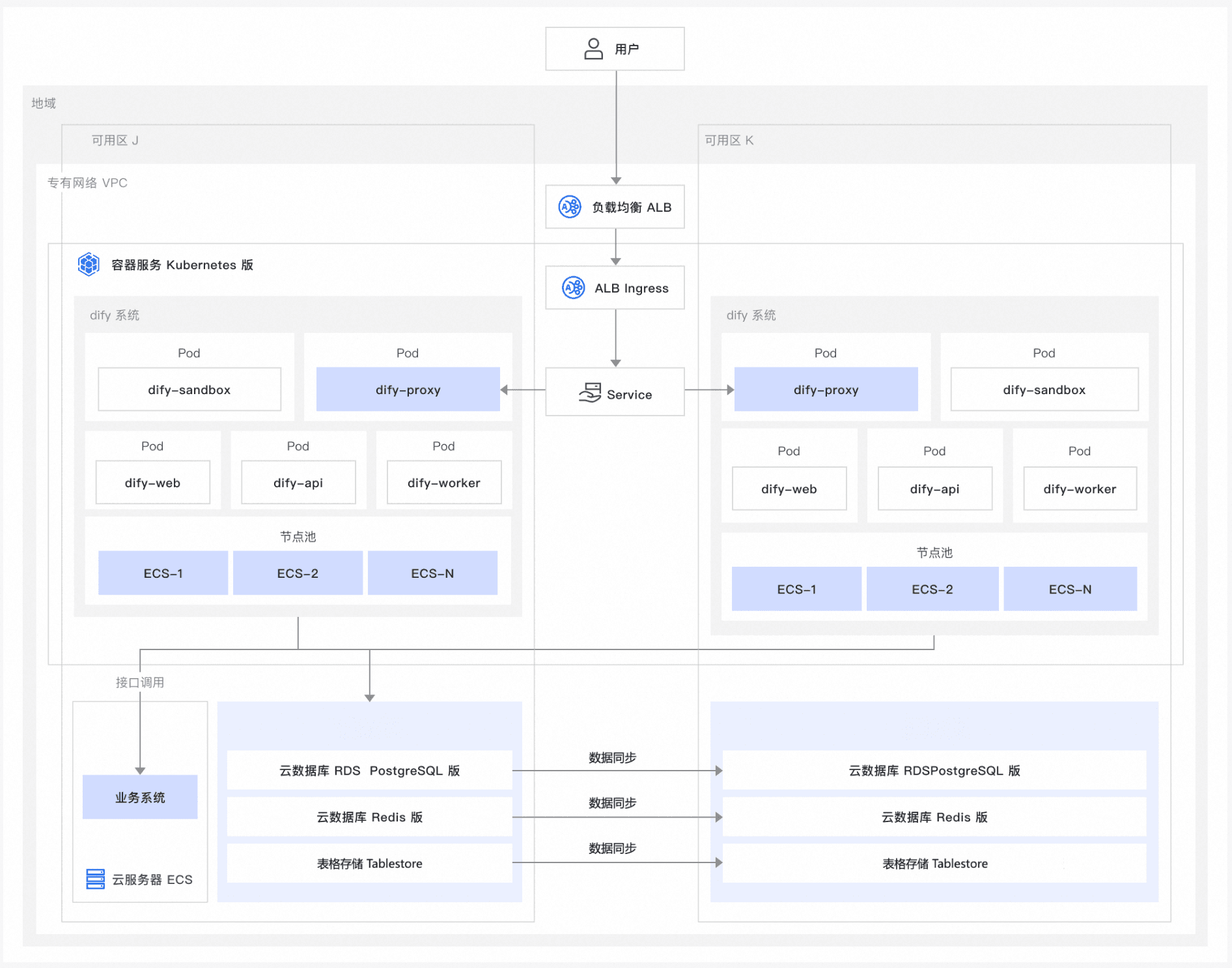
第一步,您可以根据教程在阿里云SAE或者ACK上对Dify进行一键部署。
无侵入接入dify-api
首先按照文档安装ack-onepilot组件,并按照文档中的说明在dify-api的deployment上添加相关开关以开启dify-api的可观测能力:
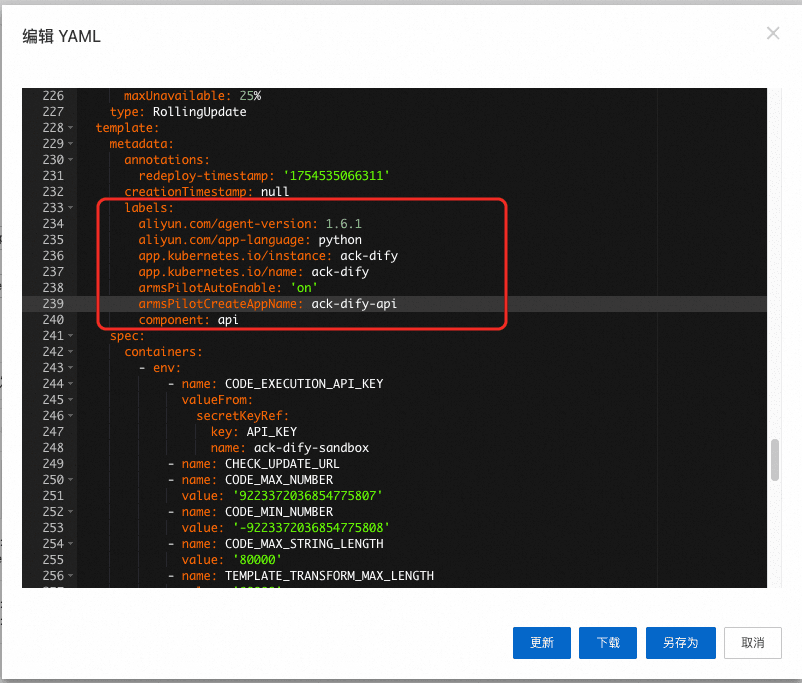
只需要额外添加几个label,就可以立马将dify-api组件接入到LoongSuite的可观测体系里。
无侵入接入dify-daemon
dify-daemon是由Golang编写的组件,我们需要在编译时该组件进行增强,首先我们需要把dify-daemon项目clone到本地。
之后,按照文档对dify-daemon的dockerfile文件进行修改:
FROM golang:1.23-alpine AS builder
ARG VERSION=unknown
# copy project
COPY . /app
# set working directory
WORKDIR /app
# using goproxy if you have network issues
# ENV GOPROXY=https://goproxy.cn,direct
# build
# 添加编译前缀以获取无侵入的可观测能力
RUN chmod 777 ./aliyun-go-agent-linux-amd64 && ./aliyun-go-agent-linux-amd64 go build \
-ldflags "\
-X 'github.com/langgenius/dify-plugin-daemon/internal/manifest.VersionX=${VERSION}' \
-X 'github.com/langgenius/dify-plugin-daemon/internal/manifest.BuildTimeX=$(date -u +%Y-%m-%dT%H:%M:%S%z)'" \
-o /app/main cmd/server/main.go
# copy entrypoint.sh
COPY entrypoint.sh /app/entrypoint.sh
RUN chmod +x /app/entrypoint.sh
FROM ubuntu:24.04
WORKDIR /app
# check build args
ARG PLATFORM=local
# Install python3.12 if PLATFORM is local
RUN apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y curl python3.12 python3.12-venv python3.12-dev python3-pip ffmpeg build-essential \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/* \
&& update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.12 1;
# preload tiktoken
ENV TIKTOKEN_CACHE_DIR=/app/.tiktoken
# Install dify_plugin to speedup the environment setup, test uv and preload tiktoken
RUN mv /usr/lib/python3.12/EXTERNALLY-MANAGED /usr/lib/python3.12/EXTERNALLY-MANAGED.bk \
&& python3 -m pip install uv \
&& uv pip install --system dify_plugin \
&& python3 -c "from uv._find_uv import find_uv_bin;print(find_uv_bin());" \
&& python3 -c "import tiktoken; encodings = ['o200k_base', 'cl100k_base', 'p50k_base', 'r50k_base', 'p50k_edit', 'gpt2']; [tiktoken.get_encoding(encoding).special_tokens_set for encoding in encodings]"
ENV UV_PATH=/usr/local/bin/uv
ENV PLATFORM=$PLATFORM
ENV GIN_MODE=release
COPY --from=builder /app/main /app/entrypoint.sh /app/
# run the server, using sh as the entrypoint to avoid process being the root process
# and using bash to recycle resources
CMD ["/bin/bash", "-c", "/app/entrypoint.sh"]
之后,就可以在dify-daemon项目的根目录通过该Dockerfile进行dify-daemon镜像的构建:
docker build -t ${实际的镜像名} -f docker/local.dockerfile .并将您运行的dify-daemon组件的镜像替换为使用LoongSuite AI采集套件进行无侵入编译时增强后的镜像。
全链路观测
最后,我们可以在Dify的控制台上配置一个简单的聊天应用,并通过这个简单的聊天应用对后端大模型进行对话:
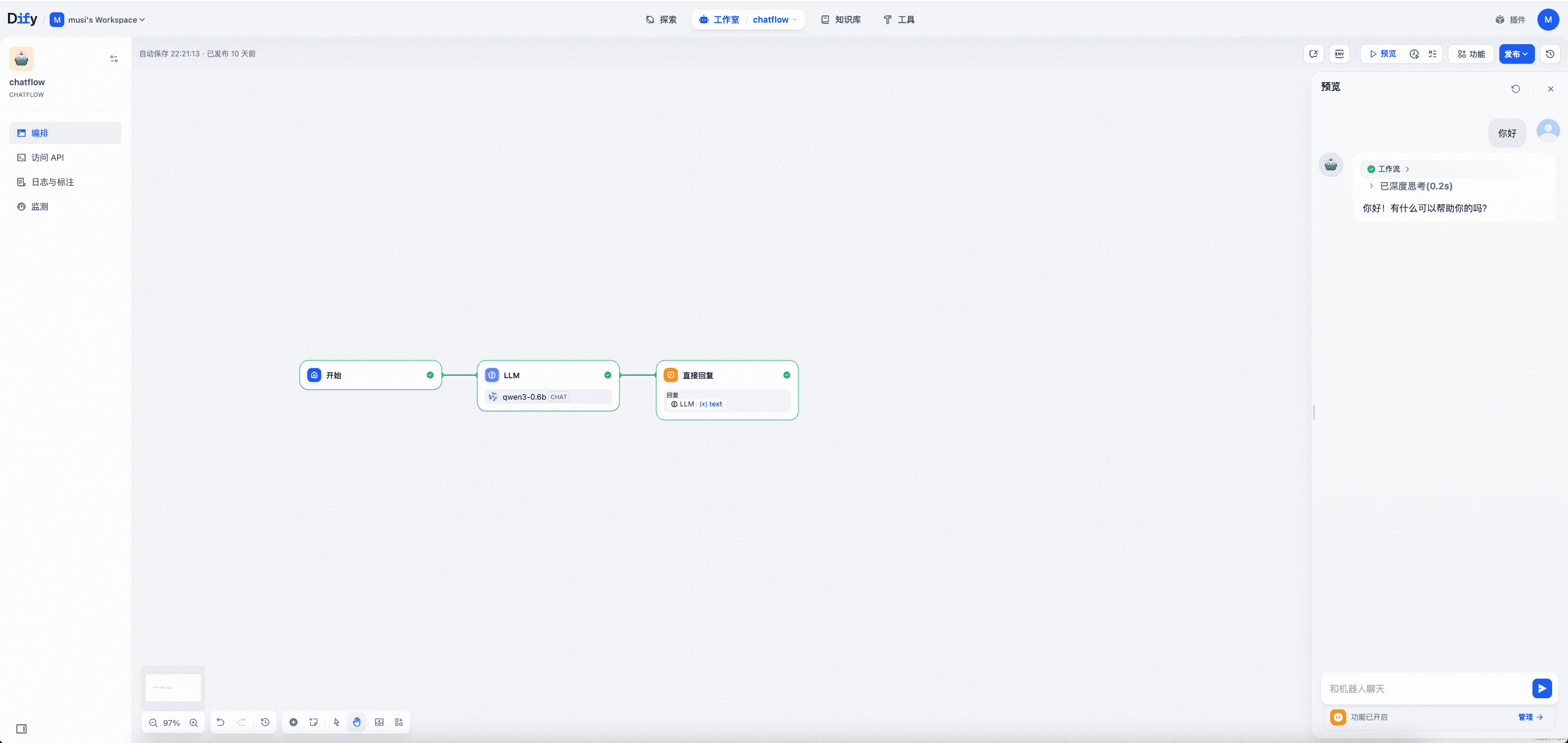
之后,我们可以在界面上同时看到用Python语言编写的dify-api应用以及用Golang语言编写的dify-plugin-daemon组件的监控数据。
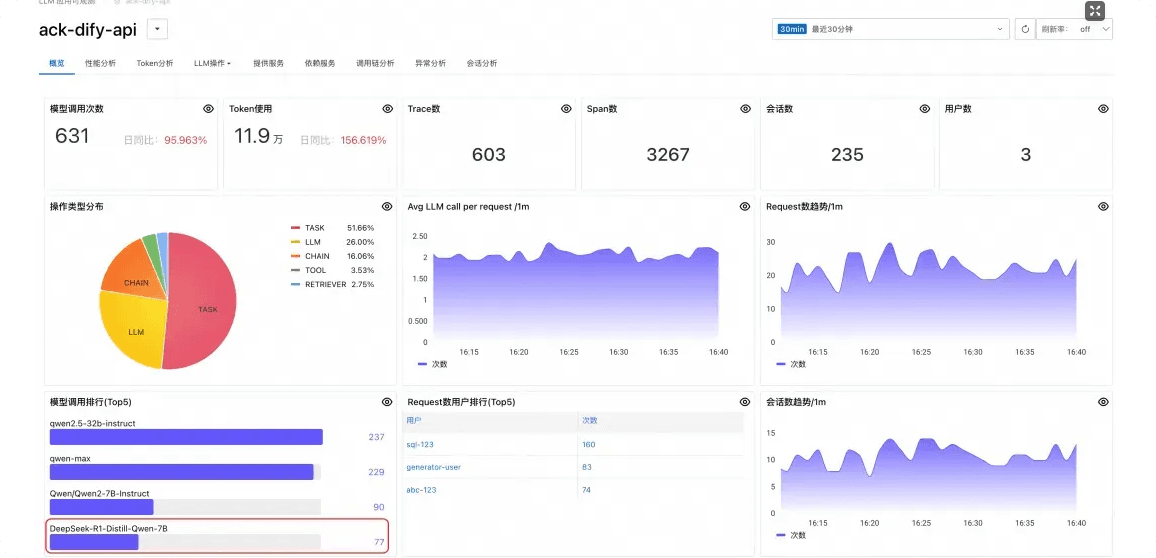
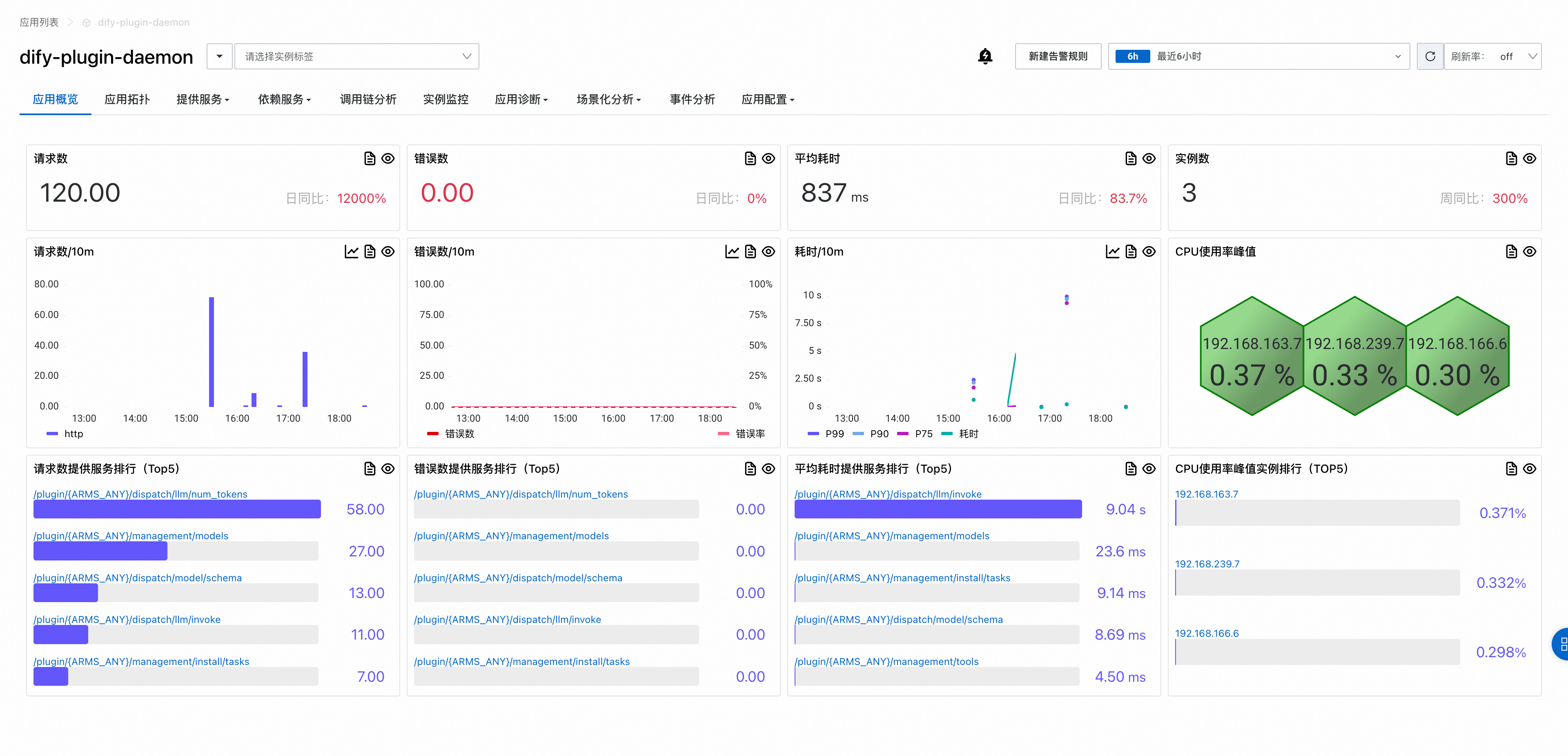
并且dify-api应用与dify-plugin-daemon组件之间的调用链可以成功串联,说明LoongSuite AI采集套件可以对Dify进行全链路的可观测。
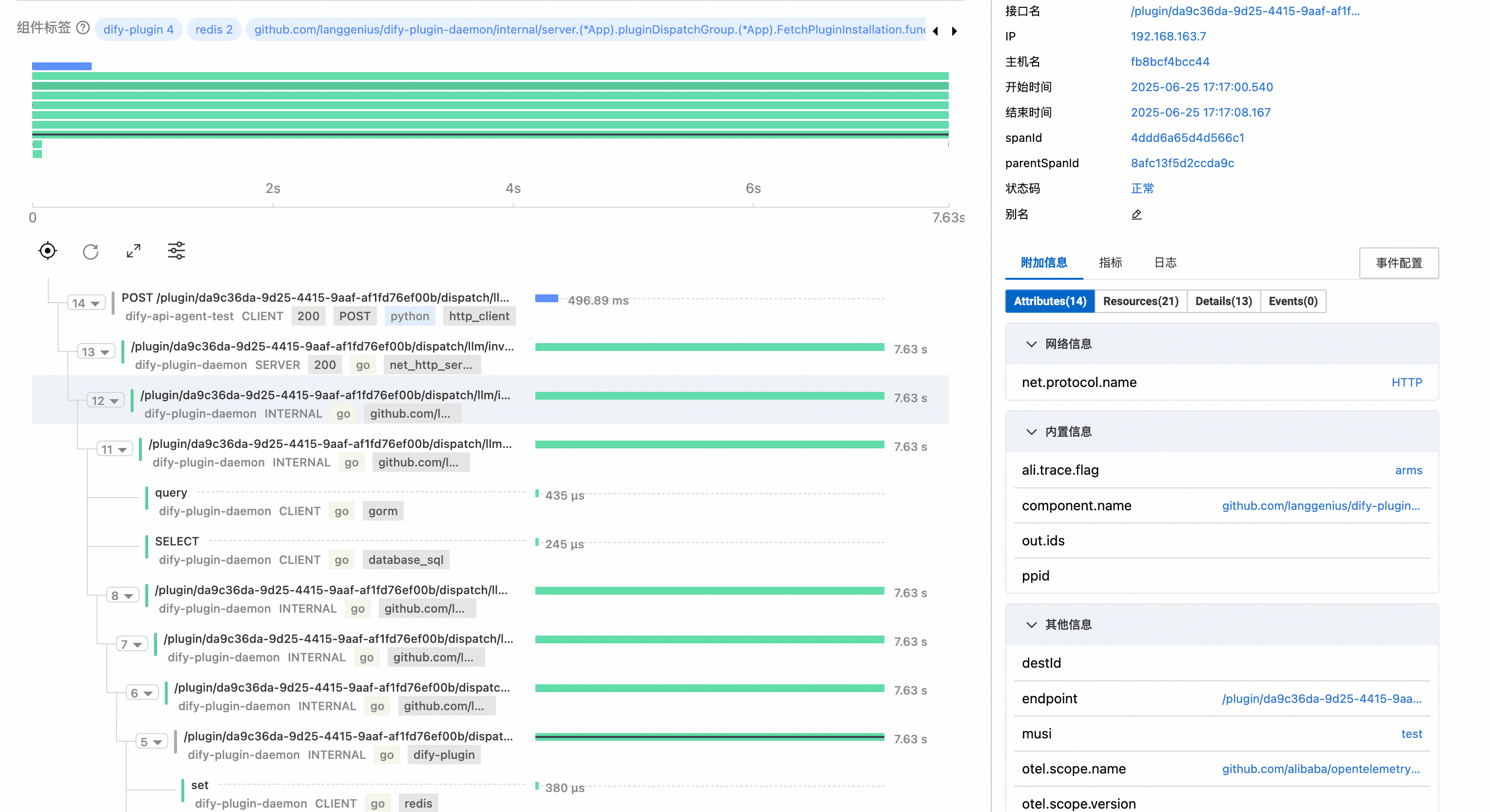
Dify可观测总结
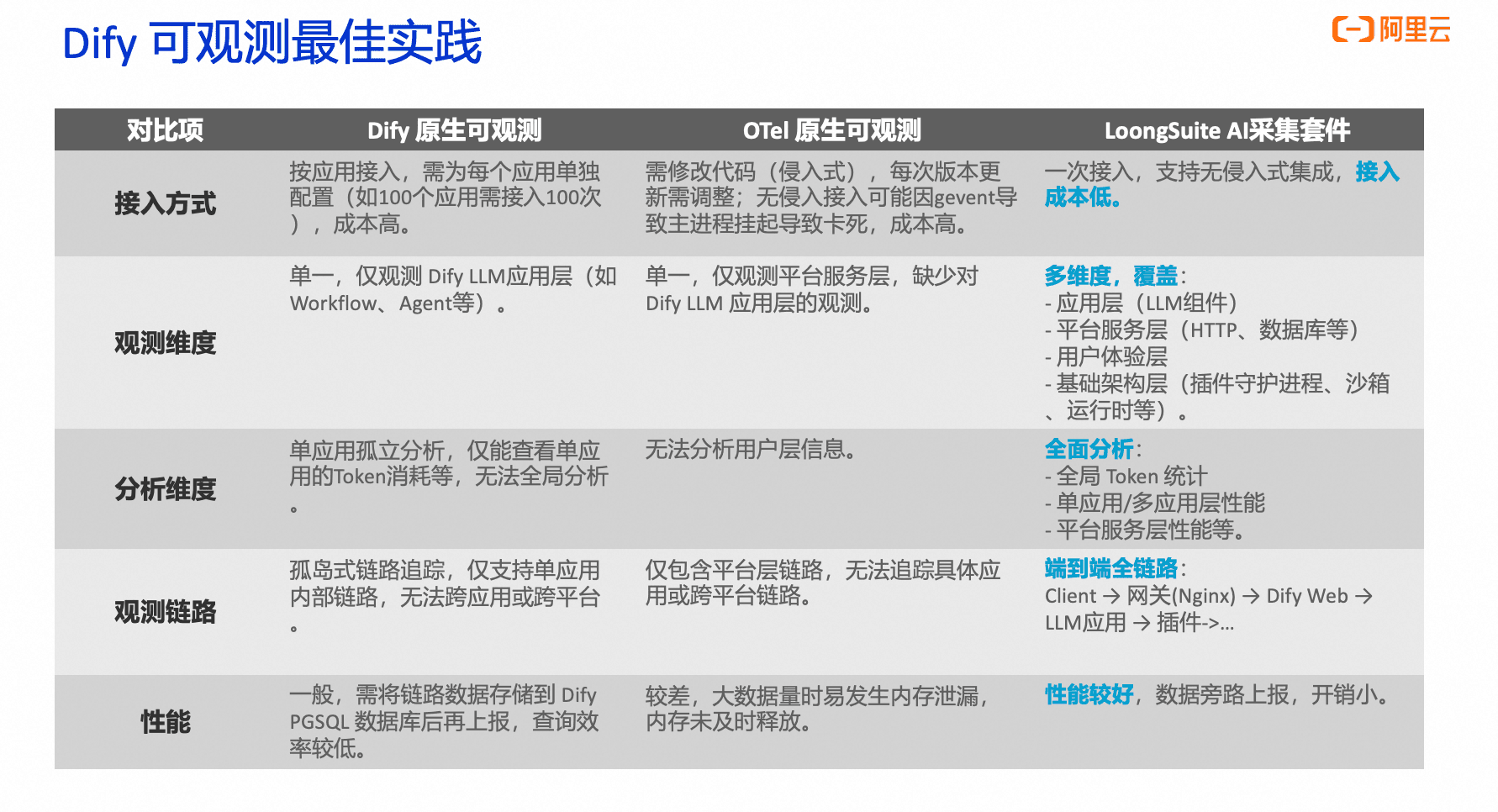
总的来说,LoongSuite AI采集套件相比其他的Dify观测方案有着更加全面的端到端链路追踪,解决了 Dify 原生仅能看“孤岛式”内部链路、OTel 仅能看平台链路的缺口。并且相比之下有着更低的接入成本,仅需一次接入即可对所有应用生效,支持无侵入式集成,无需为每个 LLM 应用单独改造,同时不受 gevent 等运行时限制,后期升级维护成本低。通过以上优势,LoongSuite Agent 能够为 Dify 提供“一次接入、全局可观测”的体验,并补齐了原生方案在多维观测、全局分析及端到端链路追踪上的不足。
未来展望

未来社区将主要继续投入在LLM相关的全栈可观测能力建设上,包括模型侧推理的可观测能力(例如有名的推理加速引起vLLM以及sglang等),GPU上的Profiling能力,以及更多大模型相关的插件支持(包括Google adk, a2a等特性的支持)。

最后,欢迎大家扫描上面的二维码加入LoongSuite社区!